Pandas: GroupBy columns with NaN (missing) values
Last updated: Apr 12, 2024
Reading time·3 min

# Table of Contents
- Pandas: GroupBy columns with NaN (missing) values
- Pandas: GroupBy columns with NaN (missing) values using fillna()
- Pandas: GroupBy columns with NaN (missing) values using astype()
# Pandas: GroupBy columns with NaN (missing) values
To GroupBy columns with NaN (missing) values in a Pandas DataFrame:
- Call the
groupby()method on theDataFrame. - By default, the method will exclude the
NaNvalues from the result. - If you want to include the
NaNvalues in the result, set thedropnaargument toFalse.
import pandas as pd import numpy as np df = pd.DataFrame({ 'ID': [1, 1, 1, 2, 2, 2], 'Animal': ['Cat', 'Cat', np.nan, 'Dog', 'Dog', np.nan], 'Max Speed': [25, 35, 45, 55, 65, 75] }) # 👇️ without NA values print(df.groupby(['Animal']).mean()) print('-' * 50) # 👇️ with NA values print(df.groupby(['Animal'], dropna=False).mean())
Running the code sample produces the following output.
ID Max Speed Animal Cat 1.0 30.0 Dog 2.0 60.0 -------------------------------------------------- ID Max Speed Animal Cat 1.0 30.0 Dog 2.0 60.0 NaN 1.5 60.0
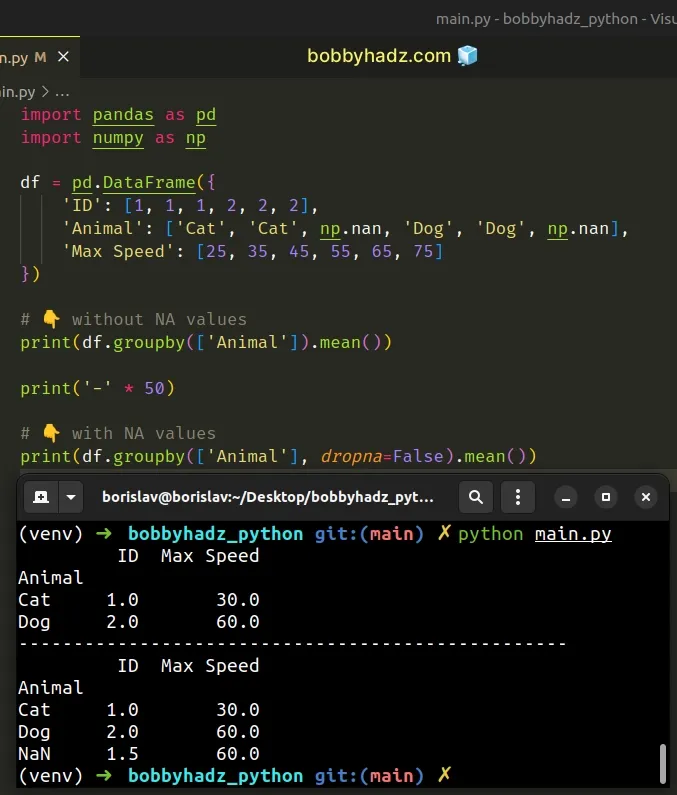
The
DataFrame.groupby()
method groups the DataFrame by one or more columns.
By default, the dropna argument is set to True.
If the group keys contain NA values and dropna is set to True, the NA
values with the row/column are dropped.
# 👇️ without NA values # ID Max Speed # Animal # Cat 1.0 30.0 # Dog 2.0 60.0 print(df.groupby(['Animal']).mean())
When the dropna argument is set to False, the NA values are treated as a key
in the groups.
