Filter rows in a Pandas DataFrame using Regex
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Filter rows in a Pandas DataFrame using Regex
- Getting the rows with the values that DON'T match the regex
- Filtering rows with a built-in method
- Selecting the rows that contain a certain substring using Regex
- Selecting the rows that end with a certain substring using Regex
# Filter rows in a Pandas DataFrame using Regex
To filter rows in a Pandas DataFrame using a regex:
- Use the
str.contains()method to test if a regex matches each value in a specific column. - Use bracket notation to filter the rows by the
Seriesof boolean values.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bobby', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'^Al' starting_with = df[df['name'].str.contains(regex)] # name sales salary # 0 Alice 1 175.1 # 1 Alex 3 180.2 print(starting_with)
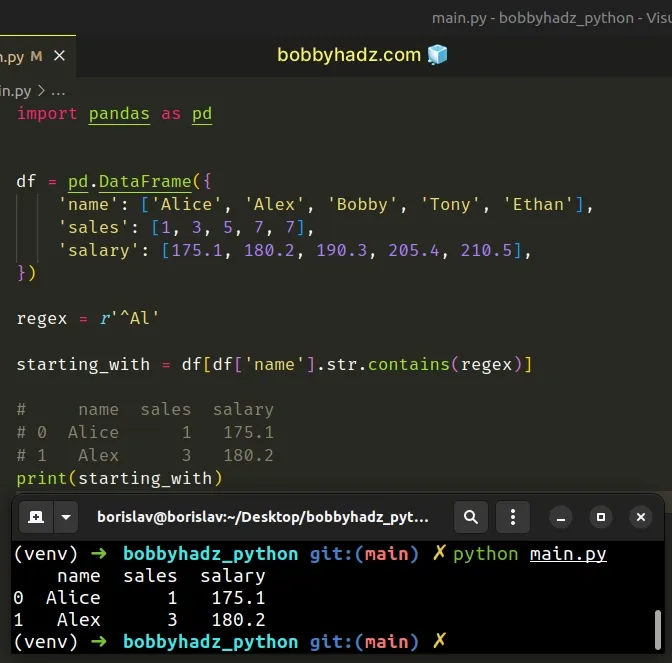
The code sample selects the rows in the name column that start with "Al".
The str.contains() method tests if a regex matches each value in the given column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bobby', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'^Al' # 0 True # 1 True # 2 False # 3 False # 4 False # Name: name, dtype: bool print(df['name'].str.contains(regex))
The last step is to use bracket notation to select the matching rows.
regex = r'^Al' starting_with = df[df['name'].str.contains(regex)]
By default, the str.contains method is case-sensitive.
If you want to make it case-insensitive, set the case argument to False.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bobby', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'^al' starting_with = df[df['name'].str.contains(regex, case=False)] # name sales salary # 0 Alice 1 175.1 # 1 Alex 3 180.2 print(starting_with)
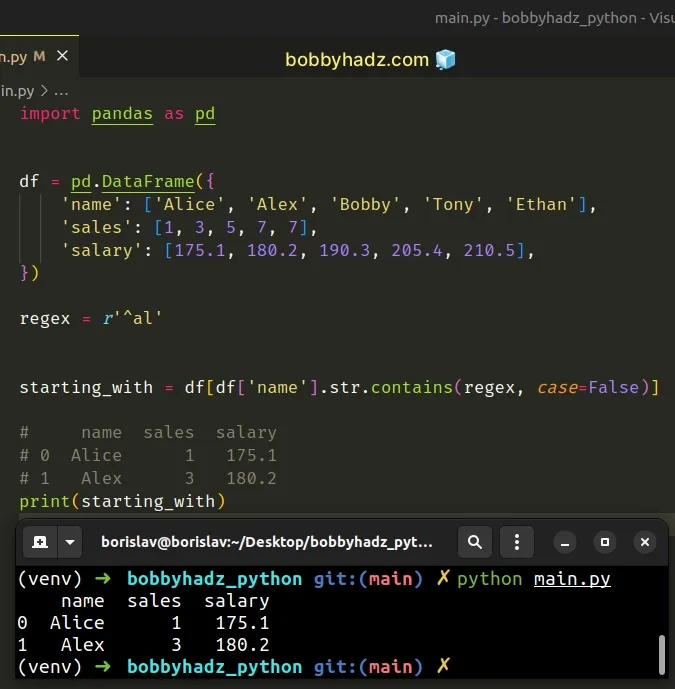
When the case argument is set to False, the str.contains method becomes
case-insensitive.
