ValueError: Index contains duplicate entries, cannot reshape
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- ValueError: Index contains duplicate entries, cannot reshape
- Using the DataFrame.pivot_table() method with the aggfunc argument
- Reset the index before calling DataFrame.pivot_table
- Using DataFrame.groupby() method to solve the error
- Removing the duplicate entries to solve the error
# ValueError: Index contains duplicate entries, cannot reshape
The Pandas "ValueError: Index contains duplicate entries, cannot reshape"
occurs when you call the pivot() method on a DataFrame that contains
duplicate values with the same index.
To solve the error, either aggregate the duplicates or reset the index before
calling pivot_table().
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) # ⛔️ ValueError: Index contains duplicate entries, cannot reshape df = df.pivot(index='id', columns='name', values='salary')
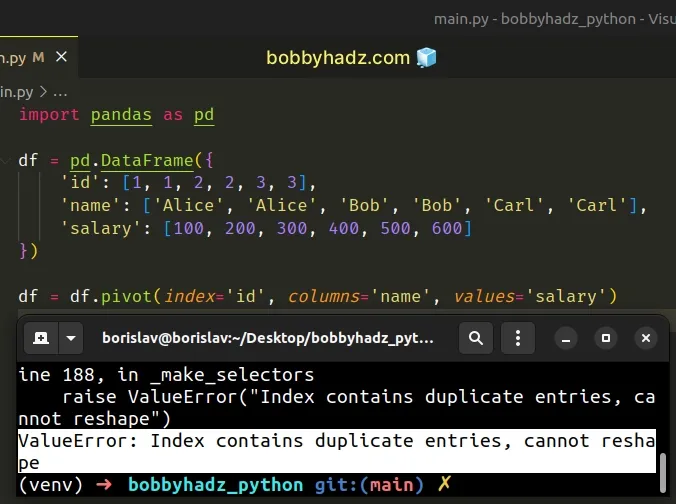
Notice that the DataFrame on which we called the
pivot
method contains duplicate values with the same index.
We cannot reshape a DataFrame organized by index/column values if the
specified index and column values contain duplicates.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) # id name salary # 0 1 Alice 100 # 1 1 Alice 200 # 2 2 Bob 300 # 3 2 Bob 400 # 4 3 Carl 500 # 5 3 Carl 600 print(df)
# Using the DataFrame.pivot_table() method with the aggfunc argument
If you want to aggregate the duplicate values, use the
DataFrame.pivot_table()
method with the aggfunc argument.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) df = df.pivot_table( index='id', columns='name', values='salary', aggfunc='sum' ) # name Alice Bob Carl # id # 1 300.0 NaN NaN # 2 NaN 700.0 NaN # 3 NaN NaN 1100.0 print(df)
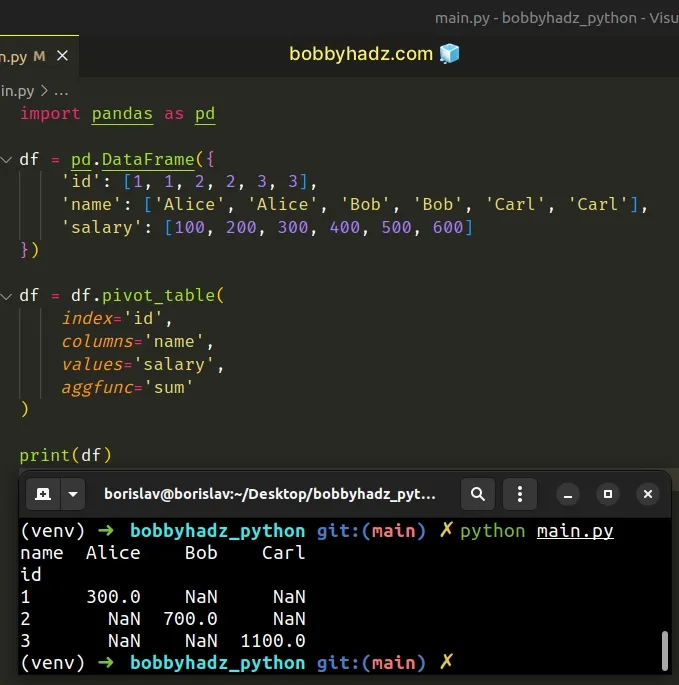
The DataFrame.pivot_table() method creates a spreadsheet-style pivot table as
a DataFrame.
