Pandas: Get Nth row or every Nth row in a DataFrame
Last updated: Apr 12, 2024
Reading time·7 min

# Table of Contents
- Get the Nth row in a Pandas DataFrame
- Getting the Nth row of a DataFrame using DataFrame.take()
- Getting every Nth row in a Pandas DataFrame
- Select every Nth row of DataFrame, starting at row X
- Get every Nth row in DataFrame using modulo operator
- Exclude every Nth row from a Pandas DataFrame
# Get the Nth row in a Pandas DataFrame
Use the DataFrame.iloc integer-based indexer to get the Nth row in a Pandas
DataFrame.
You can specify the index in two sets of square brackets to get a DataFrame
result or one set to get the output in a Series.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) first_row = df.iloc[[0]] print(first_row) print('-' * 50) second_row = df.iloc[[1]] print(second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 0 Alice 1 175.1 -------------------------------------------------- name experience salary 1 Bobby 3 180.2
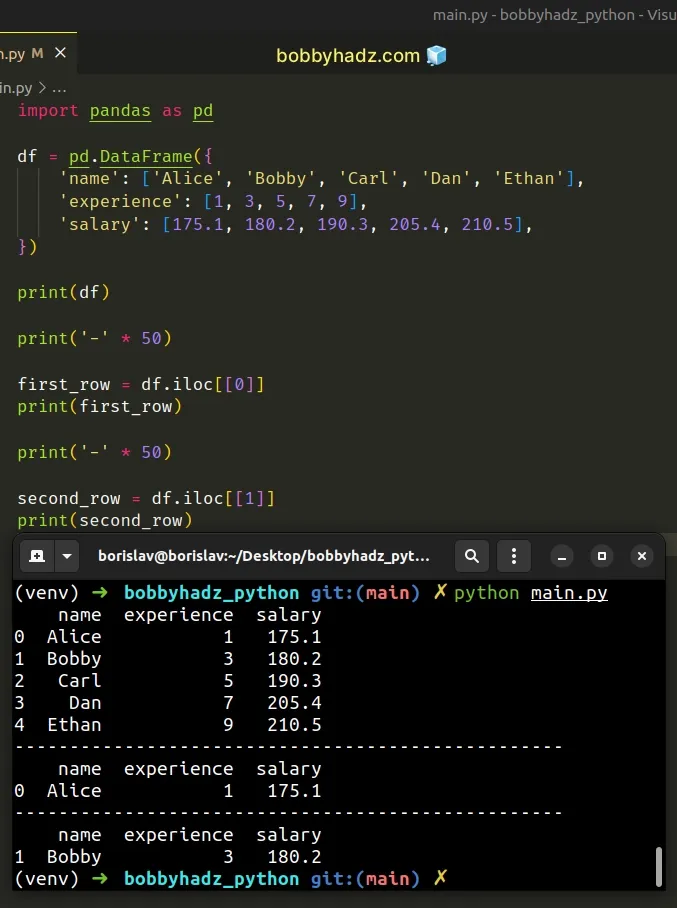
Note that indexes are zero-based, so use 0 to select the first row and 1 to
select the second row.
When you use two sets of square brackets, you get the corresponding row in a
DataFrame.
first_row = df.iloc[[0]] # name experience salary # 0 Alice 1 175.1 print(first_row)
If you want to get the result in a Series, use one set of square brackets.
