Pandas: DataFrame.reset_index() not working [Solved]
Last updated: Apr 12, 2024
Reading time·3 min

# Table of Contents
- Pandas: DataFrame.reset_index() not working [Solved]
- Set the drop argument to False to remove the additional column
- Resetting the index in place by mutating the original DataFrame
# Pandas: DataFrame.reset_index() not working [Solved]
The DataFrame.reset_index() might not work if you forget to assign the
resulting DataFrame to a variable.
By default, the method resets the DataFrame index and returns a new
DataFrame containing the results. It doesn't reset the index in place.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }, index=['A', 'B', 'C', 'D']) print(df) df = df.reset_index() print('-' * 50) print(df)
Running the code sample produces the following output.
name experience salary A Alice 1 175.1 B Bobby 3 180.2 C Carl 1 190.3 D Dan 7 205.4 -------------------------------------------------- index name experience salary 0 A Alice 1 175.1 1 B Bobby 3 180.2 2 C Carl 1 190.3 3 D Dan 7 205.4
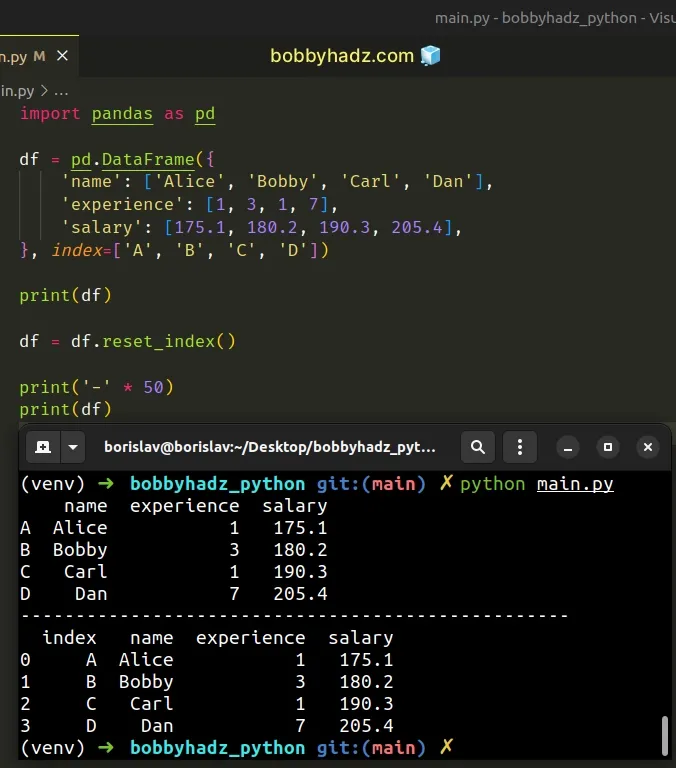
Notice that we assigned the result of calling the DataFrame.reset_index() method to a variable.
df = df.reset_index()
reset_index method resets the index of the DataFrame and returns the DataFrame with the new index (starting at 0).The method doesn't reset the DataFrame's index in place, so make sure to store the result in a variable.
# Set the drop argument to False to remove the additional column
By default, when you call the reset_index method, the current index of the
DataFrame gets added as a column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }, index=['A', 'B', 'C', 'D']) df = df.reset_index() # index name experience salary # 0 A Alice 1 175.1 # 1 B Bobby 3 180.2 # 2 C Carl 1 190.3 # 3 D Dan 7 205.4 print(df)
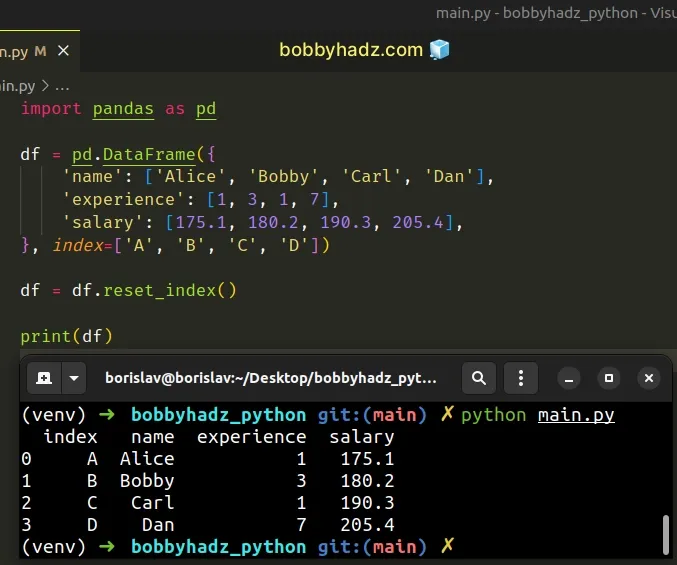
Notice that the DataFrame now has an index column with its previous index
values.
