Drop Unnamed: 0 columns from a Pandas DataFrame in Python
Last updated: Apr 11, 2024
Reading time·6 min

# Table of Contents
- Drop Unnamed: 0 columns from a Pandas DataFrame in Python
- Removing Unnamed: 0 columns by explicitly setting the index column
- Removing Unnamed: 0 columns by using str.match()
- Using df.drop() to drop the Unnamed columns
- Drop Unnamed:0 columns by renaming them
# Drop Unnamed: 0 columns from a Pandas DataFrame in Python
You will most commonly get Unnamed: 0 columns in a Pandas DataFrame when it
is saved with an index in a CSV file.
To resolve the issue, set the index argument to False when saving the
DataFrame to a CSV file.
For example, running the following code sample produces an Unnamed: 0 column.
import pandas as pd df = pd.DataFrame( [[1, 2, 3], [4, 5, 6], [7, 8, 8]], columns=['bobby', 'hadz', 'com'] ) print(df) df.to_csv('data.csv', encoding='utf-8') df = pd.read_csv('data.csv', sep=',', encoding='utf-8') print('-' * 50) print(df)
Here is the output of running the code sample:
bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 -------------------------------------------------- Unnamed: 0 bobby hadz com 0 0 1 2 3 1 1 4 5 6 2 2 7 8 8
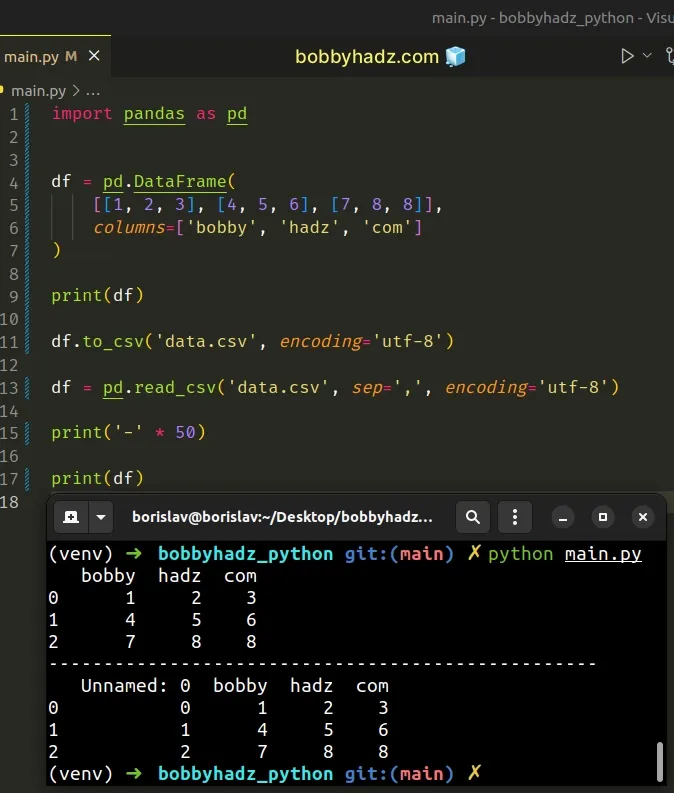
Notice that we have an Unnamed: 0 column.
This is caused by saving our CSV file with an unnamed index.
You can resolve the issue by setting the index argument to False when
calling
DataFrame.to_csv.
import pandas as pd df = pd.DataFrame( [[1, 2, 3], [4, 5, 6], [7, 8, 8]], columns=['bobby', 'hadz', 'com'] ) print(df) # ✅ Set index to False df.to_csv('data.csv', encoding='utf-8', index=False) df = pd.read_csv('data.csv', sep=',', encoding='utf-8') print('-' * 50) print(df)
Running the code sample produces the following output.
bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 -------------------------------------------------- bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8
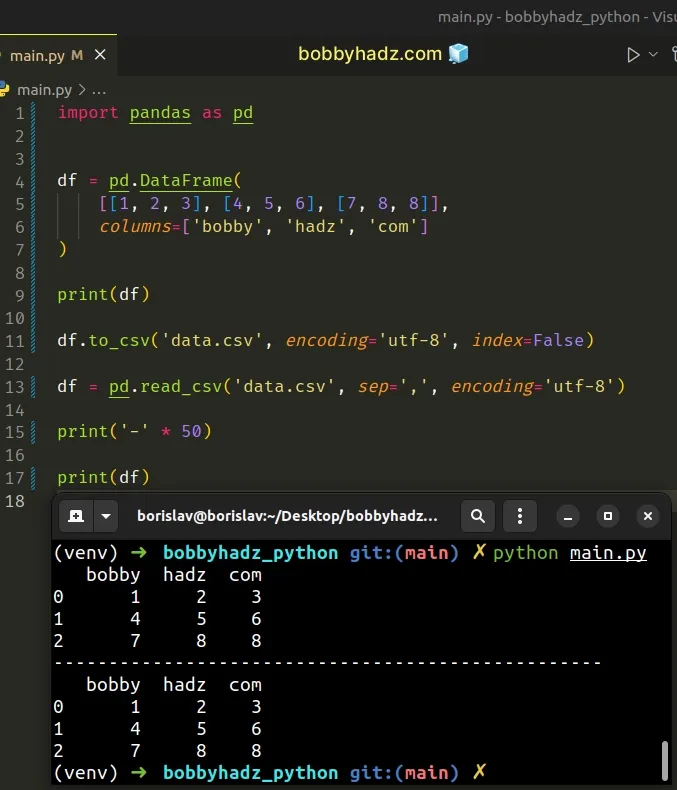
Notice that we don't have an Unnamed: 0 column anymore.
