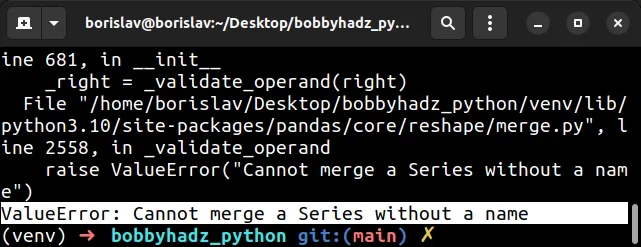
ValueError: Cannot merge a Series without a name [Solved]
Last updated: Apr 11, 2024
Reading time·5 min

# Table of Contents
- ValueError: Cannot merge a Series without a name
- Solve the error by explicitly naming the Series
- Solve the error by converting the Series to a DataFrame with to_frame()
- Solving the error by using DataFrame.join()
- Solving the error by using DataFrame.apply()
# ValueError: Cannot merge a Series without a name [Solved]
The article addresses the following 2 related errors:
- ValueError: Cannot merge a Series without a name
- ValueError: Other Series must have a name
The Pandas "ValueError: Other Series must have a name" error occurs when you
try to merge a DataFrame and a Series without naming the Series.
To solve the error, use the rename() method to name the Series before
calling DataFrame.merge().
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) # ⛔️ ValueError: Cannot merge a Series without a name df = df.merge(series)
You can only join a DataFrame and a Series if the Series is named.
One way to resolve the issue is to use the
Series.rename()
method to alter the name of the Series before merging.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.merge( series.rename('C'), left_index=True, right_index=True ) print(df2)
Running the code sample produces the following output.
A B C 0 1 3 5 1 2 4 6
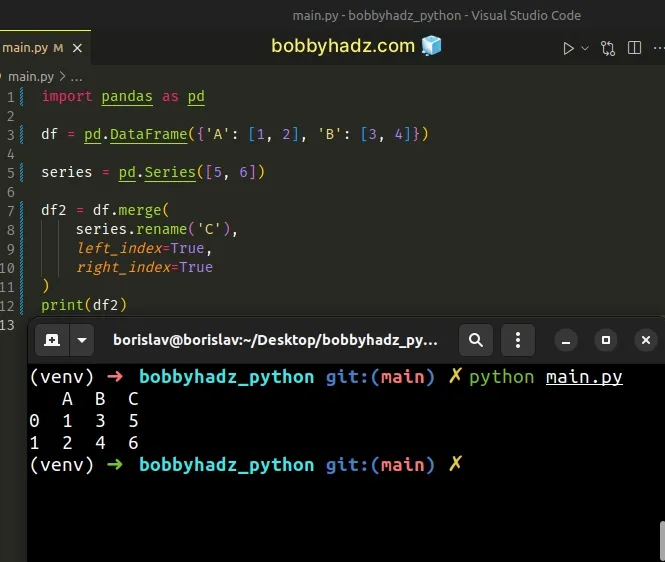
We renamed the Series to C and set the left_index and right_index
arguments to True to merge the DataFrame and the Series on the index.
left_index argument is set to True, the index from the left DataFrame is used as the join key(s).When the right_index argument is set to True, the index from the right
DataFrame (or Series) is used as the join key.
Both arguments default to False.
# Solve the error by explicitly naming the Series
You can also solve the error by explicitly naming the Series upon creation.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6], name='C') df2 = df.merge( series, left_index=True, right_index=True ) # A B C # 0 1 3 5 # 1 2 4 6 print(df2)
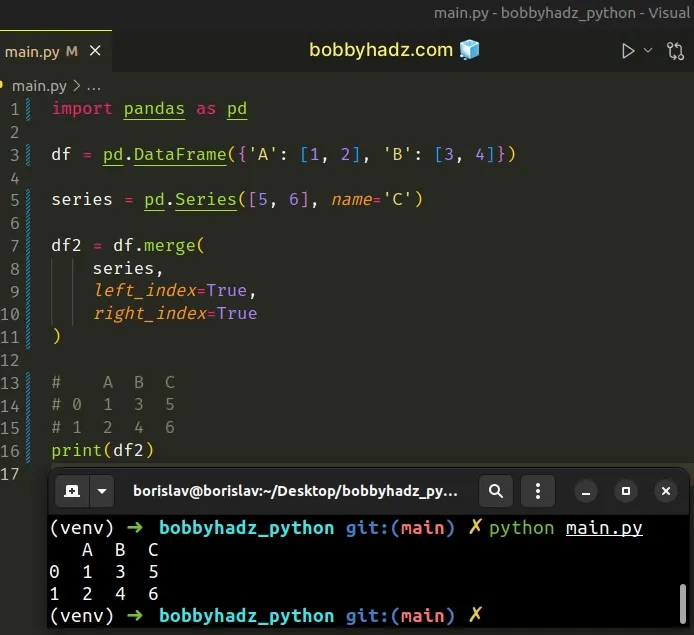
We passed the name argument when instantiating the
pandas.Series
class.
