Pandas: Find an element's Index in Series [7 Ways]
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Pandas: Find an element's Index in Series
- Making sure the specified element exists in the Series with try/except
- Pandas: Find an element's Index in Series using Index() class
- Pandas: Find an element's Index in a Series using where()
- Pandas: Find an element's Index in a Series using argmax()
- Pandas: Find an element's Index in a Series using list()
# Pandas: Find an element's Index in Series
To find an element's index in a Series in Pandas:
- Use bracket notation to check for equality.
- The expression will return a new
Seriescontaining the element's index in the first position. - Use the
indexattribute to get the first element in theSeries.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) # 2 5 # dtype: int64 print(series[series == 5]) print('-' * 50) index_of_5 = series[series == 5].index[0] print(index_of_5) # 👉️ 2
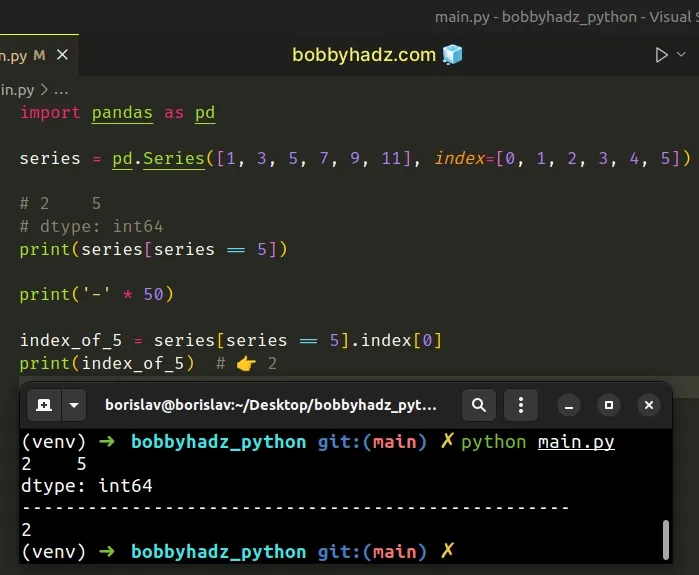
We first used bracket notation to get a new Series object that contains the
element's position at index 0.
# 2 5 # dtype: int64 print(series[series == 5])
The next step is to use the Series.index property to get the first element.
index_of_5 = series[series == 5].index[0] print(index_of_5) # 👉️ 2
This approach also works when there are multiple occurrences of the same value
in the Series.
import pandas as pd series = pd.Series([5, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) # 0 5 # 2 5 # dtype: int64 print(series[series == 5]) print('-' * 50) print(series[series == 5].index[0]) # 👉️ 0 print(series[series == 5].index[1]) # 👉️ 2
If you need to convert the Series of indices to a list, use the
list class.
import pandas as pd series = pd.Series([5, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) # 👇️ [0, 2] print(list(series[series == 5].index))
# Making sure the specified element exists in the Series with try/except
When using this approach, you have to make sure the specified element exists in
the Series, otherwise, you'd get an IndexError.
You can use a try/except statement if you need to handle the potential error.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) # Series([], dtype: int64) print(series[series == 100]) print('-' * 50) try: index_of_100 = series[series == 100].index[0] print(index_of_100) except IndexError: # 👇️ this runs print('The given element does NOT exist in the Series')
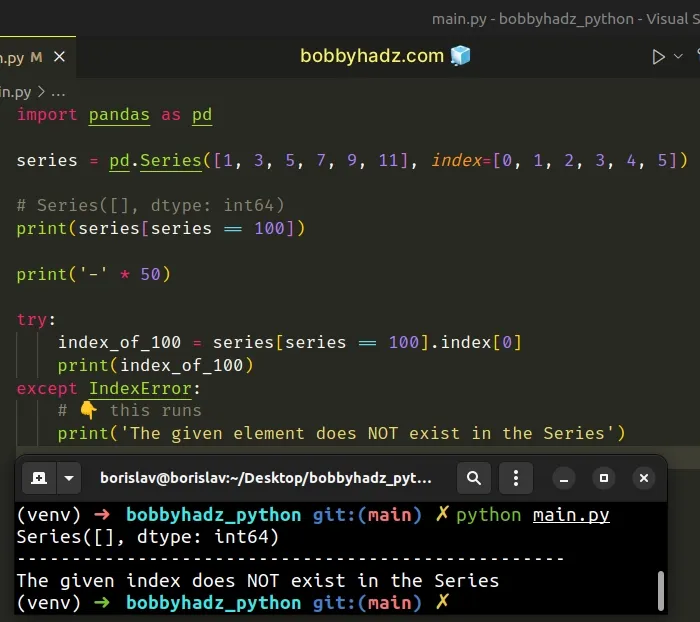
The Series in the example doesn't contain a 100 value, so the expression
returns a new, empty Series object.
