Length mismatch: Expected axis has X elements, new values have Y elements
Last updated: Apr 11, 2024
Reading time·4 min

# Table of Contents
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- Assigning column names to an empty DataFrame
- Solving the error when reading CSV files
# ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
The Pandas "ValueError: Length mismatch: Expected axis has X elements, new
values have Y elements" occurs when the length of the column names you are
assigning to the DataFrame doesn't match the length of the columns in the
DataFrame.
To solve the error, make sure the length of the column names in the DataFrame
matches the length of the column names.
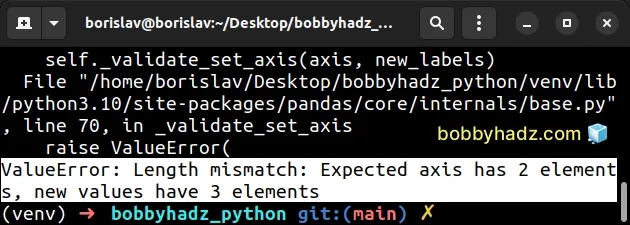
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame( { 'id': [112, 113, 114, 115], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], } ) # ⛔️ ValueError: Length mismatch: Expected axis has 2 elements, new values have 3 elements df.columns = ['id', 'first_name', 'salary']
The DataFrame in the example has 2 columns - id and name, however, we've
passed 3 column names to the
columns
list.
The expected axis has 2 elements (id and name) and the new values have 3
elements (id, first_name and salary).
One way to solve the error is to ensure the number of columns in the DataFrame
matches the number of columns in the list on the right.
import pandas as pd df = pd.DataFrame( { 'id': [112, 113, 114, 115], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], } ) df.columns = ['id', 'first_name'] # id first_name # 0 112 Alice # 1 113 Bobby # 2 114 Carl # 3 115 Dan print(df)
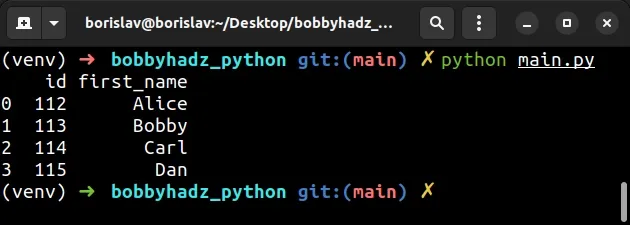
The DataFrame has 2 columns and the list on the right-hand side also has 2
columns, so the error is no longer raised.
You can use the len()
function to check that the length of the columns in the DataFrame matches the
length of the column names.
import pandas as pd df = pd.DataFrame( { 'id': [112, 113, 114, 115], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], } ) # ✅ Print the length of columns in DataFrame print(len(df.columns)) # 👉️ 2 column_names = ['id', 'first_name'] # ✅ Print the length of the column names print(len(column_names)) # 👉️ 2 df.columns = ['id', 'first_name'] # id first_name # 0 112 Alice # 1 113 Bobby # 2 114 Carl # 3 115 Dan print(df)
There has to be a match between the following 2 calls to len().
# ✅ Print the length of columns in DataFrame print(len(df.columns)) # 👉️ 2 # ✅ Print the length of the column names print(len(column_names)) # 👉️ 2
You can use the df.columns attribute if you need to print the columns in the
DataFrame.
import pandas as pd df = pd.DataFrame( { 'id': [112, 113, 114, 115], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], } ) # Index(['id', 'name'], dtype='object') print(df.columns)
The DataFrame has id and name columns.
You might have excluded one or more of your DataFrame columns somewhere in
your code.
import pandas as pd df = pd.DataFrame( { 'id': [112, 113, 114, 115], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], } ) df = df.drop(['id'], axis=1) # name # 0 Alice # 1 Bobby # 2 Carl # 3 Dan print(df) # 👇️ Index(['name'], dtype='object') print(df.columns) print(len(df.columns)) # 👉️ 1 df.columns = ['first_name'] # first_name # 0 Alice # 1 Bobby # 2 Carl # 3 Dan print(df)
The code sample uses the
DataFrame.drop() method to remove the
id column from the DataFrame.
After the column is removed, the DataFrame has only 1 column remaining.
Make sure the number of columns in the DataFrame matches the number of column
names in the list on the right.
# Assigning column names to an empty DataFrame
The error is also raised when you try to assign column names to an empty DataFrame.
import pandas as pd df = pd.DataFrame() print(len(df.columns)) # 👉️ 0 # ⛔️ ValueError: Length mismatch: Expected axis has 0 elements, new values have 2 elements df.columns = ['id', 'name']
We initialized the DataFrame as empty, so it has 0 columns.
Trying to overwrite its column names with a list containing 2 items causes the error.
One way to solve the error is to initialize the DataFrame with 2 columns using
numpy.empty().
import pandas as pd import numpy as np df = pd.DataFrame(np.empty((0, 2))) print(len(df.columns)) # 👉️ 2 df.columns = ['id', 'name'] print(df.columns) # 👉️ Index(['id', 'name'], dtype='object') print(len(df.columns)) # 👉️ 2
Make sure to initialize the DataFrame with the correct number of columns (the
example uses 2 columns).
The numpy.empty() method returns a new array of the specified shape and type, without initializing entries.
If you don't want to use NumPy, use the range class instead.
import pandas as pd df = pd.DataFrame(columns=range(2)) print(len(df.columns)) # 👉️ 2 df.columns = ['id', 'name'] print(df.columns) # 👉️ Index(['id', 'name'], dtype='object') print(len(df.columns)) # 👉️ 2
# Solving the error when reading CSV files
You might also get the error when setting the index_col argument to 0 when
reading CSV files with
pandas.read_csv.
df = pd.read_csv( 'data.csv', index_col=0, # 👈️ header=None, skiprows=[0, 1, 2] )
The index_col argument determines the column(s) to use as the row labels of
the DataFrame.
Try to set the index_col argument to None instead and see if the error
resolves.
df = pd.read_csv( 'data.csv', index_col=None, # 👈️ header=None, skiprows=[0, 1, 2] )
When index_col is set to None, a separate numerical index is assigned.
None is the default value for the index_col keyword argument.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- How to replace None with NaN in Pandas DataFrame
- AttributeError module 'pandas' has no attribute 'DataFrame'
- ModuleNotFoundError: No module named 'pandas' in Python
- FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version
- You are trying to merge on int64 and object columns [Fixed]
- Copy a column from one DataFrame to another in Pandas
- ValueError: cannot reindex on an axis with duplicate labels
- IndexError: single positional indexer is out-of-bounds [Fix]
- Python OSError: [Errno 98] Address already in use [Solved]
- Count number of non-NaN values in each column of DataFrame
- Index(...) must be called with a collection of some kind
- ValueError: Shape of passed values is X, indices imply Y
- Concatenate strings from multiple rows with Pandas GroupBy
- ValueError: Grouper for 'X' not 1-dimensional [Solved]
- Check if all values in a Column are Equal in Pandas

