Pandas: Get the Rows that are NOT in another DataFrame
Last updated: Aug 7, 2023
Reading time·5 min

# Table of Contents
- Pandas: Get the Rows that are NOT in another DataFrame
- Pandas: Get the Rows that are NOT in another DataFrame using inverted isin() calls
# Pandas: Get the Rows that are NOT in another DataFrame
To get the rows that are NOT in another DataFrame:
- Use the
DataFrame.merge()method to perform a left join fromdf1todf2. - Get the rows that come only from the first
DataFrame. - Filter the original
DataFrameusing the booleanSeries.
import pandas as pd df1 = pd.DataFrame({ 'a': [2, 4, 6, 8, 10], 'b': [112, 114, 115, 118, 120] }) df2 = pd.DataFrame({ 'a': [2, 4, 6, 9, 11], 'b': [112, 114, 115, 190, 250] }) all_rows = df1.merge(df2.drop_duplicates(), on=[ 'a', 'b'], how='left', indicator=True) print(all_rows) rows_not_in = all_rows[all_rows['_merge'] == 'left_only'] print('-' * 50) print(rows_not_in)
Running the code sample produces the following output.
a b _merge 0 2 112 both 1 4 114 both 2 6 115 both 3 8 118 left_only 4 10 120 left_only -------------------------------------------------- a b _merge 3 8 118 left_only 4 10 120 left_only
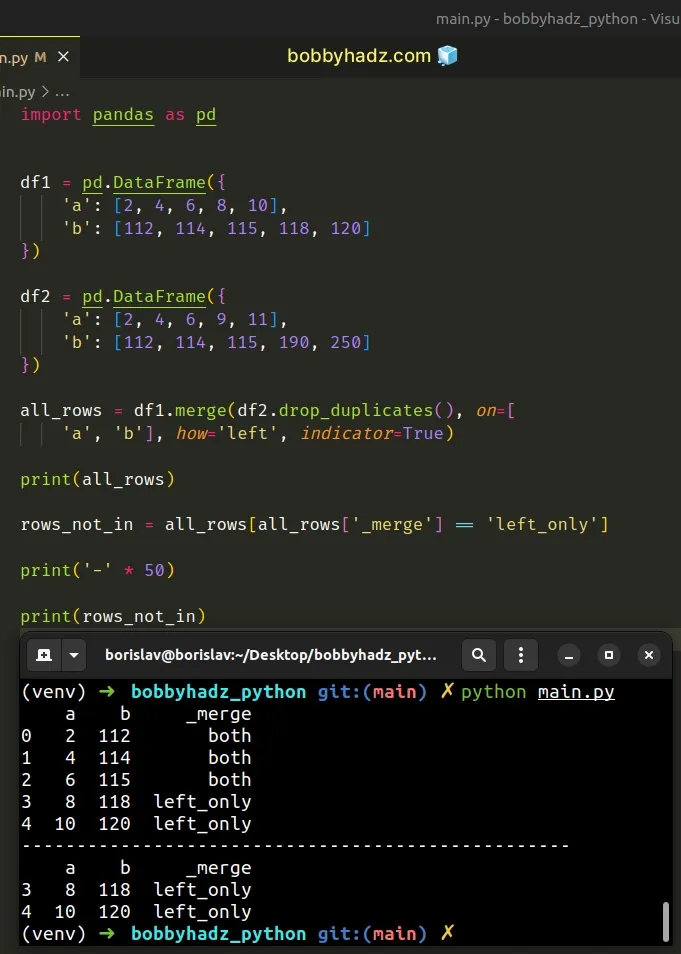
We used the
DataFrame.merge
method to perform a left join, selecting the rows that are in both DataFrames
and those that are contained in the first DataFrame only (df1).
all_rows = df1.merge(df2.drop_duplicates(), on=[ 'a', 'b'], how='left', indicator=True) # a b _merge # 0 2 112 both # 1 4 114 both # 2 6 115 both # 3 8 118 left_only # 4 10 120 left_only print(all_rows)
The code sample selects the rows in df1 that are NOT contained in df2.
Notice that we used the
DataFrame.drop_duplicates
method to remove the duplicate rows from the DataFrame before calling
merge().
DataFrame is joined with exactly 1 row of the second DataFrame.We set the indicator parameter to True to add a _merge column to the
output DataFrame.
The _merge column contains information about the DataFrame from which the
row was selected.