Trying to access the empty Series object at index 0 causes an error, so we
wrapped the code in a try/except block.
If the given element doesn't exist, the except block runs.
# Pandas: Find an element's Index in Series using Index() class
You can also find an element's index in a Series by converting the Series to
an Index
object and using the
get_loc()
method.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) index_of_5 = pd.Index(series).get_loc(5) print(index_of_5) # 👉️ 2 print(series[index_of_5]) # 👉️ 5
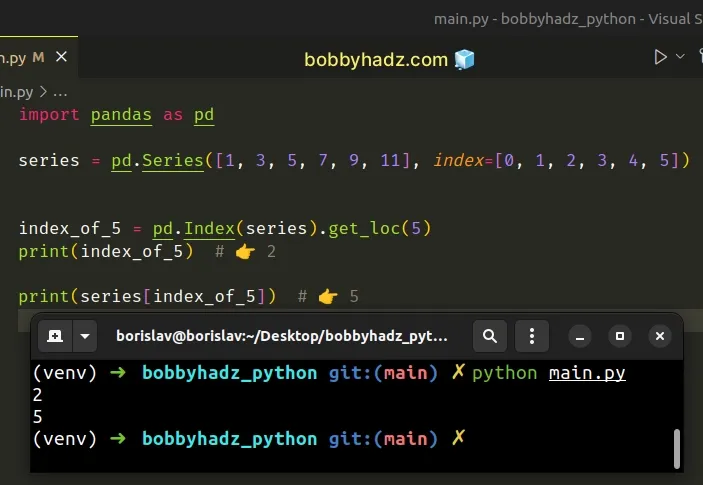
We used the Index() constructor to convert the Series to an Index object.
Index objects are immutable sequences that are used for indexing and alignment.
Index objects have a get_loc method that returns the index of the supplied value.
If the given value doesn't exist in the Series, you would get a
KeyError exception.
You can use a try/except block to handle the potential error.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) try: index_of_100 = pd.Index(series).get_loc(100) print(index_of_100) except KeyError: # 👇️ This runs print('The given value does NOT exist in the Series')
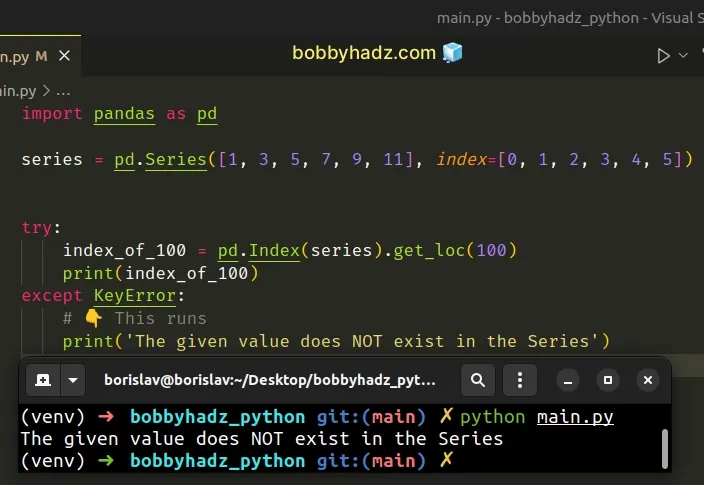
If there are multiple occurrences of the same value in the Series, the
get_loc method returns a boolean array.