The index argument defaults to True.
When the argument is set to False, the row names (indices) are not written.
Note: the issue also occurs when you end each row with a comma when writing your data to a CSV file. Make sure you don't have any trailing commas.
# Removing Unnamed: 0 columns by explicitly setting the index column
You can also explicitly set the index_col argument in the call to
pandas.read_csv to
resolve the issue.
import pandas as pd df = pd.DataFrame( [[1, 2, 3], [4, 5, 6], [7, 8, 8]], columns=['bobby', 'hadz', 'com'] ) print(df) df.to_csv('data.csv', encoding='utf-8') # ✅ Explicitly set index_col to 0 df = pd.read_csv( 'data.csv', sep=',', encoding='utf-8', index_col=[0] ) print('-' * 50) print(df)
Running the code sample produces the following output.
bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 -------------------------------------------------- bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8
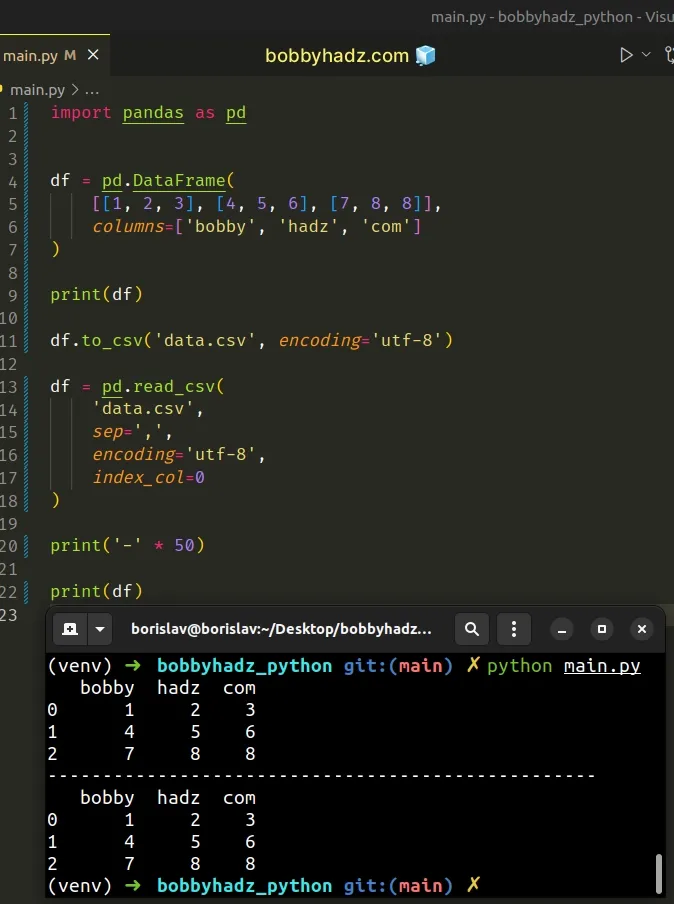
The index_col argument determines the column that is used as the row label of
the DataFrame.
We used a column index of 0 to set the first column as the index.
# ✅ explicitly set index_col to 0 df = pd.read_csv( 'data.csv', sep=',', encoding='utf-8', index_col=[0] )
This should be your preferred approach when you don't have access to the code that saves the DataFrame to a CSV file.
# Removing Unnamed: 0 columns by using str.match()
You can also use the str.match() method to drop the Unnamed columns from your DataFrame.
The method enables us to determine whether each string starts with a match of a regular expression.
import pandas as pd df = pd.DataFrame( [[1, 2, 3], [4, 5, 6], [7, 8, 8]], columns=['bobby', 'hadz', 'com'] ) print(df) df.to_csv('data.csv', encoding='utf-8') df = pd.read_csv( 'data.csv', sep=',', encoding='utf-8', ) print('-' * 50) print(df) # 👇️ Index(['Unnamed: 0', 'bobby', 'hadz', 'com'], dtype='object') print(df.columns) print('-' * 50) df = df.loc[:, ~df.columns.str.match('Unnamed')] print(df) # 👇️ Index(['bobby', 'hadz', 'com'], dtype='object') print(df.columns)
Running the code sample produces the following output.
bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 -------------------------------------------------- Unnamed: 0 bobby hadz com 0 0 1 2 3 1 1 4 5 6 2 2 7 8 8 Index(['Unnamed: 0', 'bobby', 'hadz', 'com'], dtype='object') -------------------------------------------------- bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 Index(['bobby', 'hadz', 'com'], dtype='object')
We used the str.match() method to match all columns that start with the string
Unnamed.
