How to Start the Index of a Pandas DataFrame at 1
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- How to Start the Index of a Pandas DataFrame at 1
- Start the Index of a Pandas DataFrame at 1 using range()
- Start the Index of a Pandas DataFrame at 1 using numpy.arange()
- Start the Index of a Pandas DataFrame at 1 using RangeIndex
# How to Start the Index of a Pandas DataFrame at 1
To start the index of a Pandas DataFrame at 1:
- By default, the DataFrame index starts at
0. - Use the
indexattribute to select the currentDataFrameindex. - Set the
indexattribute to the current index plus1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) print(df.index) print('-' * 50) df.index += 1 print(df.index) print('-' * 50) print(df)
Running the code sample produces the following output.
RangeIndex(start=0, stop=4, step=1) -------------------------------------------------- RangeIndex(start=1, stop=5, step=1) -------------------------------------------------- name experience salary 1 Alice 1 175.1 2 Bobby 3 180.2 3 Carl 1 190.3 4 Dan 7 205.4
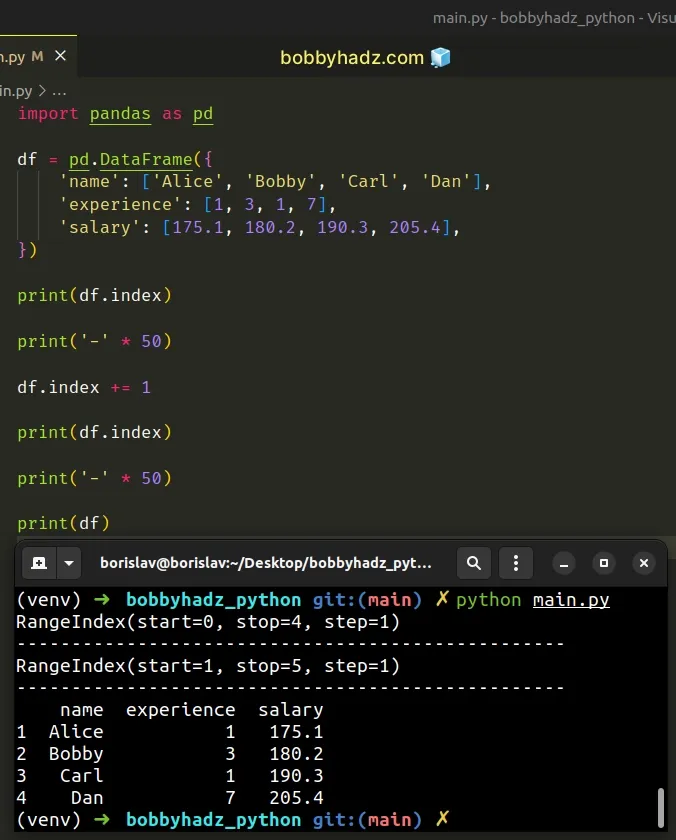
The
DataFrame.index
attribute returns the index (row labels) of the DataFrame.
By default, the DataFrame index starts at 0.
You can set the index to its current value plus 1 to have the DataFrame
index start at 1.
df.index += 1
The expression df.index += 1 is the short-hand version of
df.index = df.index + 1.
Both assignments set the index attribute of the DataFrame to the current
index value plus 1.
