ValueError: columns overlap but no suffix specified [Solved]
Last updated: Apr 11, 2024
Reading time·5 min

# Table of Contents
- ValueError: columns overlap but no suffix specified
- Supply a suffix by setting the
lsuffixandrsuffixarguments - Using the
DataFrame.merge()method to solve the error - Using the
DataFrame.set_index()method to solve the error - Deleting the overlapping columns
- Solving the error by renaming the overlapping columns
# ValueError: columns overlap but no suffix specified [Solved]
The Pandas "ValueError: columns overlap but no suffix specified: Index(['name'], dtype='object')" occurs when the DataFrames you're trying to merge have overlapping columns but you haven't specified a suffix.
To solve the error, pass the lsuffix and rsuffix arguments when calling
DataFrame.join() or use the merge() method.
Here is an example of how the error occurs.
import pandas as pd df1 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df2 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], }) df3 = df1.join(df2, how='left') # ⛔️ ValueError: columns overlap but no suffix specified: Index(['name'], dtype='object') print(df3)
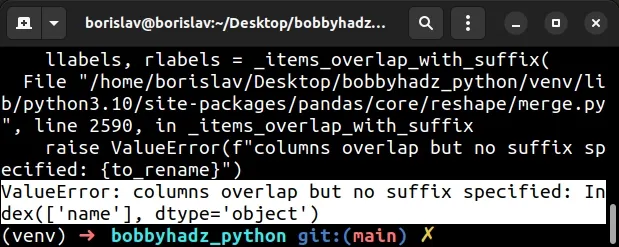
The two DataFrames have an overlapping column (name), however, we didn't
specify a suffix that is used to distinguish between the columns in the new
DataFrame.
# Supply a suffix by setting the lsuffix and rsuffix arguments
One way to solve the error is to supply a suffix in the call to
DataFrame.join()
by setting the lsuffix and rsuffix arguments.
import pandas as pd df1 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df2 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], }) df3 = df1.join(df2, how='left', lsuffix='_left', rsuffix='_right') # name_left experience salary name_right age # 0 Alice 1 175.1 Alice 29 # 1 Bobby 3 180.2 Bobby 30 # 2 Carl 5 190.3 Carl 31 # 3 Dan 7 205.4 Dan 32 print(df3)
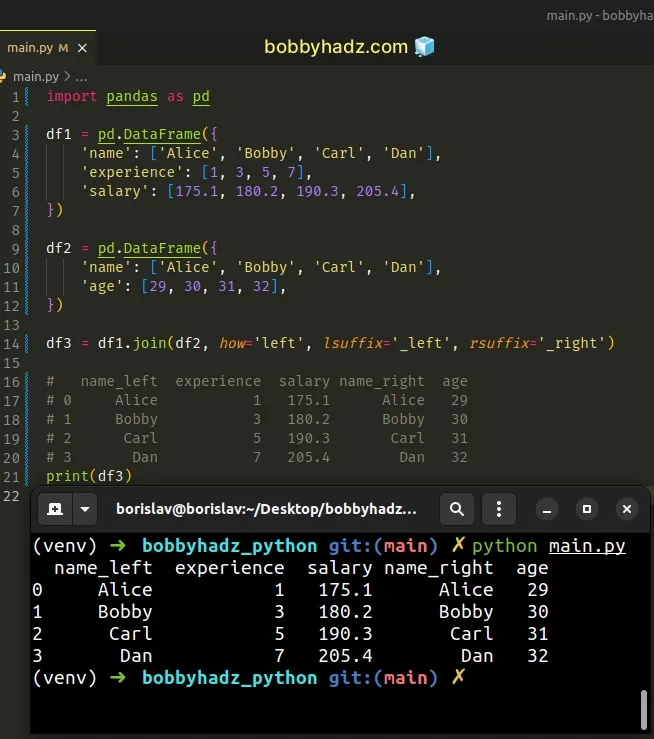
The suffix is used to differentiate between the overlapping columns (name in
the example) in the new DataFrame.
The lsuffix argument is the suffix to use from the left frame's overlapping
columns.
The rsuffix argument is the suffix to use from the right frame's overlapping
columns.
If you get the
You are trying to merge on int64 and object columns
error when calling the join() method, click on the link and follow the
instructions.
# Using the DataFrame.merge() method to solve the error
Alternatively, you can use the DataFrame.merge() method to solve the error.
import pandas as pd df1 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df2 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], }) df3 = df1.merge(df2, how='left') # name experience salary age # 0 Alice 1 175.1 29 # 1 Bobby 3 180.2 30 # 2 Carl 5 190.3 31 # 3 Dan 7 205.4 32 print(df3)
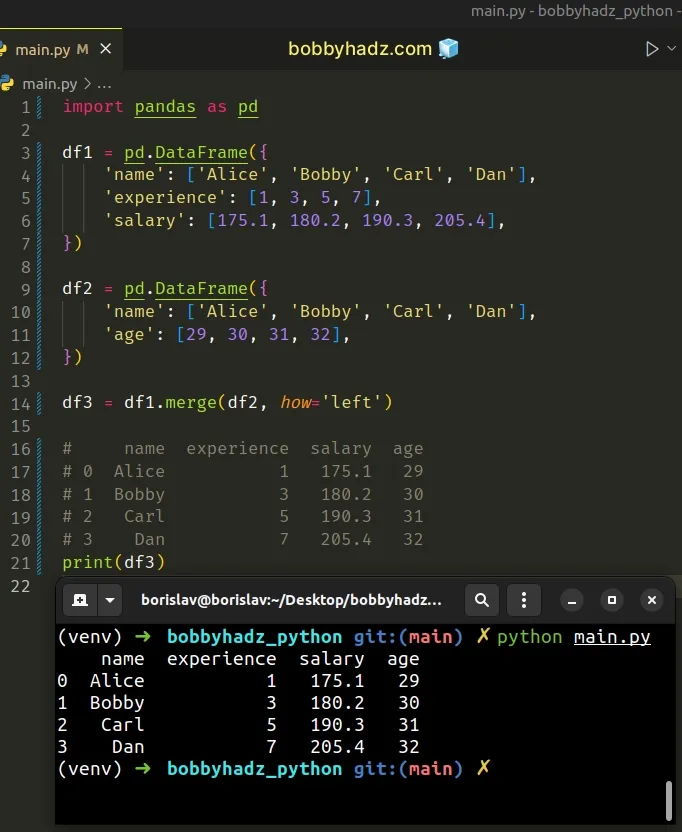
The
DataFrame.merge()
method merges DataFrame or named Series objects with a database-style join.