You can also set the flags argument when calling the method.
import re import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bobby', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'^al' starting_with = df[df['name'].str.contains( regex, case=False, flags=re.IGNORECASE)] # name sales salary # 0 Alice 1 175.1 # 1 Alex 3 180.2 print(starting_with)
The flags argument represents flags that are passed to the re module.
# Getting the rows with the values that DON'T match the regex
If you need to get the rows with the values that don't match the regex, use the
tilde ~ operator.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bobby', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'^Al' starting_with = df[~df['name'].str.contains(regex)] # name sales salary # 2 Bobby 5 190.3 # 3 Tony 7 205.4 # 4 Ethan 7 210.5 print(starting_with)
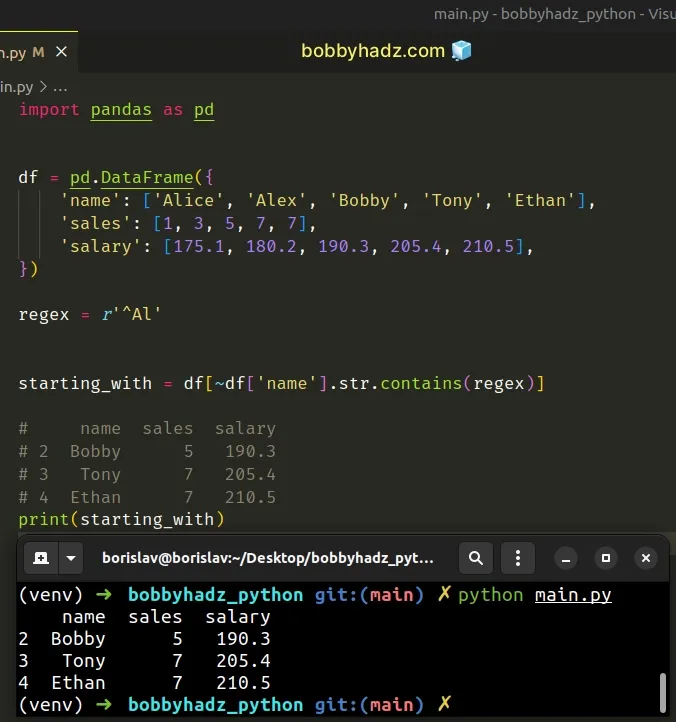
The code sample uses the tilde ~ operator to invert the boolean values in the
Series before filtering the DataFrame based on the regex.
# Filtering rows with a built-in method
In some cases, you might be able to use a built-in method to filter the rows (instead of a regex).