# 👇️ with NA values # ID Max Speed # Animal # Cat 1.0 30.0 # Dog 2.0 60.0 # NaN 1.5 60.0 print(df.groupby(['Animal'], dropna=False).mean())
# Pandas: GroupBy columns with NaN (missing) values using fillna()
Alternatively, you can group the columns with NaN (missing) values by using the
fillna() method to replace them before calling groupby().
import pandas as pd import numpy as np df = pd.DataFrame({ 'ID': [1, 1, 1, 2, 2, 2], 'Animal': ['Cat', 'Cat', np.nan, 'Dog', 'Dog', np.nan], 'Max Speed': [25, 35, 45, 55, 65, 75] }) # ID Max Speed # Animal # Cat 1.0 30.0 # Dog 2.0 60.0 # NOT_AVAILABLE 1.5 60.0 print(df.fillna('NOT_AVAILABLE').groupby(['Animal']).mean())
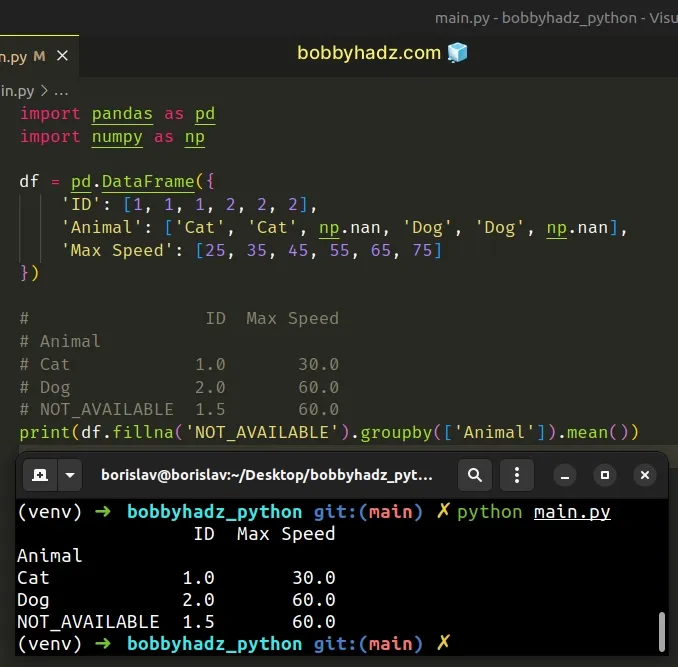
The DataFrame.fillna() method fills the NA/NaN values.
The value we called the method with can be any placeholder that suits your use
case (it doesn't have to be the "NOT_AVAILABLE" string).
fillna() method with a value such as -1.Once we've filled in the NA values, we can call the groupby() method without
running into any issues.
You can also call the fillna() method separately, before calling groupby().
import pandas as pd import numpy as np df = pd.DataFrame({ 'ID': [1, 1, 1, 2, 2, 2], 'Animal': ['Cat', 'Cat', np.nan, 'Dog', 'Dog', np.nan], 'Max Speed': [25, 35, 45, 55, 65, 75] }) df.fillna('NOT_AVAILABLE', inplace=True) # ID Max Speed # Animal # Cat 1.0 30.0 # Dog 2.0 60.0 # NOT_AVAILABLE 1.5 60.0 print(df.groupby(['Animal']).mean())
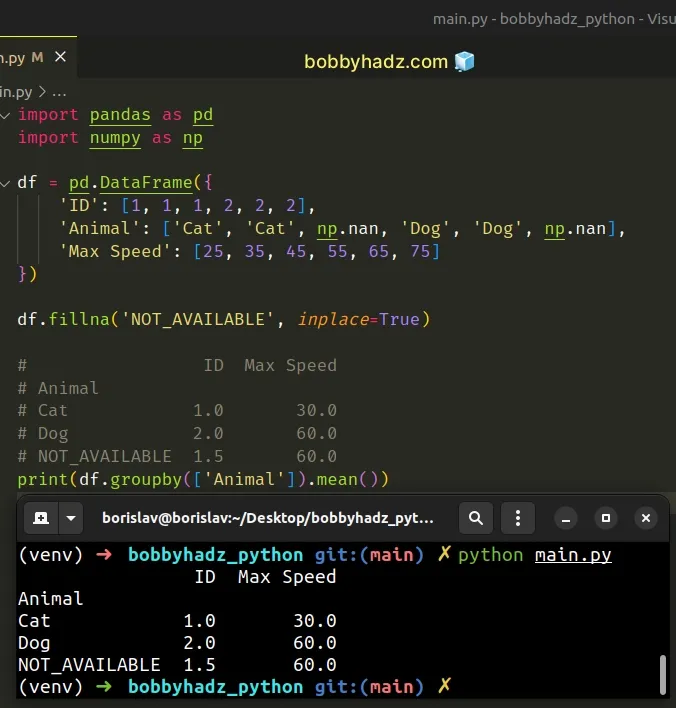
When the inplace argument is set to True, the fillna() method replaces the
NaN values in place (mutates the original DataFrame).