import pandas as pd series = pd.Series([5, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) index_of_5 = pd.Index(series).get_loc(5) # 👇️ [ True False True False False False] print(index_of_5) print(series[index_of_5].index[0]) # 👉️ 0 print(series[index_of_5].index[1]) # 👉️ 2
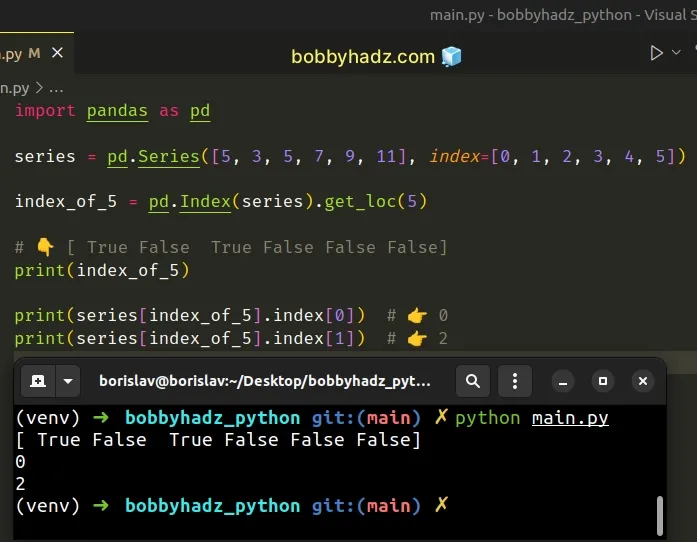
The array contains True values for the matching elements.
# Pandas: Find an element's Index in a Series using where()
You can also use the
Series.where()
method to find an element's index in a Series.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) index_of_5 = series.where(series == 5).first_valid_index() print(index_of_5) # 👉️ 2
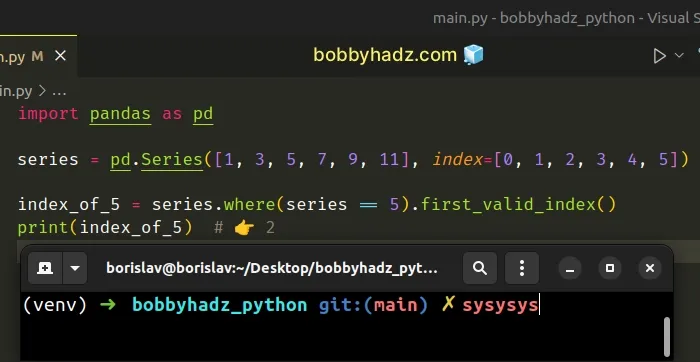
The Series.where method replaces the values where the given condition is
False.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) # 0 NaN # 1 NaN # 2 5.0 # 3 NaN # 4 NaN # 5 NaN # dtype: float64 print(series.where(series == 5))
The last step is to use the first_valid_index method to get the index of the first non-NA value.
If the given value is not in the Series, the first_valid_index() method will
return None.
You can use an if statement if you need to
check if the variable is or is not None.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) index_of_100 = series.where(series == 100).first_valid_index() print(index_of_100) # 👉️ None if index_of_100 is not None: print(index_of_100) else: # 👇️ this runs print('The supplied value is NOT in the Series')
The supplied value doesn't exist in the Series, so None is returned.
# Pandas: Find an element's Index in a Series using argmax()
You can also use the
Series.argmax()
method to find an element's index in a Series.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) index_of_5 = (series == 5).argmax() print(index_of_5) # 👉️ 2
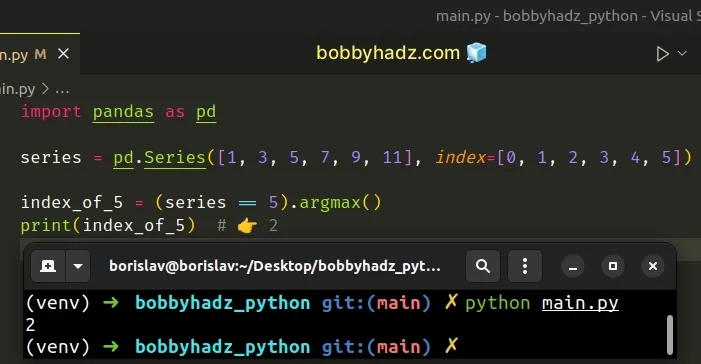
The Series.argmax() method returns the index of the largest value in the
Series.