For example, if you need to select the rows that start with a specific
substring, you can use the str.startswith() method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bobby', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) starting_with = df[df['name'].str.startswith('Al')] # name sales salary # 0 Alice 1 175.1 # 1 Alex 3 180.2 print(starting_with)
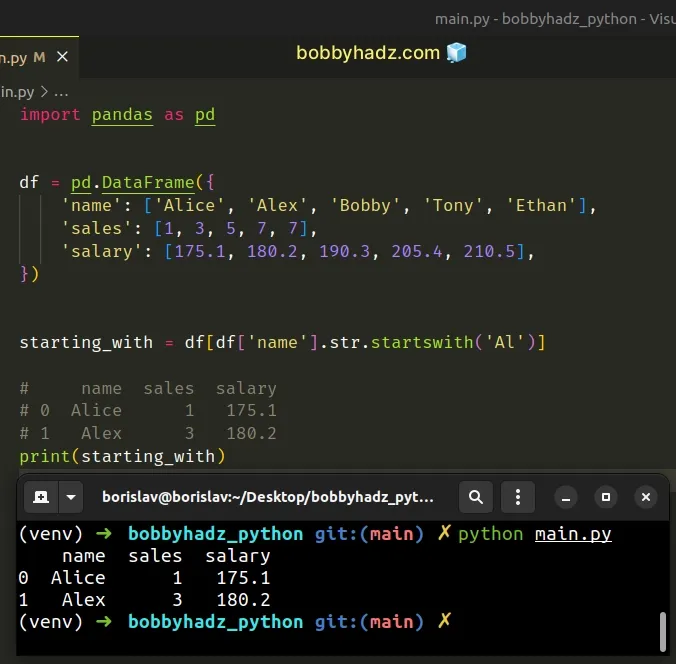
There are many built-in methods on the str attribute that you might be able to
use instead of a regex.
# Selecting the rows that contain a certain substring using Regex
You can also use the str.contains() method if you need to select the rows that
contain a certain substring using a regex.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bony', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'.*on.*' containing = df[df['name'].str.contains(regex)] # name sales salary # 2 Bony 5 190.3 # 3 Tony 7 205.4 print(containing)
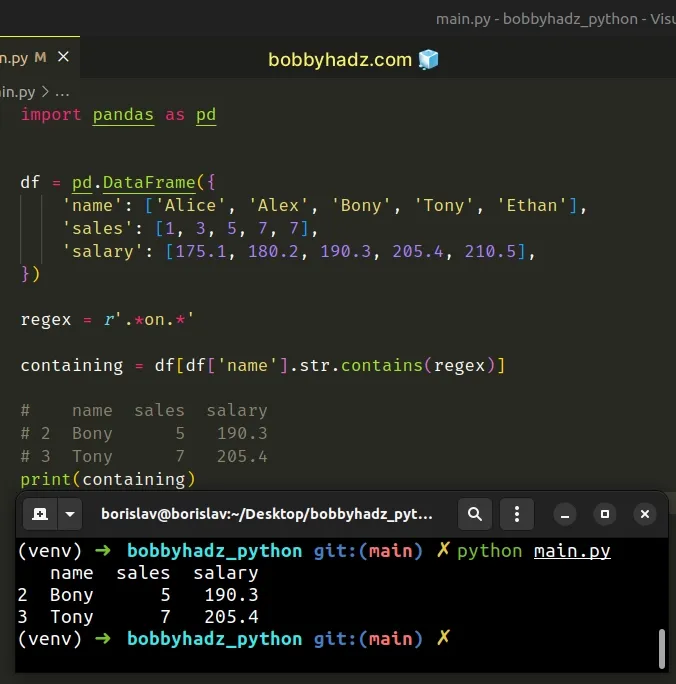
The code sample selects the rows with values that contain the substring "on".
If you need to perform the test in a case-insensitive manner, set the case or
flags argument, depending on whether you use a regular expression.
