Pandas: Select first N or last N columns of DataFrame
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Pandas: Select first N columns of DataFrame
- Pandas: Select last N columns of DataFrame
- Exclude the last N columns from a DataFrame
- Select the Last N columns of a DataFrame using DataFrame.columns
# Pandas: Select first N columns of DataFrame
Use the DataFrame.iloc integer-based indexer to select the first N columns
of a DataFrame in Pandas.
You can specify the n value after the comma, in the expression.
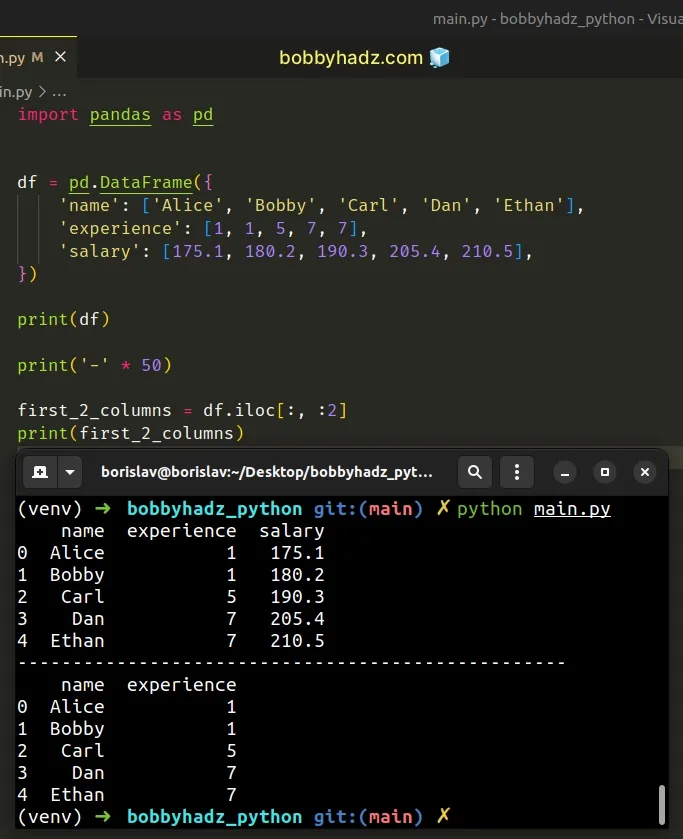
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) first_2_columns = df.iloc[:, :2] print(first_2_columns)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 1 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 7 210.5 -------------------------------------------------- name experience 0 Alice 1 1 Bobby 1 2 Carl 5 3 Dan 7 4 Ethan 7
The DataFrame.loc indexer is used for selection by position (index).
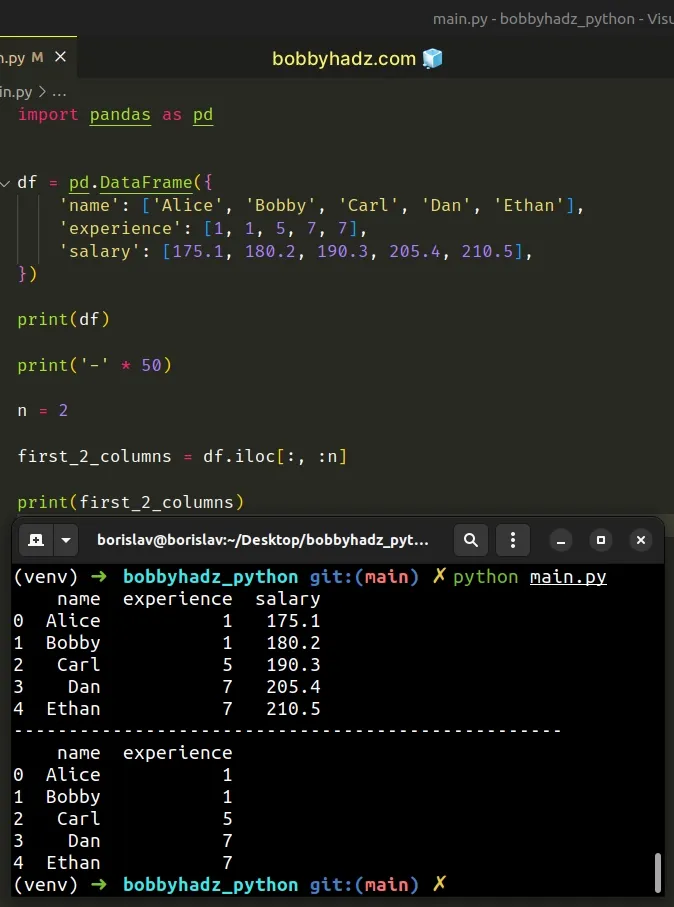