# Pandas: GroupBy columns with NaN (missing) values using astype()
Alternatively, you can use the
DataFrame.astype()
method to convert the values in the column to strings (including the NaN
values) before calling groupby().
import pandas as pd import numpy as np df = pd.DataFrame({ 'ID': [1, 1, 1, 2, 2, 2], 'Animal': ['Cat', 'Cat', np.nan, 'Dog', 'Dog', np.nan], 'Max Speed': [25, 35, 45, 55, 65, 75] }) df['Animal'] = df['Animal'].astype(str) # ID Max Speed # Animal # Cat 1.0 30.0 # Dog 2.0 60.0 # nan 1.5 60.0 print(df.groupby(['Animal']).mean())
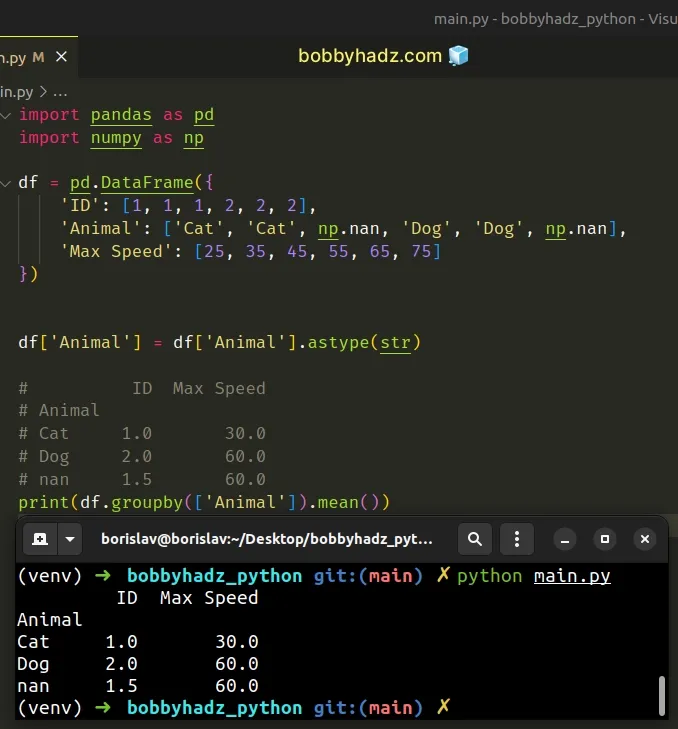
We used the DataFrame.astype() method to convert all values in the "Animal"
column to strings (including the NaN values).
Once the column contains string values, we can call the groupby() method on
it.
I've also written an article on how to replace None with NaN in a Pandas DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: Drop columns if Name contains a given String
- Pandas: How to get the Max and Min Dates in a DataFrame
- Pandas SpecificationError: nested renamer is not supported
- Pandas: Convert a DataFrame to a List of Dictionaries
- First argument must be an iterable of pandas objects [Fix]
- ValueError: Index contains duplicate entries, cannot reshape