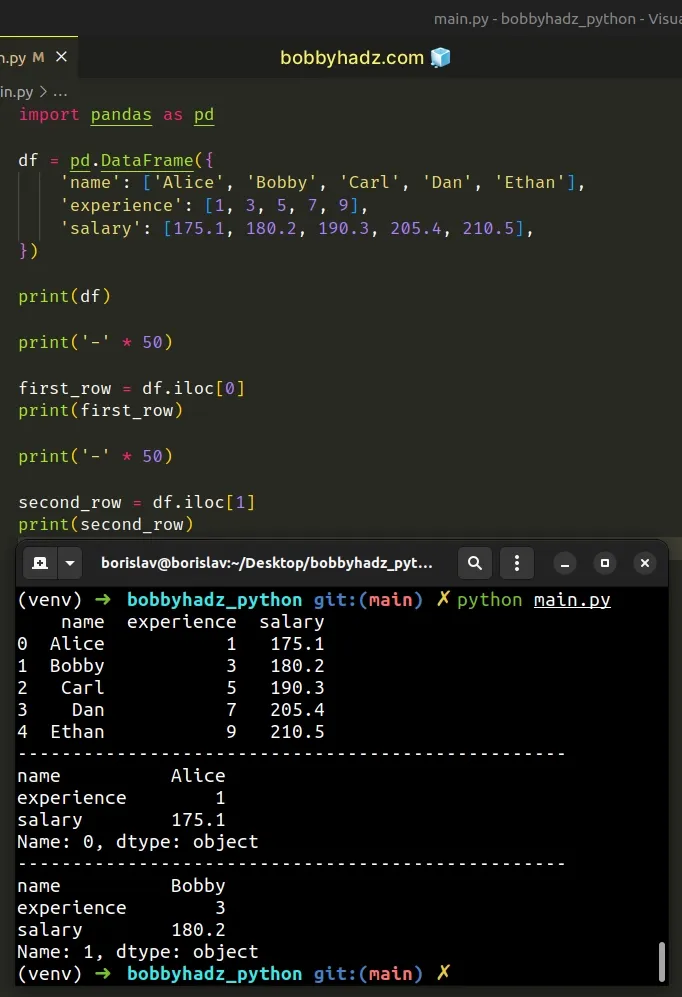
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) first_row = df.iloc[0] print(first_row) print('-' * 50) second_row = df.iloc[1] print(second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name Alice experience 1 salary 175.1 Name: 0, dtype: object -------------------------------------------------- name Bobby experience 3 salary 180.2 Name: 1, dtype: object
# Getting the Nth row of a DataFrame using DataFrame.take()
You can also use the
DataFrame.take()
method to get the Nth row of a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) first_row = df.take([0]) print(first_row) print('-' * 50) second_row = df.take([1]) print(second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 0 Alice 1 175.1 -------------------------------------------------- name experience salary 1 Bobby 3 180.2
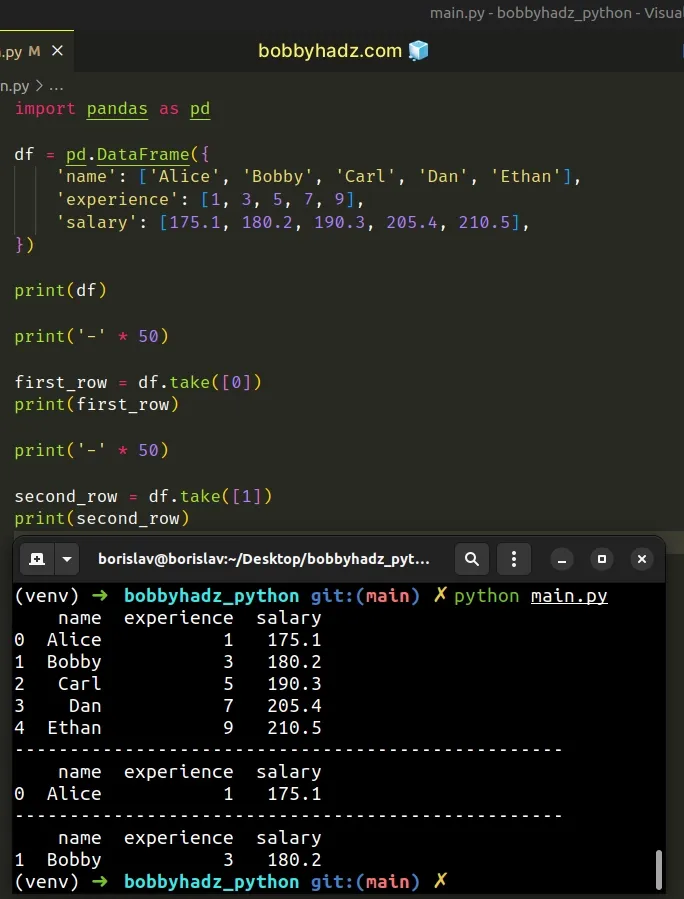
The DataFrame.take() method returns the elements in the specified indices
along an axis.