We specified the n value after the comma in the expression.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) n = 2 first_2_columns = df.iloc[:, :n] # name experience # 0 Alice 1 # 1 Bobby 1 # 2 Carl 5 # 3 Dan 7 # 4 Ethan 7 print(first_2_columns)
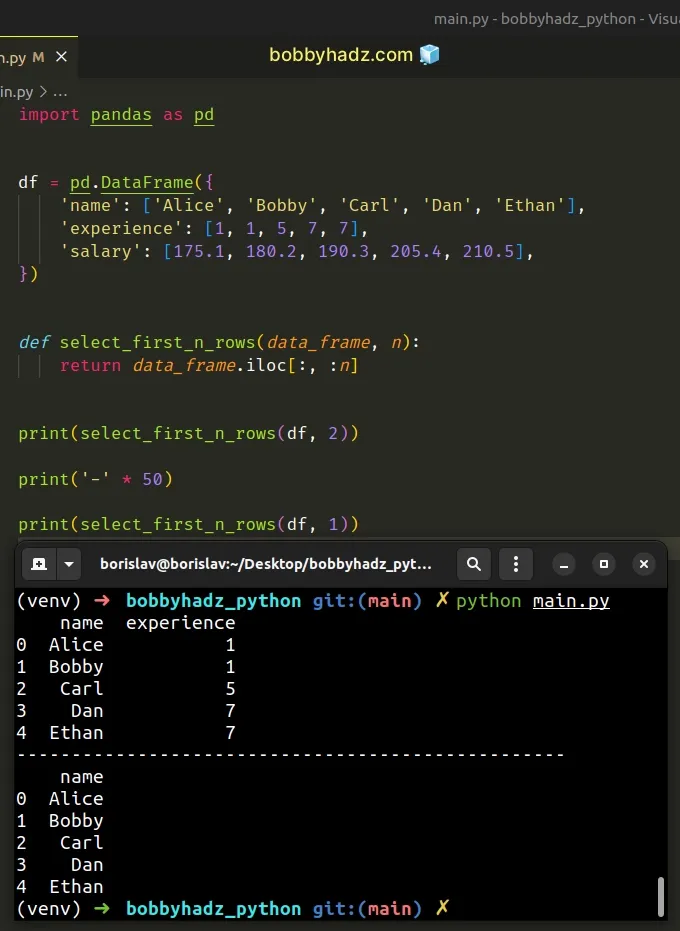
If you have to do this often, define a reusable function.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) def select_first_n_rows(data_frame, n): return data_frame.iloc[:, :n] print(select_first_n_rows(df, 2)) print('-' * 50) print(select_first_n_rows(df, 1))
Here is the output of running the code sample.
name experience 0 Alice 1 1 Bobby 1 2 Carl 5 3 Dan 7 4 Ethan 7 -------------------------------------------------- name 0 Alice 1 Bobby 2 Carl 3 Dan 4 Ethan
# Pandas: Select last N columns of DataFrame
You can also use the DataFrame.iloc
position-based indexer to select the last N columns of a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) last_2_columns = df.iloc[:, -2:] # experience salary # 0 1 175.1 # 1 1 180.2 # 2 5 190.3 # 3 7 205.4 # 4 7 210.5 print(last_2_columns)
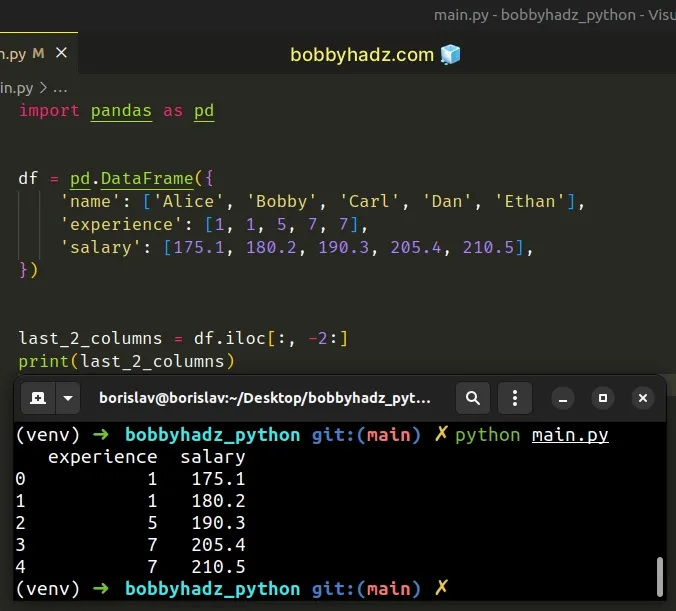
The code sample selects the last 2 columns of the DataFrame.