import re import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bony', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'.*ON.*' containing = df[df['name'].str.contains( regex, case=False, flags=re.IGNORECASE)] # name sales salary # 2 Bony 5 190.3 # 3 Tony 7 205.4 print(containing)
You could also select the rows that contain a given substring without a regular expression.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Alex', 'Bony', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) substring = 'on' containing = df[df['name'].str.contains(substring, case=False, regex=False)] # name sales salary # 2 Bony 5 190.3 # 3 Tony 7 205.4 print(containing)
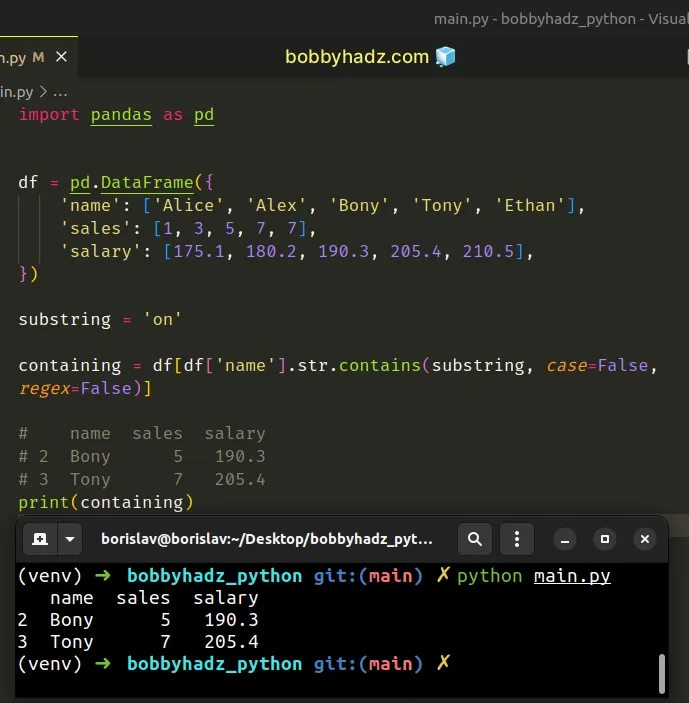
Notice that we set the regex argument to False.
If the regex argument is set to False, the supplied pattern (the first
argument) is treated as a literal string.
By default, the pattern argument is treated as a regular expression.
# Selecting the rows that end with a certain substring using Regex
The str.contains() method can also be used if you need to select the rows that
end with a certain substring using a regex.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Yoni', 'Bony', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'y$' ending_with = df[df['name'].str.contains(regex)] # name sales salary # 2 Bony 5 190.3 # 3 Tony 7 205.4 print(ending_with)
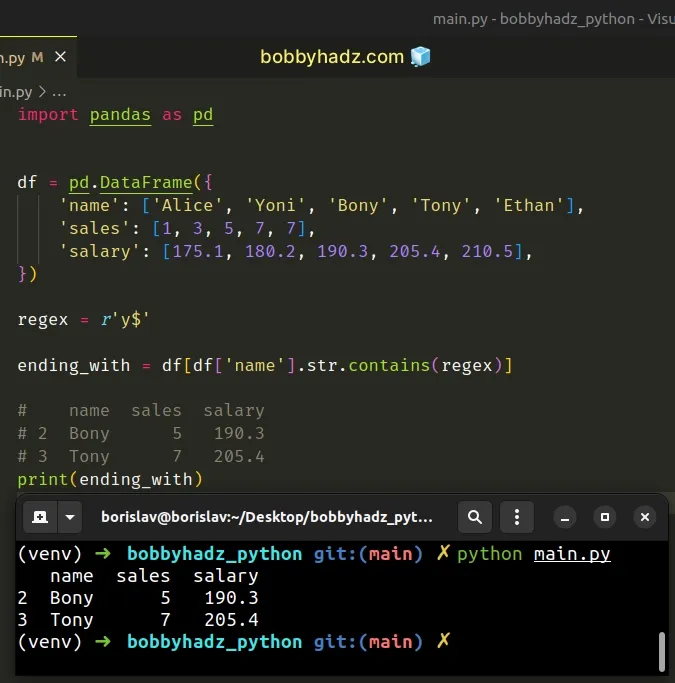
The code sample selects the rows whose name values end with y.