Notice that we call the take() method with a list containing an index and not
with the index directly.
first_row = df.take([0]) print(first_row)
# Getting every Nth row in a Pandas DataFrame
Use the DataFrame.iloc integer-based indexer to get every Nth row in a Pandas DataFrame.
The expression with return a new DataFrame that only contains every Nth
row.
The following code sample selects every 2nd row of the DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) every_second_row = df.iloc[::2, :] print(every_second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 0 Alice 1 175.1 2 Carl 5 190.3 4 Ethan 9 210.5
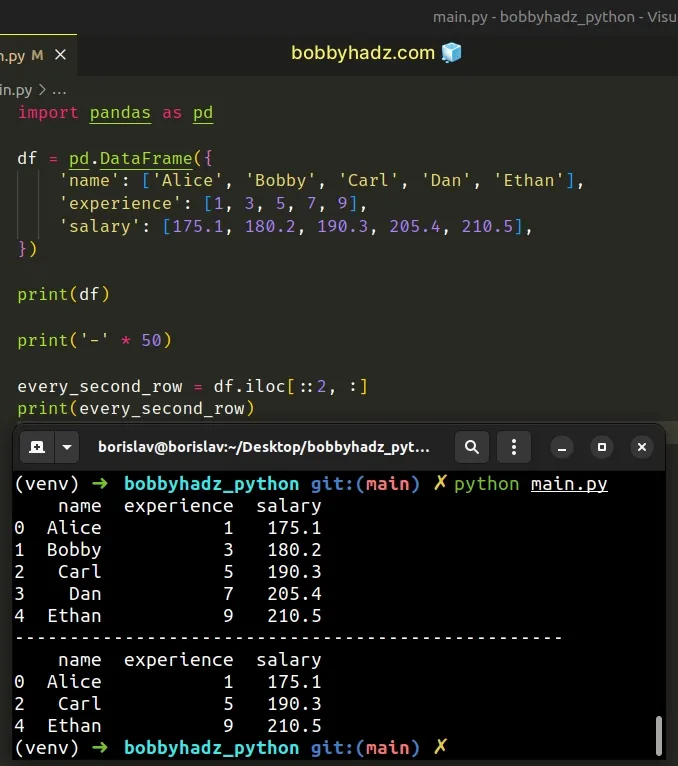
We used the
DataFrame.iloc
integer-based indexer to select every second row of the DataFrame.
# 👇️ selects every second row every_second_row = df.iloc[::2, :]
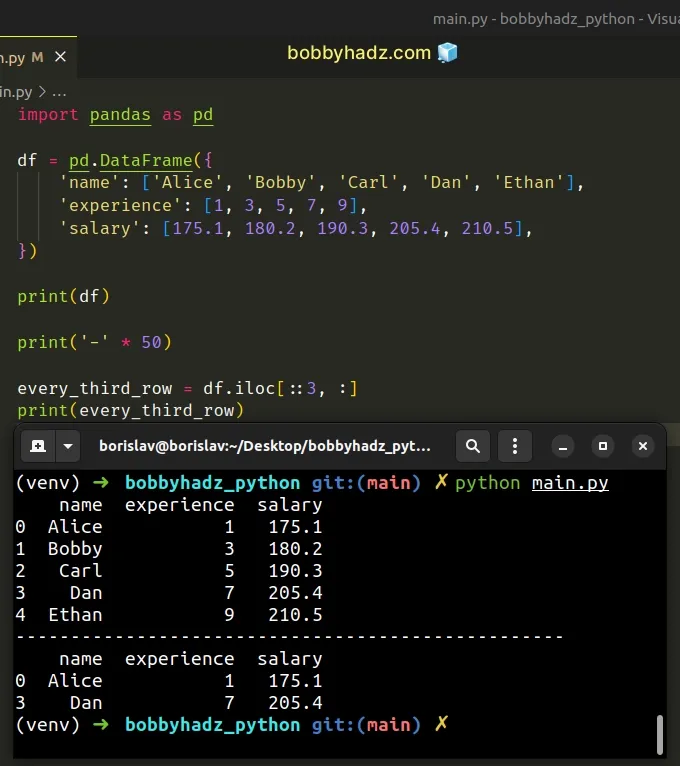
The same approach can be used if you want to select every third row.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) every_third_row = df.iloc[::3, :] print(every_third_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 0 Alice 1 175.1 3 Dan 7 205.4
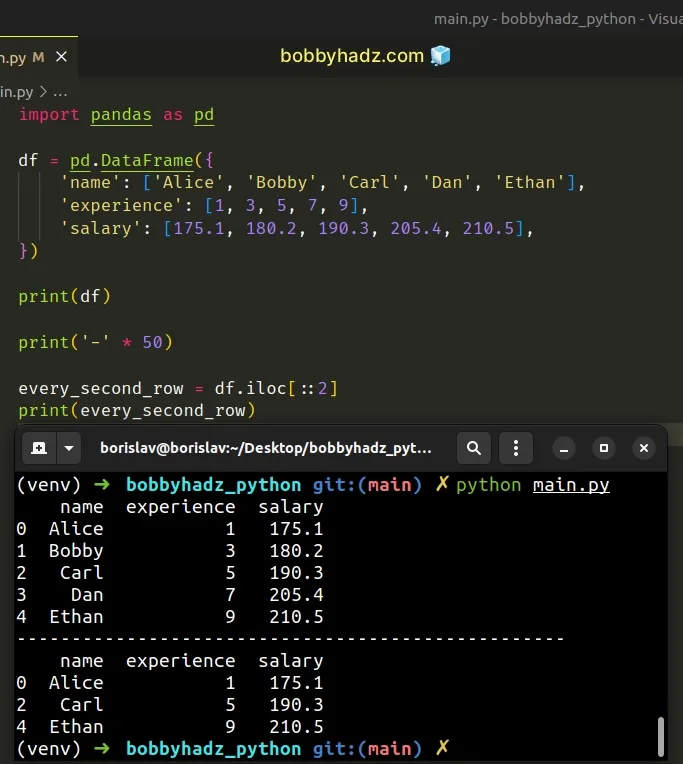
You can also omit the column part in the expression (after the comma, between the square brackets).
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) # 👇️ omitting column part every_second_row = df.iloc[::2] print(every_second_row)
# Select every Nth row of DataFrame, starting at row X
You can use the same approach to select every Nth row of a DataFrame, starting
at row X.
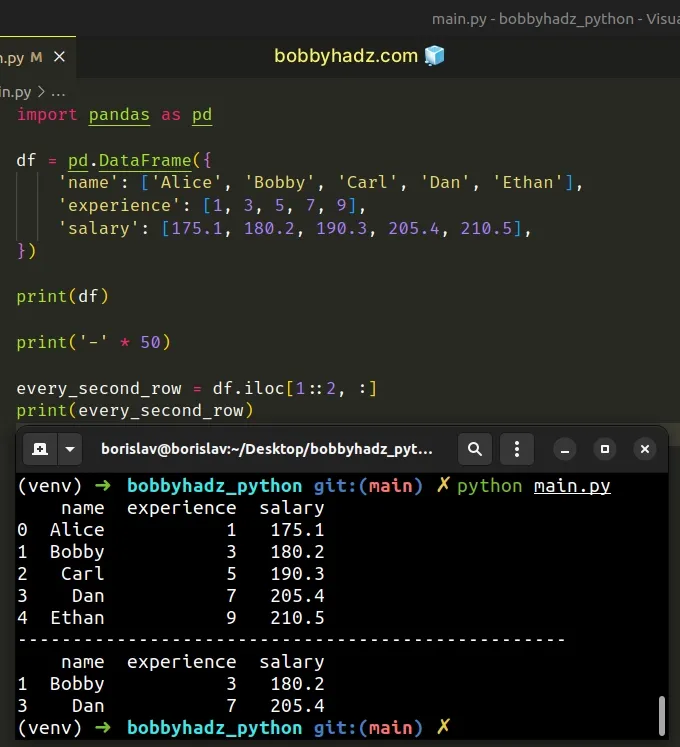