Notice that we used -n between the square brackets.
If you have to do this often, define a reusable function.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) def last_n_columns(data_frame, n): return data_frame.iloc[:, -n:] print(last_n_columns(df, 2)) print('-' * 50) print(last_n_columns(df, 1))
Running the code sample produces the following output.
experience salary 0 1 175.1 1 1 180.2 2 5 190.3 3 7 205.4 4 7 210.5 -------------------------------------------------- salary 0 175.1 1 180.2 2 190.3 3 205.4 4 210.5
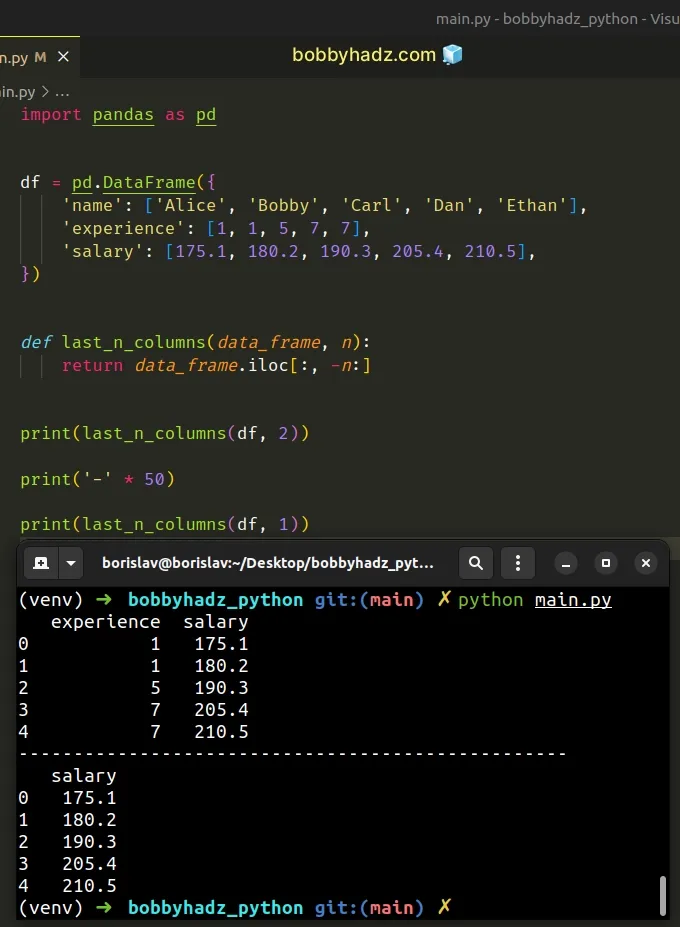
The function takes the DataFrame and n as parameters and returns the last
n columns of the DataFrame.