The method returns a DataFrame of the two merged objects.
When using the DataFrame.merge() method, you don't have to explicitly supply
the suffixes.
# Using the DataFrame.set_index() method to solve the error
You can also use the DataFrame.set_index() method to solve the error.
import pandas as pd df1 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df2 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], }) df1 = df1.set_index(['name']) df2 = df2.set_index(['name']) df3 = df1.join(df2, how='left') # experience salary age # name # Alice 1 175.1 29 # Bobby 3 180.2 30 # Carl 5 190.3 31 # Dan 7 205.4 32 print(df3)
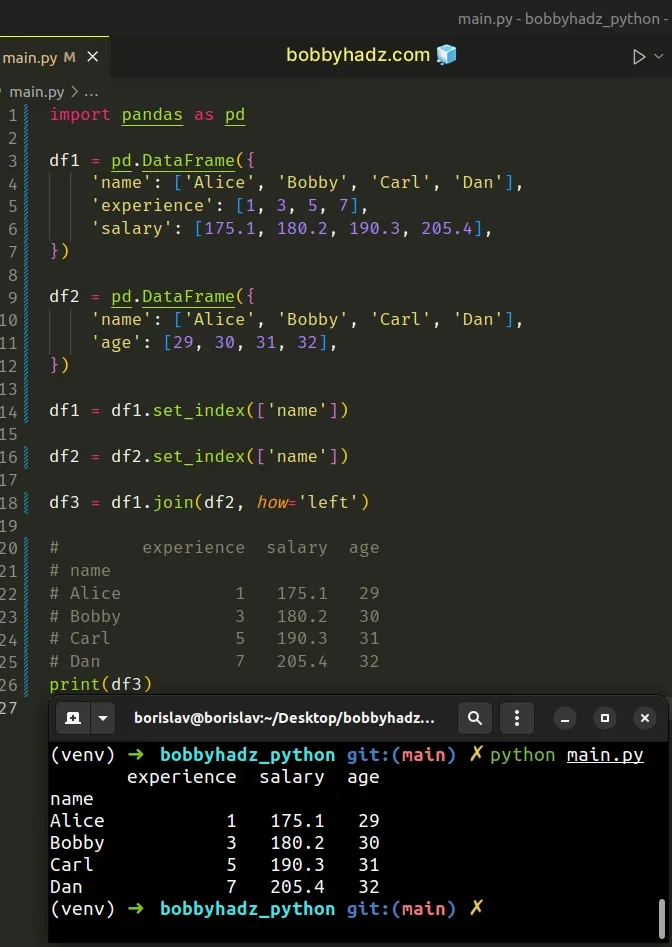
The DataFrame.set_index()
method sets the DataFrame index (row labels) using existing columns.
Using the set_index() method resolves the issue because the
DataFrame.join() method uses the index of the supplied DataFrame.
# Deleting the overlapping columns
In the unlikely scenario that you want to delete the overlapping columns, use
the del statement.
import pandas as pd df1 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df2 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], }) del df1['name'] del df2['name'] df3 = df1.join(df2, how='left') # experience salary age # 0 1 175.1 29 # 1 3 180.2 30 # 2 5 190.3 31 # 3 7 205.4 32 print(df3)
We used the del statement to delete the name column from the two DataFrames
before calling join().
# Solving the error by renaming the overlapping columns
Alternatively, you can rename the overlapping columns before you call join().
import pandas as pd df1 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df2 = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], }) df1 = df1.rename(columns={'name': 'new_name'}) df3 = df1.join(df2, how='left') # new_name experience salary name age # 0 Alice 1 175.1 Alice 29 # 1 Bobby 3 180.2 Bobby 30 # 2 Carl 5 190.3 Carl 31 # 3 Dan 7 205.4 Dan 32 print(df3)
We used the
DataFrame.rename()
method to rename the name column of the first DataFrame.
There are no longer any overlapping columns, so everything works as expected.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- AttributeError module 'numpy' has no attribute array or int
- NumPy RuntimeWarning: divide by zero encountered in log10
- ValueError: x and y must have same first dimension, but have shapes
- SystemError: initialization of _internal failed without raising an exception
- TypeError Invalid comparison between datetime64[ns] and date
- How to replace None with NaN in Pandas DataFrame
- You are trying to merge on int64 and object columns [Fixed]
- Could not broadcast input array from shape into shape [Fix]
- ValueError: object too deep for desired array [Solved]
- Only one element tensors can be converted to Python scalars
- Shape mismatch: objects cannot be broadcast to a single shape
- Add a column with incremental Numbers to a Pandas DataFrame
- Cannot concatenate object of type 'X'; only Series and DataFrame objs are valid
- Concatenate strings from multiple rows with Pandas GroupBy
- Pandas: Sum the values in a Column that match a Condition
- How to Multiply two or more Columns in Pandas
- Add columns of a different Length to a DataFrame in Pandas