The _merge column will have a value of "left_only" for rows whose merge key
only appears in the left DataFrame.
If the row has a value of "both", then the observation's merge key is found in
both DataFrames.
indicator argument to a string instead of a boolean in case you want to rename the _merge column to something else.Here is an example that names the column source_df instead of _merge.
import pandas as pd df1 = pd.DataFrame({ 'a': [2, 4, 6, 8, 10], 'b': [112, 114, 115, 118, 120] }) df2 = pd.DataFrame({ 'a': [2, 4, 6, 9, 11], 'b': [112, 114, 115, 190, 250] }) all_rows = df1.merge(df2.drop_duplicates(), on=[ 'a', 'b'], how='left', indicator='source_df') print(all_rows) rows_not_in = all_rows[all_rows['source_df'] == 'left_only'] print('-' * 50) print(rows_not_in)
Running the code sample produces the following output.
a b source_df 0 2 112 both 1 4 114 both 2 6 115 both 3 8 118 left_only 4 10 120 left_only -------------------------------------------------- a b source_df 3 8 118 left_only 4 10 120 left_only
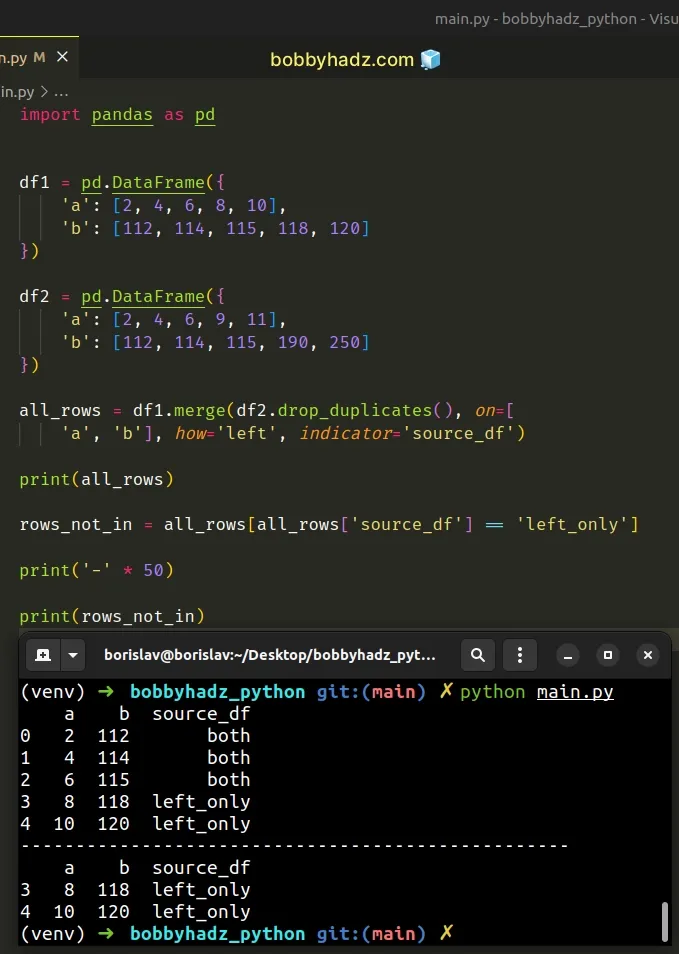
As shown in the output, the _merge column is now named source_df.
If you simply need to remove the _merge column from the resulting DataFrame,
use the DataFrame.drop method.
import pandas as pd df1 = pd.DataFrame({ 'a': [2, 4, 6, 8, 10], 'b': [112, 114, 115, 118, 120] }) df2 = pd.DataFrame({ 'a': [2, 4, 6, 9, 11], 'b': [112, 114, 115, 190, 250] }) all_rows = df1.merge(df2.drop_duplicates(), on=[ 'a', 'b'], how='left', indicator=True) print(all_rows) rows_not_in = all_rows[all_rows['_merge'] == 'left_only'] print('-' * 50) rows_not_in = rows_not_in.drop(['_merge'], axis=1) print(rows_not_in)
Running the code sample produces the following output.