If you need to perform the test in a case-insensitive manner, set the case or
flags arguments when calling str.contains().
import re import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Yoni', 'Bony', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) regex = r'Y$' ending_with = df[df['name'].str.contains( regex, case=False, flags=re.IGNORECASE)] # name sales salary # 2 Bony 5 190.3 # 3 Tony 7 205.4 print(ending_with)
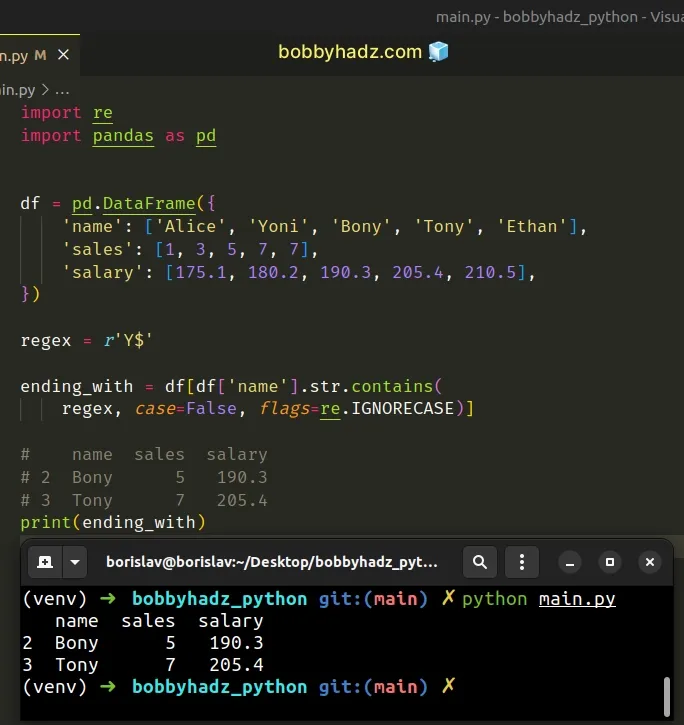
You can also select the rows that end with a certain substring using the
built-in str.endswith() method instead of using a regex.
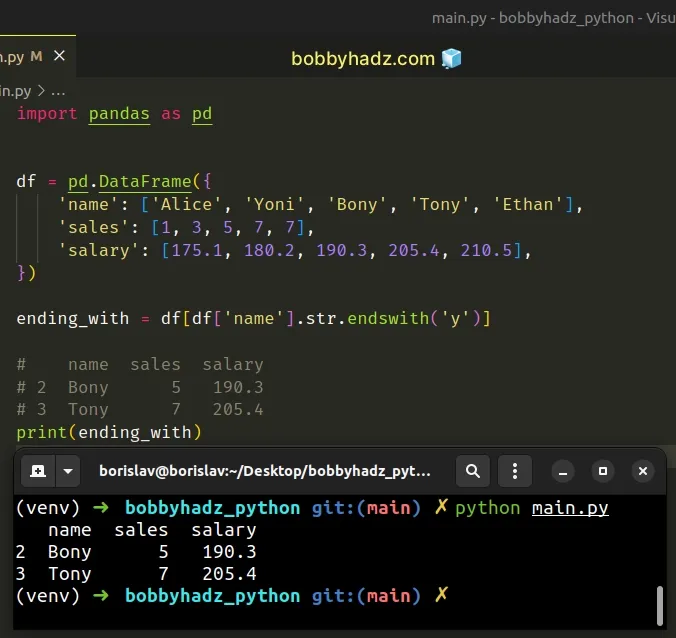
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Yoni', 'Bony', 'Tony', 'Ethan'], 'sales': [1, 3, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) ending_with = df[df['name'].str.endswith('y')] # name sales salary # 2 Bony 5 190.3 # 3 Tony 7 205.4 print(ending_with)
I've also written articles on:
- Pandas: How to Filter a DataFrame by value counts
- Pandas: Find the percentage of Missing values in each Column
- Pandas: Find common Rows (intersection) between 2 DataFrames
- Pandas: Find first and last non-NaN values in a DataFrame
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: Shape of passed values is X, indices imply Y
- ValueError: Length of values does not match length of index
- Pandas: Find first and last non-NaN values in a DataFrame
- How to shuffle two NumPy Arrays together (in Unison)
- ValueError: If using all scalar values, you must pass index
- Pandas: Remove special characters from Column Values/Names
- Pandas: Count the unique combinations of two Columns