# Exclude the last N columns from a DataFrame
A similar approach can be used to exclude the last N columns from a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) exclude_last_2_columns = df.iloc[:, :-2] print(exclude_last_2_columns)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 1 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 7 210.5 -------------------------------------------------- name 0 Alice 1 Bobby 2 Carl 3 Dan 4 Ethan
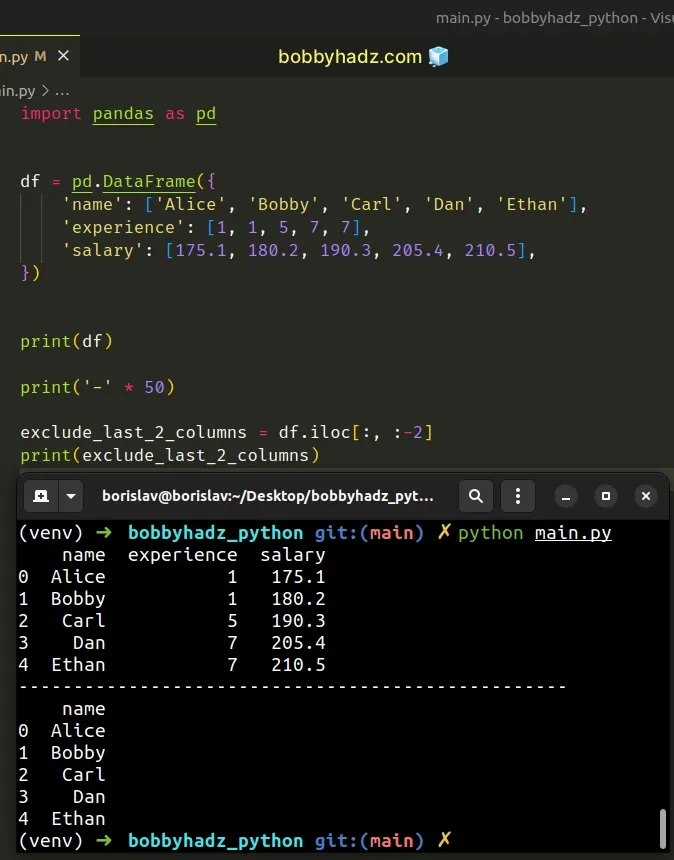
We excluded the last 2 columns from the DataFrame.
If you have to do this often, define a reusable function.
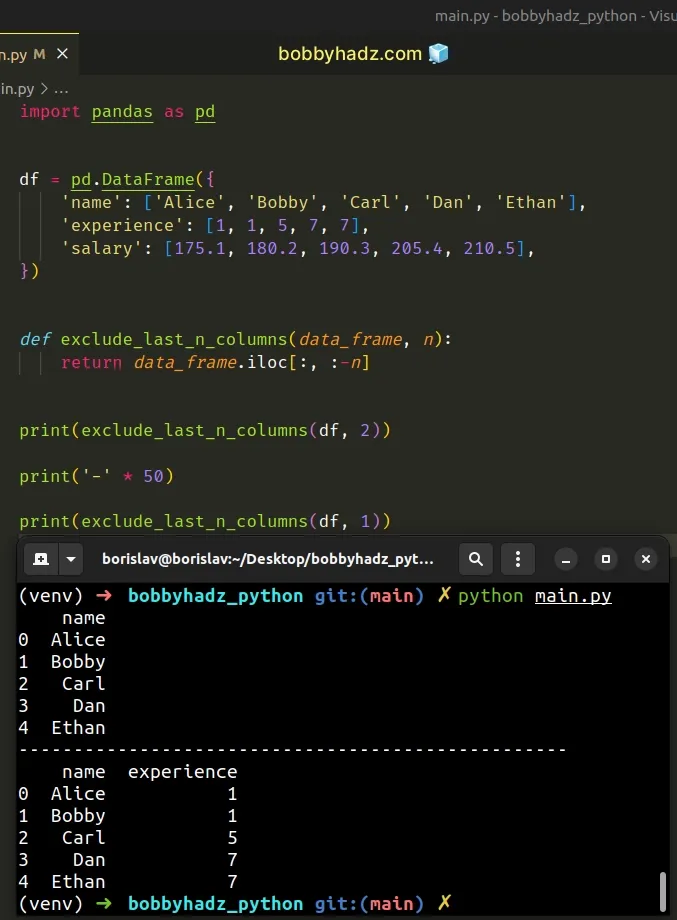
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) def exclude_last_n_columns(data_frame, n): return data_frame.iloc[:, :-n] print(exclude_last_n_columns(df, 2)) print('-' * 50) print(exclude_last_n_columns(df, 1))
Running the code sample produces the following output.