The following code sample selects every second row, starting at row index 1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) every_second_row = df.iloc[1::2, :] print(every_second_row)
Running the code sample produces the following result.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 1 Bobby 3 180.2 3 Dan 7 205.4
Similarly, the following code sample selects every 3rd row, starting at row
index 1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) every_second_row = df.iloc[1::3, :] print(every_second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 1 Bobby 3 180.2 4 Ethan 9 210.5
# Get every Nth row in DataFrame using modulo operator
You can also use the
modulo (%)
operator to select every Nth row in a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) every_second_row = df[df.index % 2 == 0] print(every_second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 0 Alice 1 175.1 2 Carl 5 190.3 4 Ethan 9 210.5
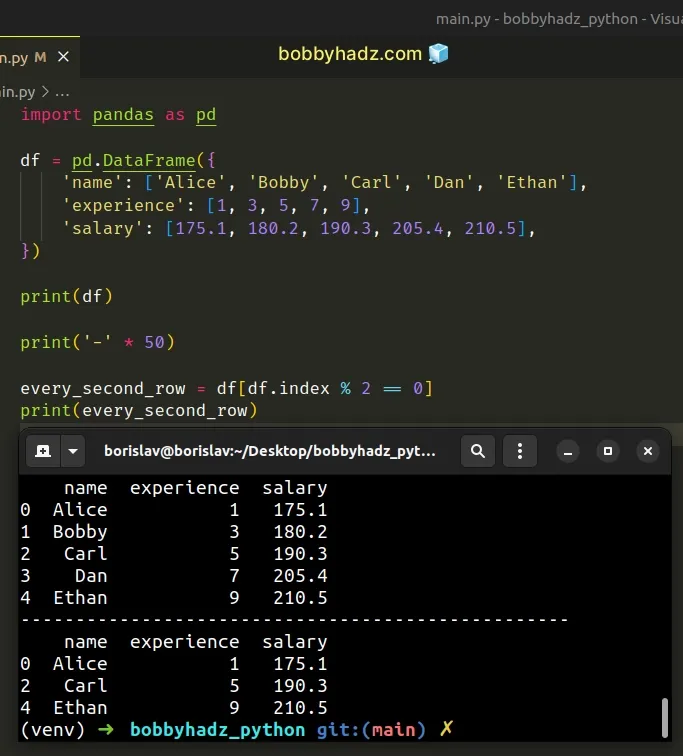
We check if the remainder of dividing each index by 2 is equal to 0.
If the condition is met, the row gets included in the resulting DataFrame.
If your index doesn't start at 0, you might have to call reset_index().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) every_second_row = df[df.reset_index().index % 2 == 0] print(every_second_row)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 0 Alice 1 175.1 2 Carl 5 190.3 4 Ethan 9 210.5
# Exclude every Nth row from a Pandas DataFrame
You can use the same approach to exclude every Nth row in a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 3, 5, 7, 9], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) print(df) print('-' * 50) exclude_every_2nd = df[df.index % 2 != 0] print(exclude_every_2nd)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 180.2 2 Carl 5 190.3 3 Dan 7 205.4 4 Ethan 9 210.5 -------------------------------------------------- name experience salary 1 Bobby 3 180.2 3 Dan 7 205.4