a b _merge 0 2 112 both 1 4 114 both 2 6 115 both 3 8 118 left_only 4 10 120 left_only -------------------------------------------------- a b 3 8 118 4 10 120
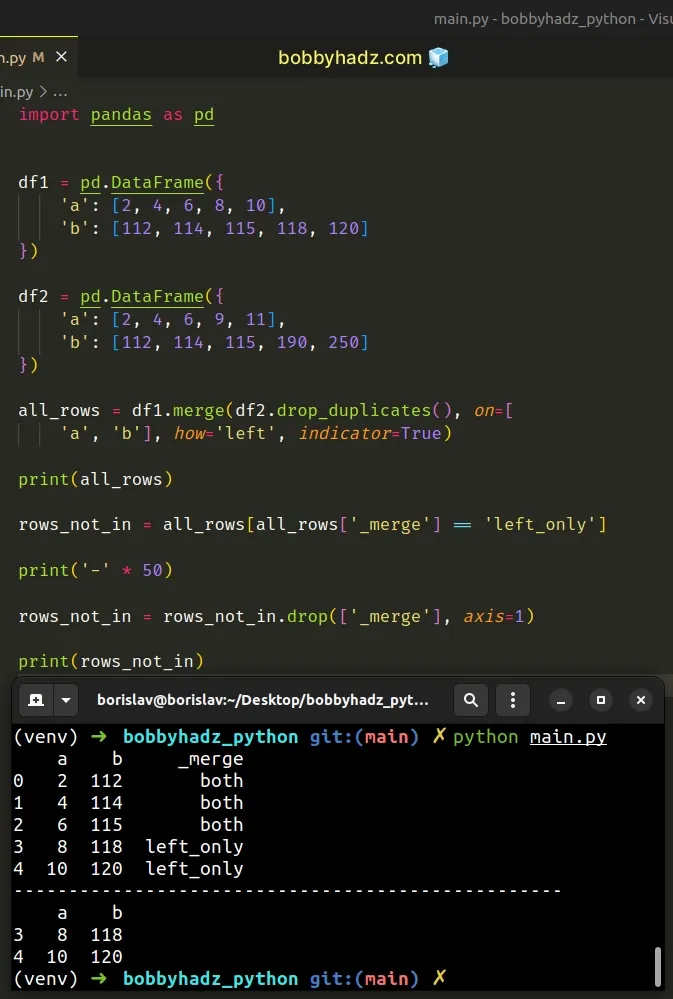
Make sure to drop the _merge column after you've selected the rows in df1
that are NOT in df2 (and not before).
# Pandas: Get the Rows that are NOT in another DataFrame using inverted isin() calls
You can also use inverted isin() method calls with
the tilde ~ operator
to find the rows that are not in another DataFrame.
import pandas as pd df1 = pd.DataFrame({ 'a': [2, 4, 6, 8, 10], 'b': [112, 114, 115, 118, 120] }) df2 = pd.DataFrame({ 'a': [2, 4, 6, 9, 11], 'b': [112, 114, 115, 190, 250] }) all_rows = df1.merge(df2, on=['a', 'b']) print(all_rows) rows_not_in = df1[(~df1['a'].isin(all_rows['a'])) & (~df1['b'].isin(all_rows['b']))] print('-' * 50) print(rows_not_in)
Running the code sample produces the following output.
a b 0 2 112 1 4 114 2 6 115 -------------------------------------------------- a b 3 8 118 4 10 120
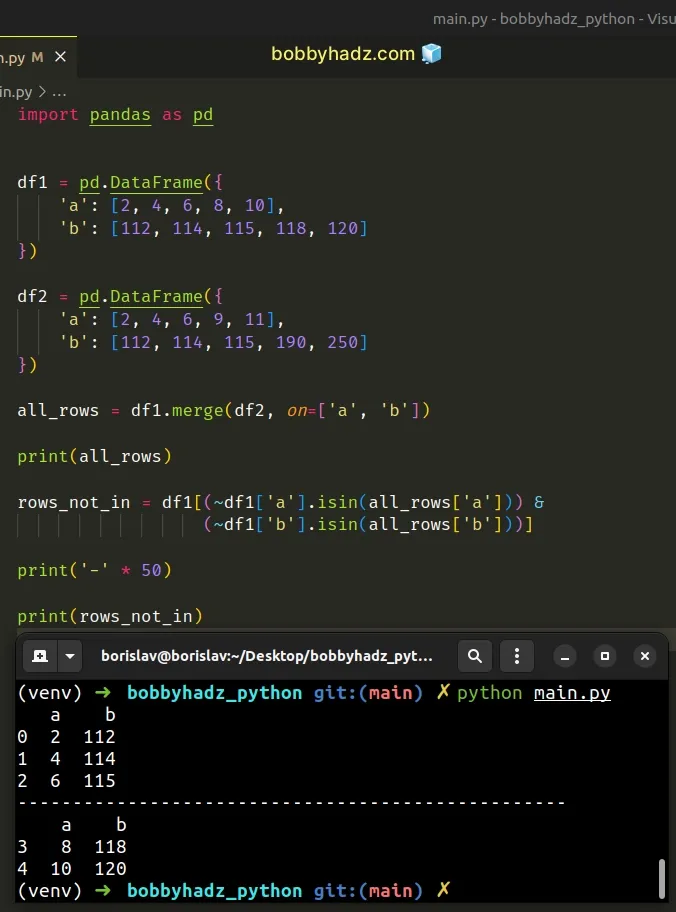
We first used the merge() method to
get the intersection of the columns in both DataFrames.