name 0 Alice 1 Bobby 2 Carl 3 Dan 4 Ethan -------------------------------------------------- name experience 0 Alice 1 1 Bobby 1 2 Carl 5 3 Dan 7 4 Ethan 7
# Select the Last N columns of a DataFrame using DataFrame.columns
You can also use slicing with the
DataFrame.columns
attribute to select the last N columns of a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) last_2_columns = df[df.columns[-2:]] print(last_2_columns)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 1 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 7 210.5 -------------------------------------------------- experience salary 0 1 175.1 1 1 180.2 2 5 190.3 3 7 205.4 4 7 210.5
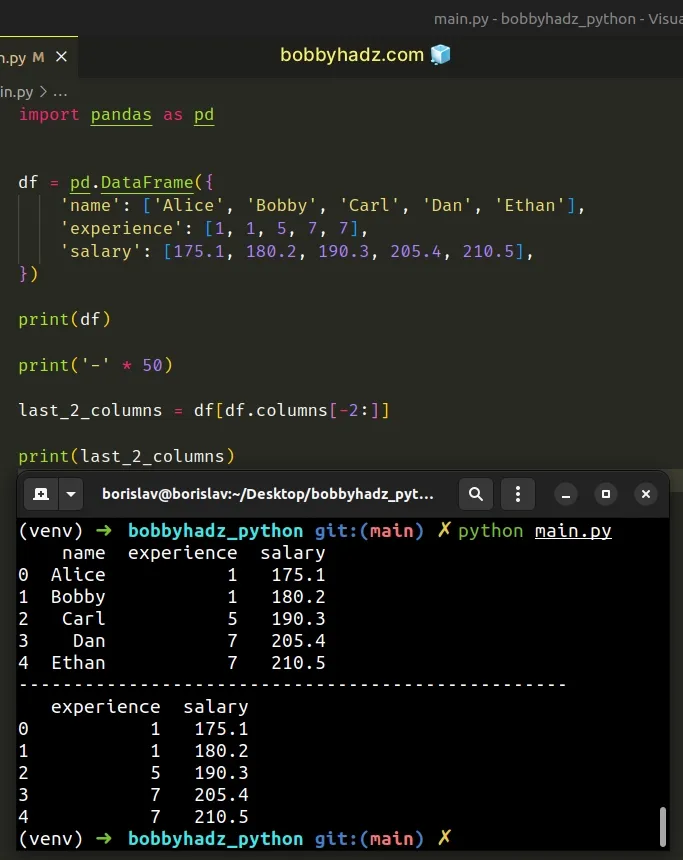
The code sample selects the last 2 columns of the DataFrame using the
DataFrame.columns attribute.
The attribute returns an index that contains the column labels of the
DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) # Index(['name', 'experience', 'salary'], dtype='object') print(df.columns)
I've also written an article on how to get the Nth row or every Nth row in a DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: Length of values does not match length of index
- How to add a Level to Pandas MultiIndex in Python
- Pandas: Convert GroupBy results to Dictionary of Lists
- Pandas: How to get the Max and Min Dates in a DataFrame
- Cannot perform 'rand_' with a dtyped [int64] array and scalar of type [bool]
- Pandas: Select first N or last N columns of DataFrame
- Pandas: Describe not showing all columns in DataFrame [Fix]
- Filter rows in a Pandas DataFrame using Regex
- Pandas: Get the Rows that are NOT in another DataFrame
- How to Transpose a Pandas DataFrame without index
- Pandas: GroupBy columns with NaN (missing) values
- Pandas: Split a Column of Lists into Multiple Columns
- NumPy: Get the indices of the N largest values in an Array
- Pandas: Merge only specific DataFrame columns
- How to modify a Subset of Rows in a Pandas DataFrame
- How to Start the Index of a Pandas DataFrame at 1
- Pandas: DataFrame.reset_index() not working [Solved]
- How to Add Axis Labels to a Plot in Pandas [5 Ways]
- How to Create a Set from a Series in Pandas
- Pandas: Remove non-numeric rows in a DataFrame column
- NumPy: Apply a Mask from one Array to another Array
- Pandas: Select rows based on a List of Indices
- Pandas: Find an element's Index in Series [7 Ways]
- First argument must be an iterable of pandas objects [Fix]
- ValueError: Index contains duplicate entries, cannot reshape