The method takes an optional aggfunc argument that you can set to an
aggregation function.
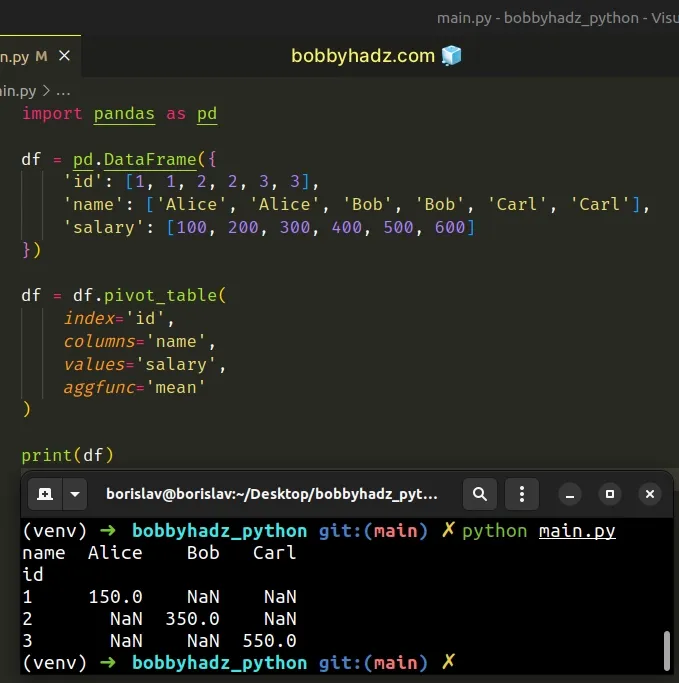
By default, the aggfunc argument is set to "mean".
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) df = df.pivot_table( index='id', columns='name', values='salary', aggfunc='mean' ) # name Alice Bob Carl # id # 1 150.0 NaN NaN # 2 NaN 350.0 NaN # 3 NaN NaN 550.0 print(df)
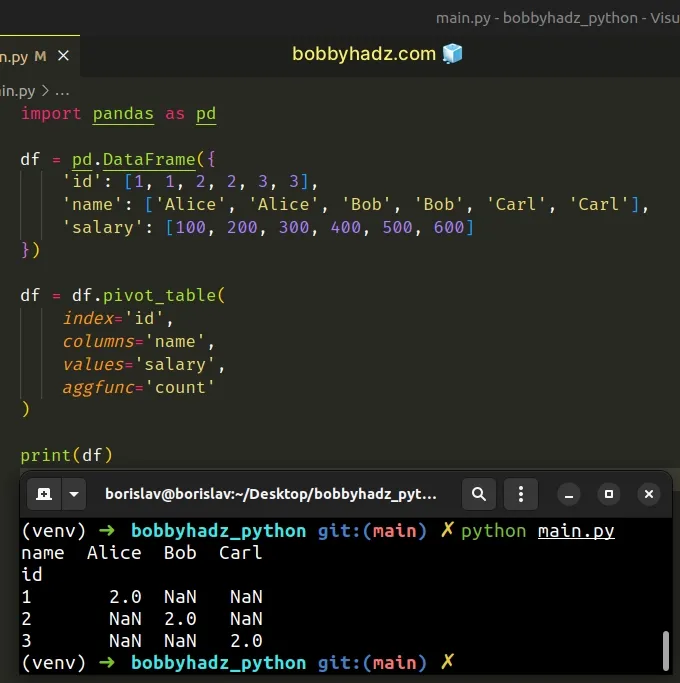
However, you can use other function names, e.g. "count".
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) df = df.pivot_table( index='id', columns='name', values='salary', aggfunc='count' ) # name Alice Bob Carl # id # 1 2.0 NaN NaN # 2 NaN 2.0 NaN # 3 NaN NaN 2.0 print(df)
# Reset the index before calling DataFrame.pivot_table
You can also solve the error by resetting the index before calling DataFrame.pivot_table().