The matching columns are then dropped using the DataFrame.loc label indexer.
# Using df.drop() to drop the Unnamed columns
You can also use the DataFrame.drop
and
DataFrame.filter
method to drop the Unnamed columns from your DataFrame.
import pandas as pd df = pd.DataFrame( [[1, 2, 3], [4, 5, 6], [7, 8, 8]], columns=['bobby', 'hadz', 'com'] ) print(df) df.to_csv('data.csv', encoding='utf-8') df = pd.read_csv( 'data.csv', sep=',', encoding='utf-8', ) print('-' * 50) print(df) # 👇️ Index(['Unnamed: 0', 'bobby', 'hadz', 'com'], dtype='object') print(df.columns) print('-' * 50) df.drop(df.filter(regex="Unname"), axis=1, inplace=True) print(df) # 👇️ Index(['bobby', 'hadz', 'com'], dtype='object') print(df.columns)
Running the code sample produces the following output.
bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 -------------------------------------------------- Unnamed: 0 bobby hadz com 0 0 1 2 3 1 1 4 5 6 2 2 7 8 8 Index(['Unnamed: 0', 'bobby', 'hadz', 'com'], dtype='object') -------------------------------------------------- bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 Index(['bobby', 'hadz', 'com'], dtype='object')
We used the DataFrame.filter() method to get the DataFrame columns that start
with Unname.
The next step is to use the DataFrame.drop() method to drop the matching columns in place.
When the inplace argument is set to True, the original DataFrame is
updated, so no reassignment is necessary.
# Drop Unnamed:0 columns by renaming them
Alternatively, you can rename the Unnamed: 0 columns by using the DataFrame.rename method.
import pandas as pd df = pd.DataFrame( [[1, 2, 3], [4, 5, 6], [7, 8, 8]], columns=['bobby', 'hadz', 'com'] ) print(df) df.to_csv('data.csv', encoding='utf-8') df = pd.read_csv( 'data.csv', sep=',', encoding='utf-8', ) print('-' * 50) print(df) # 👇️ Index(['Unnamed: 0', 'bobby', 'hadz', 'com'], dtype='object') print(df.columns) print('-' * 50) df.rename(columns={'Unnamed: 0': 'Example_Name'}, inplace=True) print(df) # 👇️ Index(['Example_Name', 'bobby', 'hadz', 'com'], dtype='object') print(df.columns)
Running the code sample produces the following output.
bobby hadz com 0 1 2 3 1 4 5 6 2 7 8 8 -------------------------------------------------- Unnamed: 0 bobby hadz com 0 0 1 2 3 1 1 4 5 6 2 2 7 8 8 Index(['Unnamed: 0', 'bobby', 'hadz', 'com'], dtype='object') -------------------------------------------------- Example_Name bobby hadz com 0 0 1 2 3 1 1 4 5 6 2 2 7 8 8 Index(['Example_Name', 'bobby', 'hadz', 'com'], dtype='object')
The DataFrame.rename() method renames columns or index labels.
df.rename( columns={'Unnamed: 0': 'Example_Name'}, inplace=True )
When the inplace argument is set to True, the column is renamed in the
original DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- TypeError: Field elements must be 2- or 3-tuples, got 1
- ValueError: Expected 2D array, got 1D array instead [Fixed]
- ValueError: Found array with dim 3. Estimator expected 2
- ValueError: columns overlap but no suffix specified [Solved]
- Columns have mixed types. Specify dtype option on import
- Convert a Row to a Column Header in a Pandas DataFrame
- IndexError: single positional indexer is out-of-bounds [Fix]
- Arrays used as indices must be of integer (or boolean) type
- Boolean index did not match indexed array along dimension 0
- AttributeError: Can only use .dt accessor with datetimelike values
- Replace whole String if it contains Substring in Pandas
- Pandas: Create new row for each element in List in DataFrame
- ValueError: Length of values does not match length of index
- Get the first Row of each Group in a Pandas DataFrame
- Convert Epoch to Datetime in a Pandas DataFrame
- Concatenate strings from multiple rows with Pandas GroupBy
- NumPy or Pandas: How to check a Value or an Array for NaT
- How to repeat Rows N times in a Pandas DataFrame
- How to convert a Pandas DataFrame to a Markdown Table
- Pandas: Convert GroupBy results to Dictionary of Lists
- Pandas: How to Query a Column name with Spaces
- Pandas: Create Scatter plot from multiple DataFrame columns
- Python: Compare two CSV files and print the differences