The name argument is used to specify the name that should be given to the
Series.
# Solve the error by converting the Series to a DataFrame with to_frame()
You can also solve the error by converting the Series to a DataFrame with
the
Series.to_frame
method.
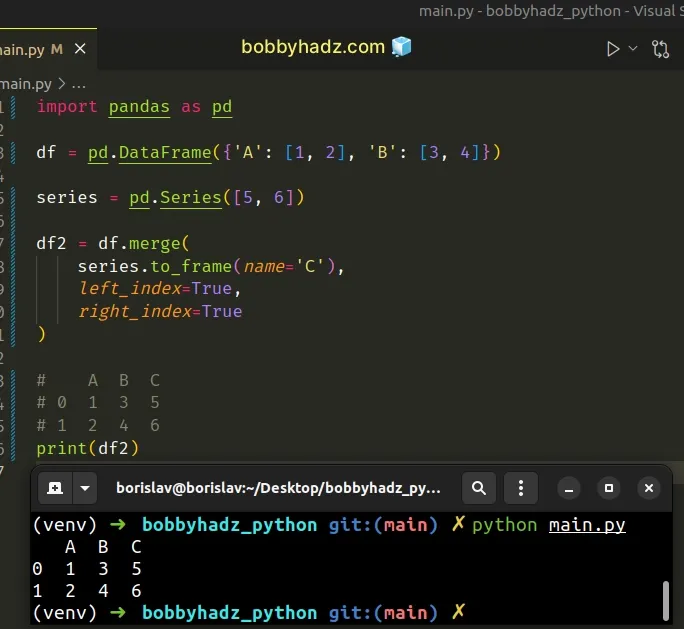
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.merge( series.to_frame(), left_index=True, right_index=True ) # A B 0 # 0 1 3 5 # 1 2 4 6 print(df2)
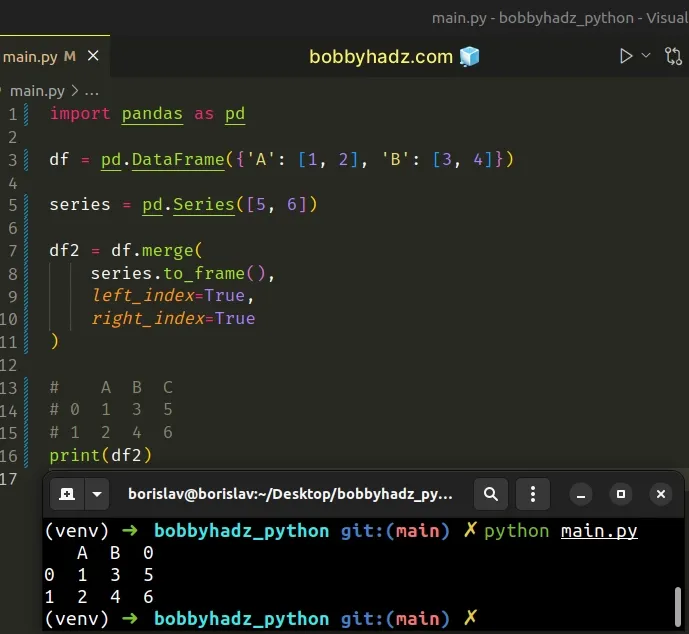
The Series.to_frame() method converts a Series to a DataFrame.
You can also substitute the name of the Series (if it has one) when calling
to_frame().
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.merge( series.to_frame(name='C'), left_index=True, right_index=True ) # A B C # 0 1 3 5 # 1 2 4 6 print(df2)
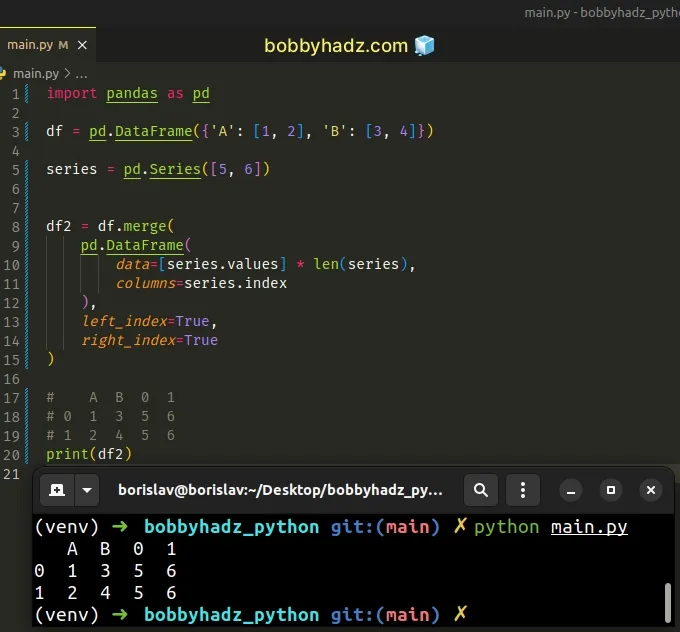
Alternatively, you can use the pandas.DataFrame() class and multiply the
Series values by the length.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.merge( pd.DataFrame( data=[series.values] * len(series), columns=series.index ), left_index=True, right_index=True ) # A B 0 1 # 0 1 3 5 6 # 1 2 4 5 6 print(df2)
If you want the index of the constructed DataFrame to use the index of the
existing DataFrame, set the parameter when calling pd.DataFrame().