We check if dividing each index by 2 does not have a remainder of 0.
If the condition is met, the rows get included in the result.
In practice, the code sample excludes every second row from the DataFrame,
starting at index 0.
I've also written an article on how to select the first N or the last N columns of a DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Converting a Nested Dictionary to a Pandas DataFrame
- Pandas: Strip whitespace from Column Headers in DataFrame
- Pandas: Drop columns if Name contains a given String
- How to repeat Rows N times in a Pandas DataFrame
- How to convert a Pandas DataFrame to a Markdown Table
- How to remove Time from DateTime in Pandas [5 Ways]
- Filter rows in a Pandas DataFrame using Regex
- Pandas: Get the Rows that are NOT in another DataFrame
- How to Transpose a Pandas DataFrame without index
- Pandas: Split a Column of Lists into Multiple Columns
- Pandas: Remove non-numeric rows in a DataFrame column
- Pandas: Select rows based on a List of Indices
- Matplotlib: No artists with labels found to put in legend
- ValueError: If using all scalar values, you must pass index
- Pandas: Setting column names when reading a CSV file
- Export a Pandas DataFrame to Excel without the Index
- Pandas: Remove special characters from Column Values/Names
- PyTorch: Trying to backward through the graph a second time
- Pandas: Apply a Function to each Cell of a DataFrame