# Start the Index of a Pandas DataFrame at 1 using range()
You can also use the range class to start the
index of a Pandas DataFrame at 1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df.index = range(1, len(df) + 1) # name experience salary # 1 Alice 1 175.1 # 2 Bobby 3 180.2 # 3 Carl 1 190.3 # 4 Dan 7 205.4 print(df)
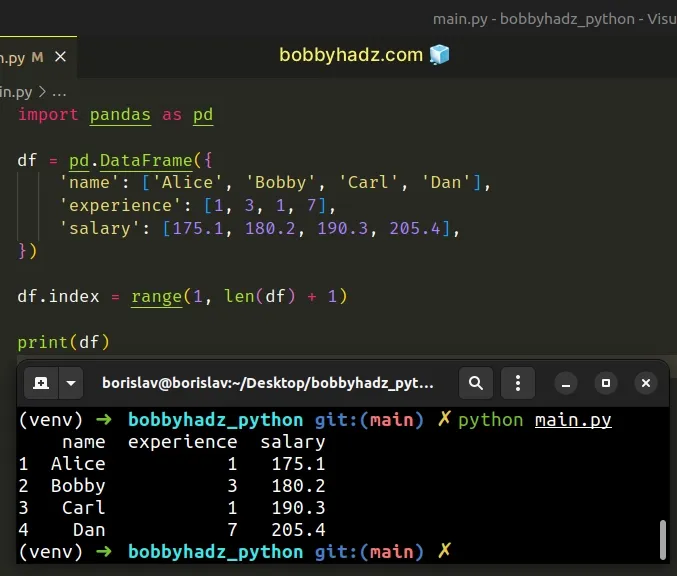
The range class is commonly used for looping a specific number of times.
The range() class takes the following arguments:
| Name | Description |
|---|---|
start | An integer representing the start of the range (defaults to 0) |
stop | Go up to, but not including the provided integer |
step | Range will consist of every N numbers from start to stop (defaults to 1) |
We set the start parameter to 1 to have the index start at 1.
The stop parameter is set to the length of the DataFrame plus 1 because the
stop value is exclusive (up to, but not including).
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) # 👇️ [1, 2, 3, 4] print(list(range(1, len(df) + 1)))
We could've also used the DataFrame.shape attribute to achieve the same result.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df.index = range(1, df.shape[0] + 1) # name experience salary # 1 Alice 1 175.1 # 2 Bobby 3 180.2 # 3 Carl 1 190.3 # 4 Dan 7 205.4 print(df)
The DataFrame.shape attribute returns a tuple that represents the
dimensionality of the DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) # 👇️ (4, 3) print(df.shape)
The first element in the tuple is the number of rows and the second is the number of columns.
1 to the number of rows because the stop value of the range() class is exclusive (up to, but not including).df.index = range(1, df.shape[0] + 1)
# Start the Index of a Pandas DataFrame at 1 using numpy.arange()
You can also use the
numpy.arange()
method to start the index of a Pandas DataFrame at 1.
First, make sure you
have the numpy module installed.
pip install numpy # or with pip3 pip3 install numpy
Now, import the numpy module and use the numpy.arange() method.
import pandas as pd import numpy as np df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df.index = np.arange(1, len(df) + 1) # name experience salary # 1 Alice 1 175.1 # 2 Bobby 3 180.2 # 3 Carl 1 190.3 # 4 Dan 7 205.4 print(df)
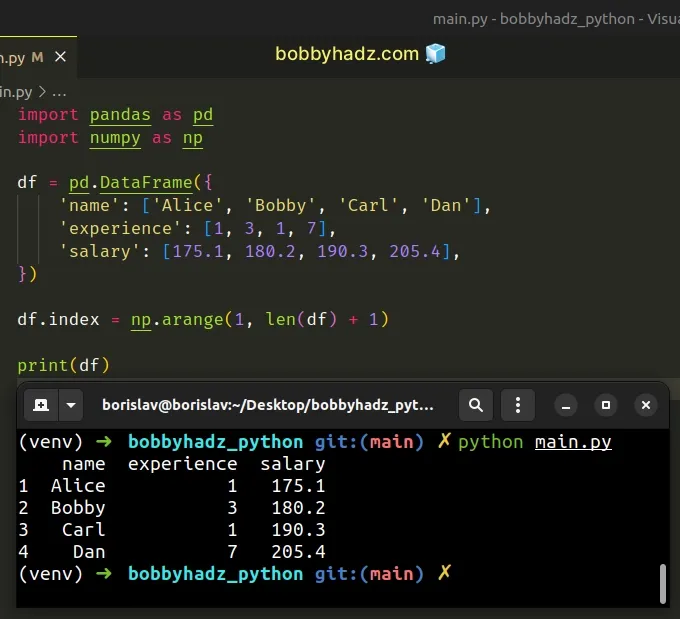
The numpy.arange() method returns the values within the given range.
import pandas as pd import numpy as np df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) # [1 2 3 4] print(np.arange(1, len(df) + 1))
The range in the example starts at 1 and goes up to, but not including
len(df) + 1.