You can set the drop argument to True when calling reset_index if you want
to not insert the index column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }, index=['A', 'B', 'C', 'D']) df = df.reset_index(drop=True) # name experience salary # 0 Alice 1 175.1 # 1 Bobby 3 180.2 # 2 Carl 1 190.3 # 3 Dan 7 205.4 print(df)
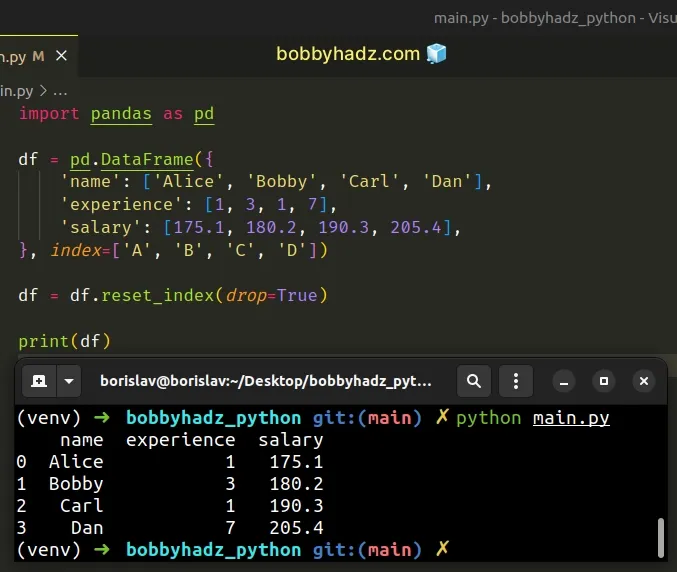
When the drop argument is set to True, the additional index column doesn't
get inserted.
# Resetting the index in place by mutating the original DataFrame
The previous calls to the reset_index() method return a new DataFrame with
the index reset.
However, you can set the inplace argument if you'd rather reset the index of
the original DataFrame and return None.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 1, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }, index=['A', 'B', 'C', 'D']) df.reset_index(drop=True, inplace=True) # name experience salary # 0 Alice 1 175.1 # 1 Bobby 3 180.2 # 2 Carl 1 190.3 # 3 Dan 7 205.4 print(df)
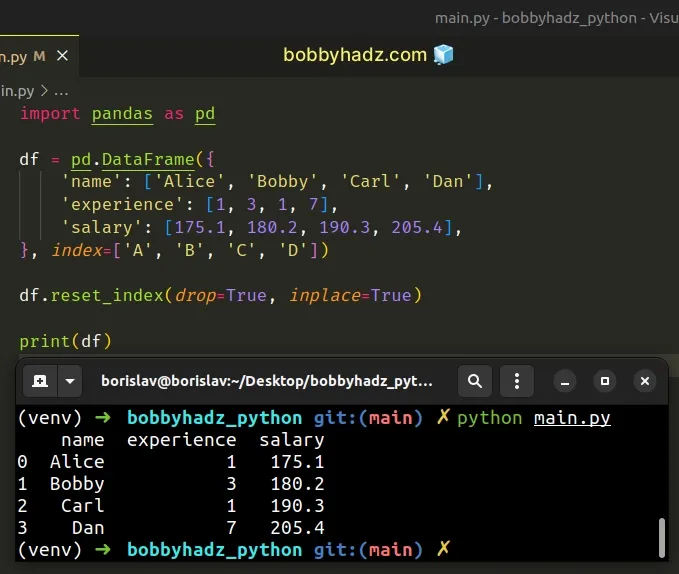
Notice that we didn't assign the result of calling reset_index to a variable.
inplace argument is set to True, the reset_index method returns None because it resets the DataFrame index in place via a mutation.There is a convention in Python that methods that mutate the original object
return None.
When using this approach, make sure to not assign the result of calling
reset_index to a variable because the variable would store None.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: Grouper for 'X' not 1-dimensional [Solved]
- Cannot subset columns with tuple with more than one element
- Pandas: Get Nth row or every Nth row in a DataFrame
- Pandas: Select first N or last N columns of DataFrame
- Matplotlib: No artists with labels found to put in legend
- Pandas: Setting column names when reading a CSV file
- Export a Pandas DataFrame to Excel without the Index
- Pandas: How to Convert a Pivot Table to a DataFrame
- Pandas: Count the unique combinations of two Columns
- PyTorch: Trying to backward through the graph a second time
- Pandas: Unalignable boolean Series provided as indexer

