How to Create a Set from a Series in Pandas [5 Ways]
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- How to Create a Set from a Series in Pandas
- How to convert a Series from a DataFrame to a Set
- Passing the result of calling unique() to the set() constructor
- Create a Set from a Series in Pandas using a for loop
# How to Create a Set from a Series in Pandas
To create a Set from a Series in Pandas:
- Use the
Series.unique()method if you need to get an array containing the unique values in theSeries. - Use the
set()class if you need to convert theSeriesto asetobject.
import pandas as pd s = pd.Series([1, 2, 3, 3, 1, 4, 5, 5]) unique = s.unique() print(unique) # 👉️ [1 2 3 4 5] # 👇️ <class 'numpy.ndarray'> print(type(unique)) a_set = set(unique) print(a_set) # 👉️ {1, 2, 3, 4, 5}
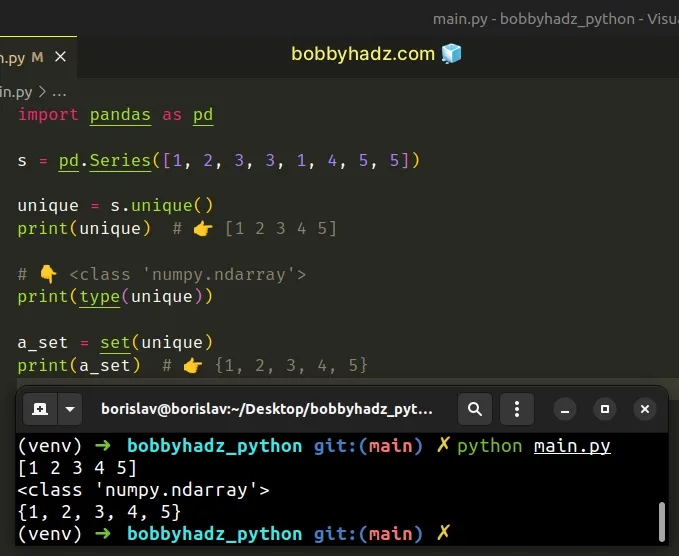
The
Series.unique()
method returns the unique values contained in a Series object.
import pandas as pd s = pd.Series([1, 2, 3, 3, 1, 4, 5, 5]) unique = s.unique() print(unique) # 👉️ [1 2 3 4 5]
The unique() method returns the unique values as a NumPy array.
If you need to get the result as a set, you can use the set() constructor
instead.
import pandas as pd s = pd.Series([1, 2, 3, 3, 1, 4, 5, 5]) a_set = set(s) print(a_set) # 👉️ {1, 2, 3, 4, 5} print(type(a_set)) # 👉️ <class 'set'>
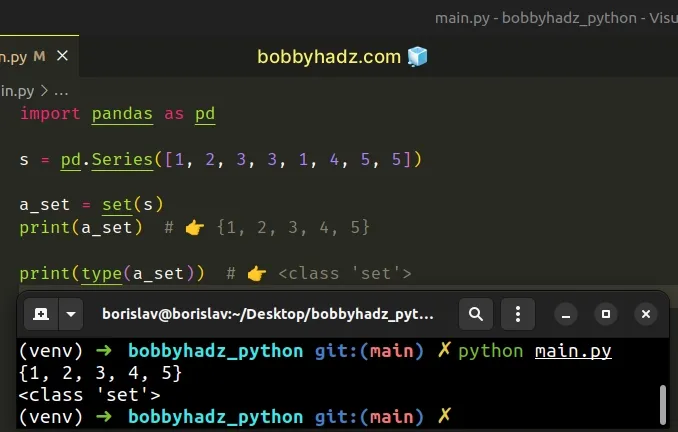
Set objects are an unordered, unique collection of elements.
# How to convert a Series from a DataFrame to a Set
If you need to convert a Series in a DataFrame to a Set, access it before
using the unique() method or set() constructor.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 100, 100, 200] }) unique = df['salary'].unique() print(unique) # 👉️ [100 200] a_set = set(df['salary']) print(a_set) # 👉️ {200, 100}
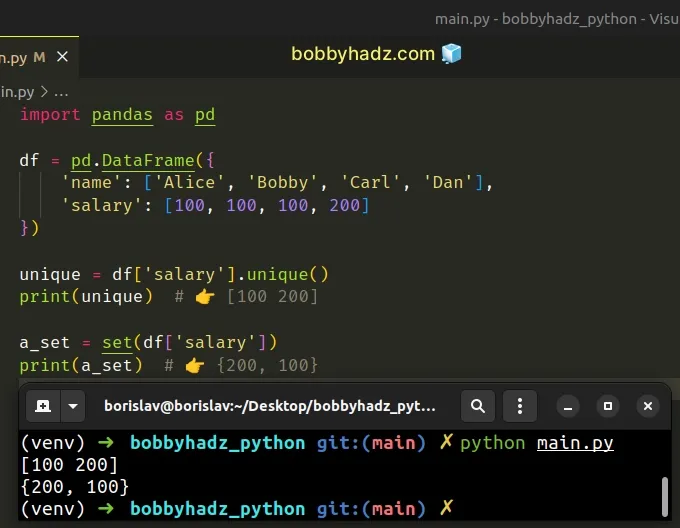
We used bracket notation [] to access the Series before calling the
unique() method.