# Start the Index of a Pandas DataFrame at 1 using RangeIndex
You can also use the
pandas.RangeIndex
class to start the index of a Pandas DataFrame at 1.
import pandas as pd a_dict = { 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], } first_key = list(a_dict.keys())[0] row_length = len(a_dict[first_key]) df = pd.DataFrame(a_dict, index=pd.RangeIndex( start=1, stop=row_length + 1, name='index') ) # name experience salary # index # 1 Alice 1 175.1 # 2 Bobby 3 180.2 # 3 Carl 1 190.3 # 4 Dan 7 205.4 print(df)
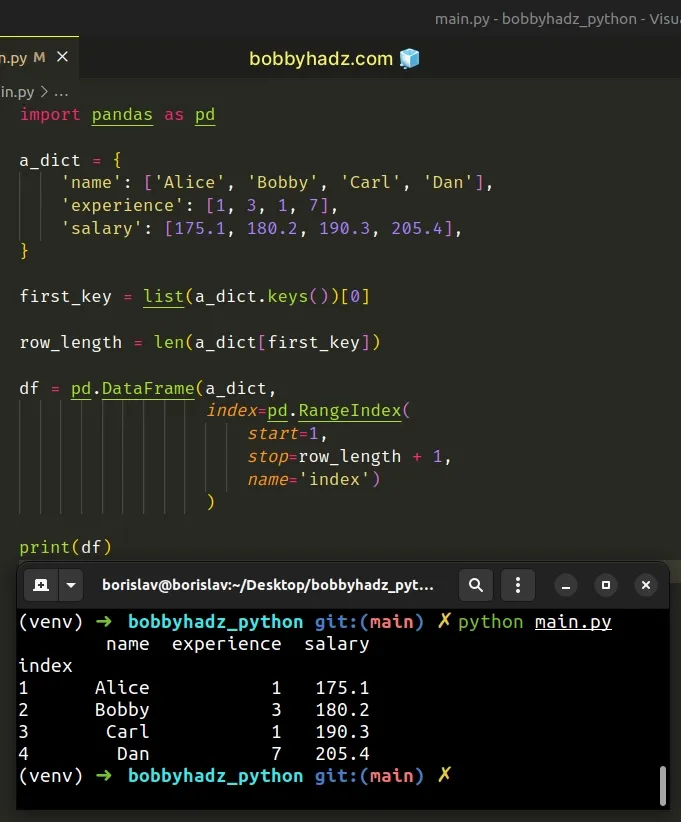
We set the index parameter when instantiating the pandas.DataFrame() class.
The RangeIndex class sets the index of the DataFrame using an integer range.
We set the start parameter to 1 to have the index start at 1.
The stop parameter is set to the number of rows in the DataFrame + 1.
We have to add 1 to the number of rows because the stop parameter is
exclusive (up to, but not including).
I've also written an article on how to keep the Index when merging DataFrames.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Panda: Using fillna() with specific columns in a DataFrame
- Pandas: Split a Column of Lists into Multiple Columns
- NumPy: Get the indices of the N largest values in an Array
- Pandas: How to keep the Index when merging DataFrames
- Pandas: Merge only specific DataFrame columns
- How to modify a Subset of Rows in a Pandas DataFrame
- Pandas TypeError: no numeric data to plot [Solved]
- Pandas: Setting column names when reading a CSV file
- Export a Pandas DataFrame to Excel without the Index
- Pandas: How to Query a Column name with Spaces
- Pandas: Create Scatter plot from multiple DataFrame columns
- Cannot mask with non-boolean array containing NA / NaN values
- Disable the TOKENIZERS_PARALLELISM=(true | false) warning
- RuntimeError: Expected scalar type Float but found Double
- Pandas: Convert timezone-aware DateTimeIndex to naive timestamp
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type float)
- Must have equal len keys and value when setting with iterable
- Cannot convert non-finite values (NA or inf) to integer
- Pandas: How to efficiently Read a Large CSV File
- Pandas: Set number of max Rows and Cols shown in DataFrame