all_rows = df1.merge(df2, on=['a', 'b']) # a b # 0 2 112 # 1 4 114 # 2 6 115 print(all_rows)
The next step is to get all rows that are NOT in the other DataFrame by using
inverted isin() calls.
rows_not_in = df1[(~df1['a'].isin(all_rows['a'])) & (~df1['b'].isin(all_rows['b']))] # a b # 3 8 118 # 4 10 120 print(rows_not_in)
The
DataFrame.isin()
method tests whether each element in the DataFrame is contained in the
specified values.
We used the tilde ~ operator to invert the results.
In this case, you can also shorten this a bit by using the DataFrame.dropna() method to remove any missing values.
import pandas as pd df1 = pd.DataFrame({ 'a': [2, 4, 6, 8, 10], 'b': [112, 114, 115, 118, 120] }) df2 = pd.DataFrame({ 'a': [2, 4, 6, 9, 11], 'b': [112, 114, 115, 190, 250] }) rows_not_in = df1[~df1.isin(df2)].dropna(how='all') print(rows_not_in)
Running the code sample produces the following output.
a b 3 8.0 118.0 4 10.0 120.0
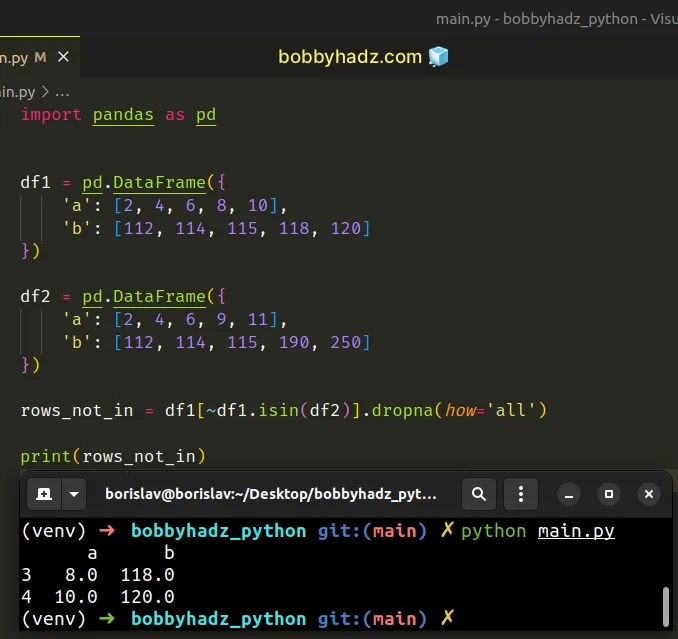
When the how argument of the dropna() method is set to "all", then if all
values are NA, the corresponding row or column is dropped.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: Length of values does not match length of index
- How to get the Memory size of a DataFrame in Pandas
- Pandas: Select distinct across multiple DataFrame columns
- Filter rows in a Pandas DataFrame using Regex
- Pandas: Element-wise logical NOT and logical OR operators
- Update a Pandas DataFrame while iterating over its rows
- Matplotlib: No artists with labels found to put in legend
- ValueError: If using all scalar values, you must pass index
- Pandas: How to Convert a Pivot Table to a DataFrame
- Pandas: Count the unique combinations of two Columns
- Python: Compare two CSV files and print the differences
- Pandas: Set number of max Rows and Cols shown in DataFrame
- RuntimeError: CUDA out of memory. Tried to allocate X MiB
- OSError: [E050] Can't find model 'en_core_web_sm'
- PyTorch: Trying to backward through the graph a second time
- Pandas: Unalignable boolean Series provided as indexer