If you need to get an array containing the unique values in the Series, the
unique() method will suffice.
If you need to get a set object, use the set() constructor.
set are not ordered.# Passing the result of calling unique() to the set() constructor
If you work with large Series objects, it is faster to:
- Use the
unique()method to remove the duplicates from theSeries. - Pass the
Seriesof unique elements to theset()constructor.
import pandas as pd s = pd.Series([1, 2, 3, 3, 1, 4, 5, 5]) a_set = set(s.unique()) print(a_set) # 👉️ {1, 2, 3, 4, 5}
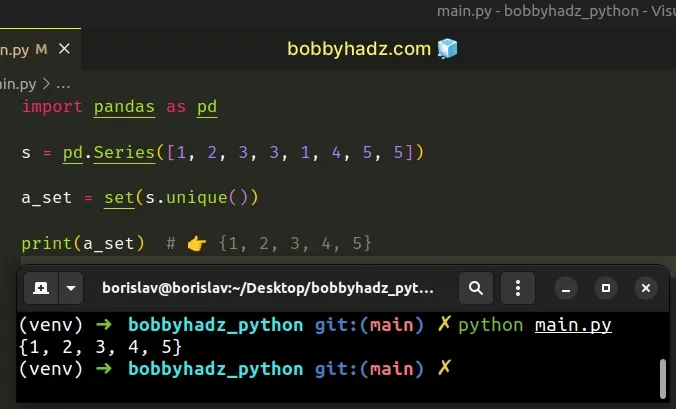
We first remove the duplicates from the Series using unique() and pass the
Series of unique values to the set().
This will be more performant for large Series objects.
# Create a Set from a Series in Pandas using a for loop
You can also use a basic for loop to create a
set from a Series in Pandas.
import pandas as pd s = pd.Series([1, 2, 3, 3, 1, 4, 5, 5]) a_set = set() for element in s.unique(): a_set.add(element) print(a_set) # 👉️ {1, 2, 3, 4, 5}
We used a for loop to iterate over the unique values in the Series and used
the set.add()
method to add each element to the set.
You don't necessarily have to call the unique() method to achieve the same
result.
import pandas as pd s = pd.Series([1, 2, 3, 3, 1, 4, 5, 5]) a_set = set() for element in s: a_set.add(element) print(a_set) # 👉️ {1, 2, 3, 4, 5}
The code sample achieves the same result because set objects only store unique
elements, so no duplicates can get added to the set.
In other words, adding a duplicate value to a set is a no-op (no operation).
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: Element-wise logical NOT and logical OR operators
- Update a Pandas DataFrame while iterating over its rows
- Pandas: Convert a DataFrame to a List of Dictionaries
- Pandas: GroupBy columns with NaN (missing) values
- Panda: Using fillna() with specific columns in a DataFrame
- Pandas: Split a Column of Lists into Multiple Columns
- First argument must be an iterable of pandas objects [Fix]
- Pandas: Setting column names when reading a CSV file
- Export a Pandas DataFrame to Excel without the Index
- How to Split a Pandas DataFrame into Chunks
- Annotate Bars in Barplot with Pandas and Matplotlib
- Pandas: Create a Tuple from two DataFrame Columns
- Disable the TOKENIZERS_PARALLELISM=(true | false) warning
- RuntimeError: Expected scalar type Float but found Double
- Pandas: Convert timezone-aware DateTimeIndex to naive timestamp
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- How to read a .mat (Matplotlib) file in Python
- Python: How to center the Title in Plotly
- ValueError: Expected object or value with
pd.read_json() - Mixing dicts with non-Series may lead to ambiguous ordering
- Must have equal len keys and value when setting with iterable
- TypeError: '(slice(None, None, None), 0)' is an invalid key
- ERROR: YouTube said: Unable to extract video data [Solved]
- SyntaxError: future feature annotations is not defined