We first used a condition to get a boolean Series that contains a True value
for the item that meets the condition.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) # 0 False # 1 False # 2 True # 3 False # 4 False # 5 False # dtype: bool print(series == 5)
True values get converted to 1 and False values get converted to 0, so the
argmax() method returns the index of the True value.
# Pandas: Find an element's Index in a Series using list()
You can also convert the Series to a list and use the list.index() method
to find an element's index in a Series.
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) index_of_5 = list(series).index(5) print(index_of_5) # 👉️ 2
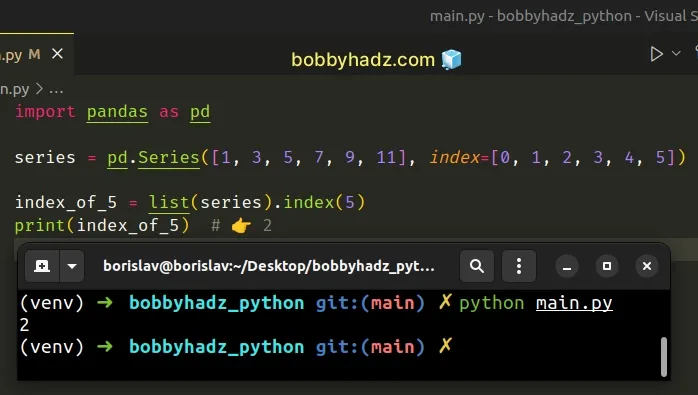
We first used the list() class to convert the Series to a list.
This enables us to use the list.index() method.
The list.index() method returns the first index of the supplied value.
If the value doesn't exist in the list, a ValueError is raised.
You can use a try/except block if you need to handle the potential error.
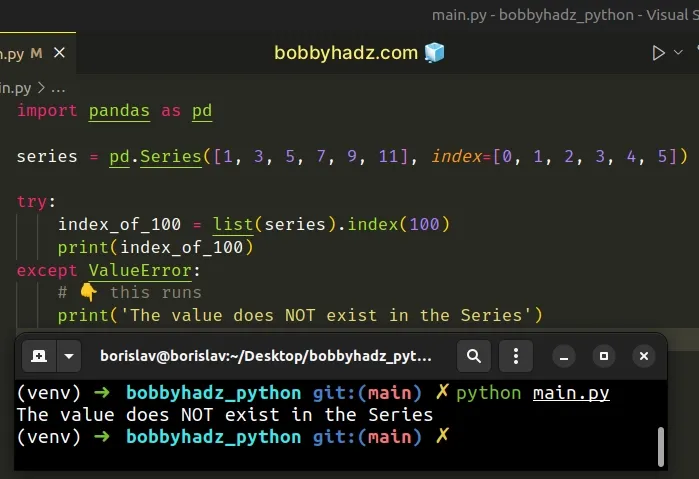
import pandas as pd series = pd.Series([1, 3, 5, 7, 9, 11], index=[0, 1, 2, 3, 4, 5]) try: index_of_100 = list(series).index(100) print(index_of_100) except ValueError: # 👇️ this runs print('The value does NOT exist in the Series')
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: How to get the Max and Min Dates in a DataFrame
- Pandas SpecificationError: nested renamer is not supported
- Pandas: Convert a DataFrame to a List of Dictionaries
- Pandas: GroupBy columns with NaN (missing) values
- NumPy: Get the indices of the N largest values in an Array
- ValueError: If using all scalar values, you must pass index
- ValueError: Index contains duplicate entries, cannot reshape

