IndexError: single positional indexer is out-of-bounds [Fix]
Last updated: Apr 11, 2024
Reading time·4 min

# IndexError: single positional indexer is out-of-bounds [Fix]
The Pandas "IndexError: single positional indexer is out-of-bounds " occurs when you try to index a column or a row but specify an index that is out of bounds.
To solve the error, make sure to specify an index that is not larger than the
dimensions of your DataFrame.
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) # ⛔️ IndexError: single positional indexer is out-of-bounds print(df.iloc[:, 4])
The code sample tries to access the fifth column of the DataFrame, however, an
error is raised because the DataFrame only has 4 columns.
name experience salary 0 Alice 11 175.1 1 Bobby 14 180.2 2 Carl 16 190.3 3 Dan 18 210.4
Notice that the DataFrame has 3 columns and 4 rows.
Python indexes are zero-based, so the index of the first column is 0 and the
index of the last column is -1.
You might also get the error when trying to access a row at an index that is out of bounds.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) # ⛔️ IndexError: single positional indexer is out-of-bounds print(df.iloc[[4]])
We tried to access the fifth row (index 4) and got the error because the
DataFrame only has 4 rows.
You can get the number of rows and columns your DataFrame has by using
df.index and df.shape[1].
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) row_count = len(df.index) print(row_count) # 👉️ 4 column_count = df.shape[1] print(column_count) # 👉️ 3
Running the code sample produces the following output.
name experience salary 0 Alice 11 175.1 1 Bobby 14 180.2 2 Carl 16 190.3 3 Dan 18 210.4 -------------------------------------------------- 4 3
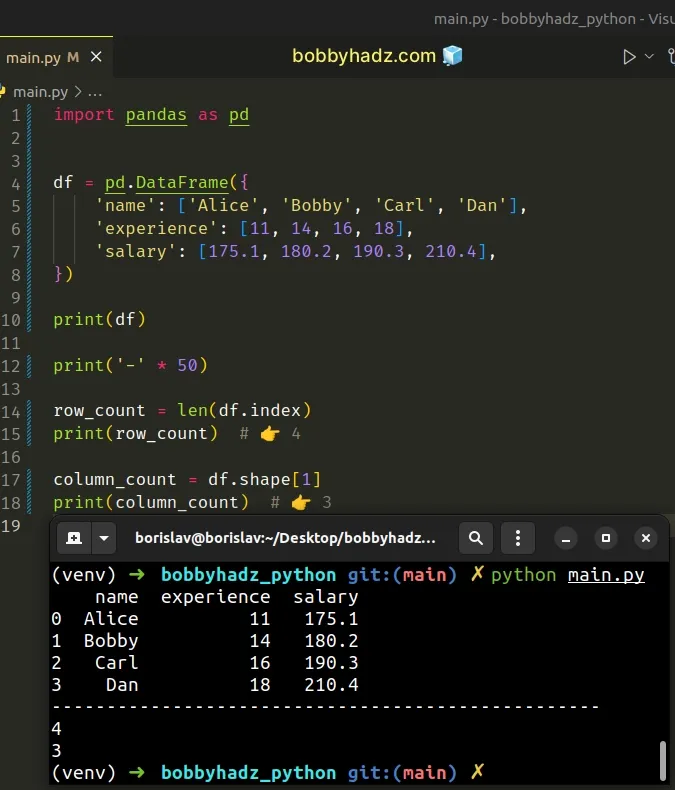
As shown in the screenshot, the DataFrame has 4 rows and 3 columns.
In other words, the last row index is 3 and the last column index is 2
(because indexes are zero-based).