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) df = df.reset_index().pivot_table( index='id', columns='name', values='salary', aggfunc='mean' ) # name Alice Bob Carl # id # 1 150.0 NaN NaN # 2 NaN 350.0 NaN # 3 NaN NaN 550.0 print(df)
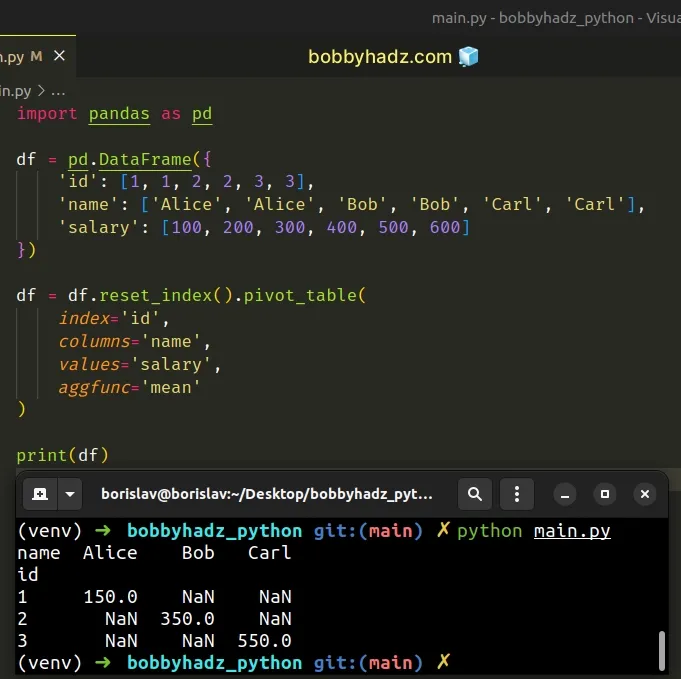
The DataFrame.reset_index()
method resets the index of the DataFrame.
# Using DataFrame.groupby() method to solve the error
You can also use the DataFrame.groupby() method to solve the error.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) df = df.groupby(['id', 'name'])['salary'].mean().unstack(-1) # name Alice Bob Carl # id # 1 150.0 NaN NaN # 2 NaN 350.0 NaN # 3 NaN NaN 550.0 print(df)
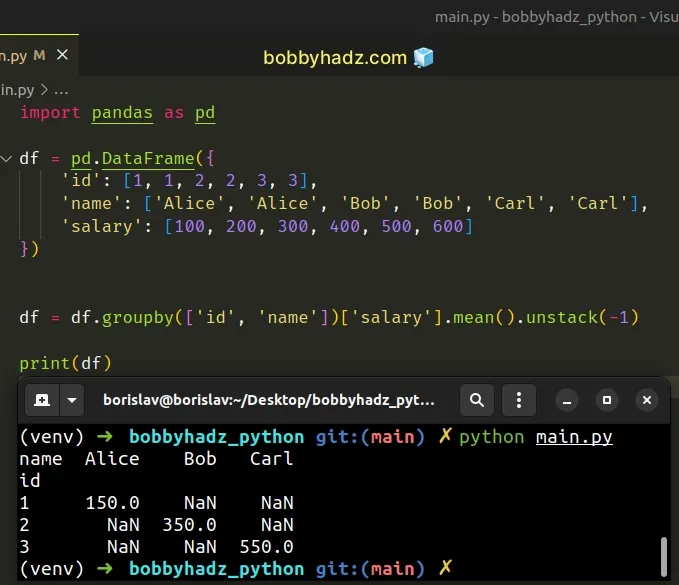
We used the DataFrame.groupby() method to group the DataFrame by the id
and name columns.
The next step is to select the salary column on the DataFrameGroupBy object
and call the mean() method.
The unstack() method (also known as pivot) unstacks a Series with MultiIndex
to produce a DataFrame.
# Removing the duplicate entries to solve the error
You can also remove the duplicate rows to solve the error.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bob', 'Bob', 'Carl', 'Carl'], 'salary': [100, 200, 300, 400, 500, 600] }) without_duplicates = df.drop_duplicates(['id', 'name'], keep='first') df = without_duplicates.pivot(index='id', columns='name', values='salary') print(df)
Running the code sample produces the following output.
name Alice Bob Carl id 1 100.0 NaN NaN 2 NaN 300.0 NaN 3 NaN NaN 500.0
The
DataFrame.drop_duplicates()
method returns a DataFrame with the duplicate rows removed.
The first argument the method takes is a sequence of column names to be considered when removing duplicates.
We only removed the duplicates across the id and name columns, keeping the
first value.
We can then call the pivot() method without any issues because the DataFrame
doesn't contain duplicate values with the same index.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