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.merge( pd.DataFrame( data=[series.values] * len(series), columns=series.index, index=df.index ), left_index=True, right_index=True ) # A B 0 1 # 0 1 3 5 6 # 1 2 4 5 6 print(df2)
# Solving the error by using DataFrame.join()
You can also solve the error by:
- Creating a one row
DataFrameby usingpd.DataFrame()and accessing theTattribute. - Joining the two DataFrames.
- Using
DataFrame.fillna()to fill the NaN values.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.join(pd.DataFrame(series).T).fillna(method='ffill') # A B 0 1 # 0 1 3 5.0 6.0 # 1 2 4 5.0 6.0 print(df2)
Accessing the T attribute on the DataFrame object returns a one-row
DataFrame constructed from the Series object.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) # 0 1 # 0 5 6 print(pd.DataFrame(series).T)
The DataFrame.join method joins the columns of the two DataFrames.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) # A B 0 1 # 0 1 3 5.0 6.0 # 1 2 4 NaN NaN print(df.join(pd.DataFrame(series).T))
The last step is to use the
DataFrame.fillna
method to fill the NaN values.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.join(pd.DataFrame(series).T).fillna(method='ffill') # A B 0 1 # 0 1 3 5.0 6.0 # 1 2 4 5.0 6.0 print(df2)
When the method parameter is set to "ffill" (forward fill), then the last
valid observation is propagated forward to the next valid.
You can also use the
pandas.concat
method instead of using fillna().
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.join( pd.concat( [pd.DataFrame(series).T] * len(df), ignore_index=True ) ) # A B 0 1 # 0 1 3 5 6 # 1 2 4 5 6 print(df2)
The pandas.concat() method concatenates pandas objects along a particular
axis.
# Solving the error by using DataFrame.apply()
You can also solve the error by using DataFrame.apply.
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) df2 = df.join(df.apply(lambda x: series, axis=1)) # A B 0 1 # 0 1 3 5 6 # 1 2 4 5 6 print(df2)
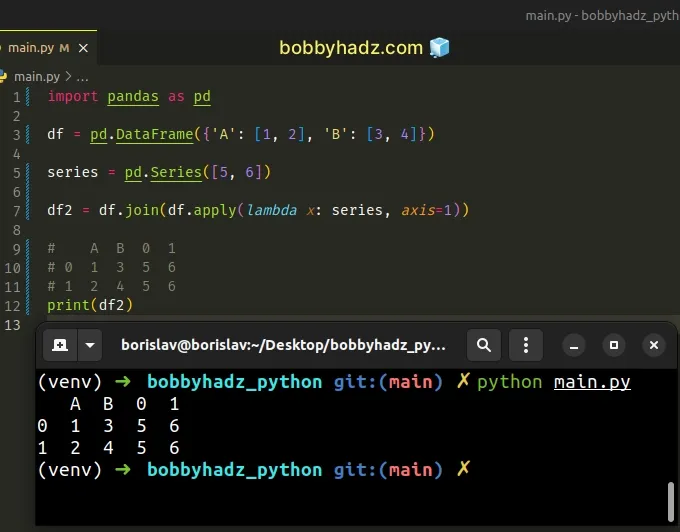
The DataFrame.apply() method applies a function along an axis of the
DataFrame (axis=1 in the example).
The lambda function returns the Series which is then passed to
DataFrame.join().
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) series = pd.Series([5, 6]) # 0 1 # 0 5 6 # 1 5 6 print(df.apply(lambda x: series, axis=1))
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Copy a column from one DataFrame to another in Pandas
- AttributeError: Can only use .str accessor with string values
- ValueError: zero-dimensional arrays cannot be concatenated
- ValueError: zero-dimensional arrays cannot be concatenated
- Object arrays cannot be loaded when allow_pickle=False
- ValueError: Columns must be same length as key [Solved]
- TypeError: Field elements must be 2- or 3-tuples, got 1
- ValueError: Expected 2D array, got 1D array instead [Fixed]
- Count number of non-NaN values in each column of DataFrame
- Pandas: Create new row for each element in List in DataFrame
- Index(...) must be called with a collection of some kind
- ValueError: Shape of passed values is X, indices imply Y