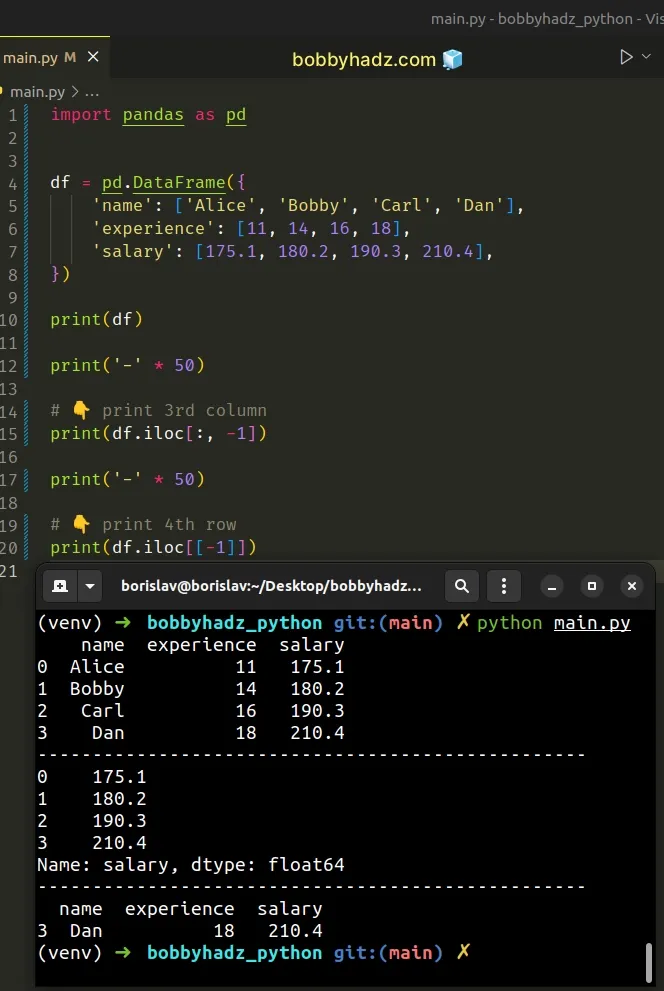
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) # 👇️ Print 3rd column print(df.iloc[:, 2]) print('-' * 50) # 👇️ Print 4th row print(df.iloc[[3]])
Running the code sample produces the following output.
name experience salary 0 Alice 11 175.1 1 Bobby 14 180.2 2 Carl 16 190.3 3 Dan 18 210.4 -------------------------------------------------- 0 175.1 1 180.2 2 190.3 3 210.4 Name: salary, dtype: float64 -------------------------------------------------- name experience salary 3 Dan 18 210.4
The following line prints the 3rd column (index 2).
# 0 175.1 # 1 180.2 # 2 190.3 # 3 210.4 # Name: salary, dtype: float64 print(df.iloc[:, 2])
And the following line prints the 4th row (index 3).
# name experience salary # 3 Dan 18 210.4 print(df.iloc[[3]])
# Accessing the last row or column in the DataFrame with an index of -1
If you need to access the last row or column in the DataFrame, use an index of
-1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) # 👇️ print last column print(df.iloc[:, -1]) print('-' * 50) # 👇️ print last row print(df.iloc[[-1]])
The code sample above produces the following output.
# name experience salary # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 # -------------------------------------------------- # 0 175.1 # 1 180.2 # 2 190.3 # 3 210.4 # Name: salary, dtype: float64 # -------------------------------------------------- # name experience salary # 3 Dan 18 210.4
You can achieve the same result by specifying an index of row_count - 1 and
column_count - 1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) column_count = df.shape[1] print(column_count) # 👉️ 3 # 👇️ print 3rd column print(df.iloc[:, column_count - 1]) print('-' * 50) row_count = len(df.index) print(row_count) # 👉️ 4 # 👇️ print 4th row print(df.iloc[[row_count - 1]])
Running the code sample produces the following output.
name experience salary 0 Alice 11 175.1 1 Bobby 14 180.2 2 Carl 16 190.3 3 Dan 18 210.4 -------------------------------------------------- 3 0 175.1 1 180.2 2 190.3 3 210.4 Name: salary, dtype: float64 -------------------------------------------------- 4 name experience salary 3 Dan 18 210.4
# Using a try/except statement to handle the error
Alternatively, you can use a try/except statement to handle the error.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [11, 14, 16, 18], 'salary': [175.1, 180.2, 190.3, 210.4], }) print(df) print('-' * 50) try: print(df.iloc[:, 3]) except IndexError: print('Specified column index out of bounds')
Running the code sample produces the following output.
name experience salary 0 Alice 11 175.1 1 Bobby 14 180.2 2 Carl 16 190.3 3 Dan 18 210.4 -------------------------------------------------- Specified column index out of bounds
We try to get the fourth column (index 4) from the DataFrame, however, it only
contains 3 columns, so an IndexError is raised and is then handled by the
except block.
# Make sure your CSV file is not empty
If you got the error when reading a CSV file and converting it to a DataFrame,
make sure the .csv file is not empty.
DataFrame object. If you try to access an empty DataFrame at any index, the IndexError` exception is raised.If you get the error IndexError: index 0 is out of bounds for axis 0 with size 0, click on the link and follow the instructions.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- IndexError: invalid index to scalar variable in Python
- IndexError: list assignment index out of range in Python
- Only integers, slices (
:), ellipsis (...), numpy.newaxis (None) and integer or boolean arrays are valid indices - IndexError: pop from empty list in Python [Solved]
- Replacement index 1 out of range for positional args tuple
- Select all Columns starting with a given String in Pandas
- Converting a Nested Dictionary to a Pandas DataFrame
- Replace negative Numbers in a Pandas DataFrame with Zero
- Pandas ValueError: ('Lengths must match to compare')

