Pandas: Create new row for each element in List in DataFrame
Last updated: Apr 11, 2024
Reading time·4 min

# Table of Contents
- Pandas: Create new row for each element in List in DataFrame
- Creating new rows by exploding only the specific column
- Expanding comma-separated strings in a column in Pandas
# Pandas: Create new row for each element in List in DataFrame
Use the DataFrame.explode() method to create a new row for each element in a
List in a DataFrame.
The method transforms each element of the specified list to a row and replicates the index values.
import pandas as pd df = pd.DataFrame({ 'first': [['a', 'b'], ['c', 'd'], ['e', 'f'], 'g'], 'second': [1, 2, 3, 4] }) print(df) df = df.explode('first') print('-' * 50) print(df)
Running the code sample produces the following output.
first second 0 [a, b] 1 1 [c, d] 2 2 [e, f] 3 3 g 4 -------------------------------------------------- first second 0 a 1 0 b 1 1 c 2 1 d 2 2 e 3 2 f 3 3 g 4
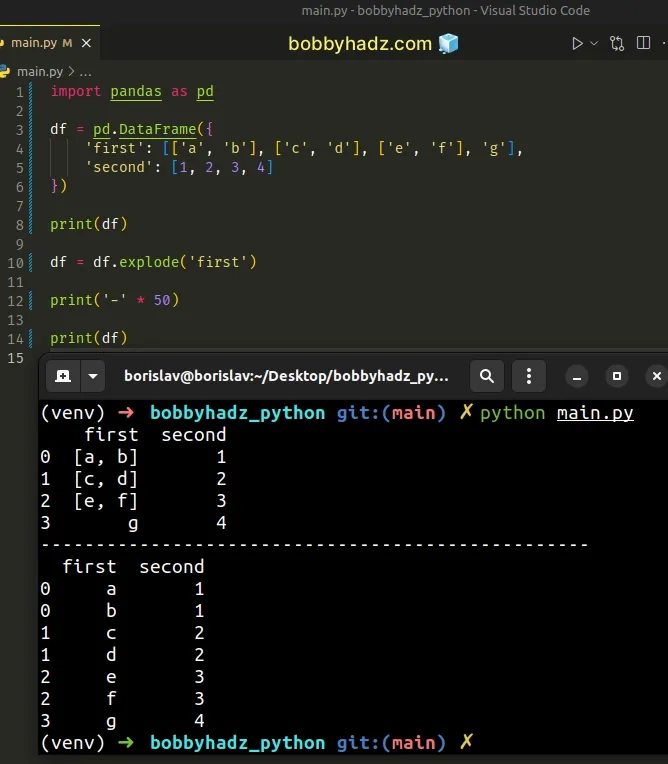
The DataFrame.explode method transforms each element of a list-like object to a row and replicates the index values.
The only argument we passed to the index is the column to explode.
If you need to explode multiple columns, set the argument to a list of strings.
Notice that the index values are replicated in the output.
first second 0 a 1 0 b 1 1 c 2 1 d 2 2 e 3 2 f 3 3 g 4
You can change the default behavior by setting the ignore_index argument to
True.
import pandas as pd df = pd.DataFrame({ 'first': [['a', 'b'], ['c', 'd'], ['e', 'f'], 'g'], 'second': [1, 2, 3, 4] }) print(df) df = df.explode('first', ignore_index=True) print('-' * 50) print(df)
Here is the output of running the script with python main.py.
first second 0 [a, b] 1 1 [c, d] 2 2 [e, f] 3 3 g 4 -------------------------------------------------- first second 0 a 1 1 b 1 2 c 2 3 d 2 4 e 3 5 f 3 6 g 4
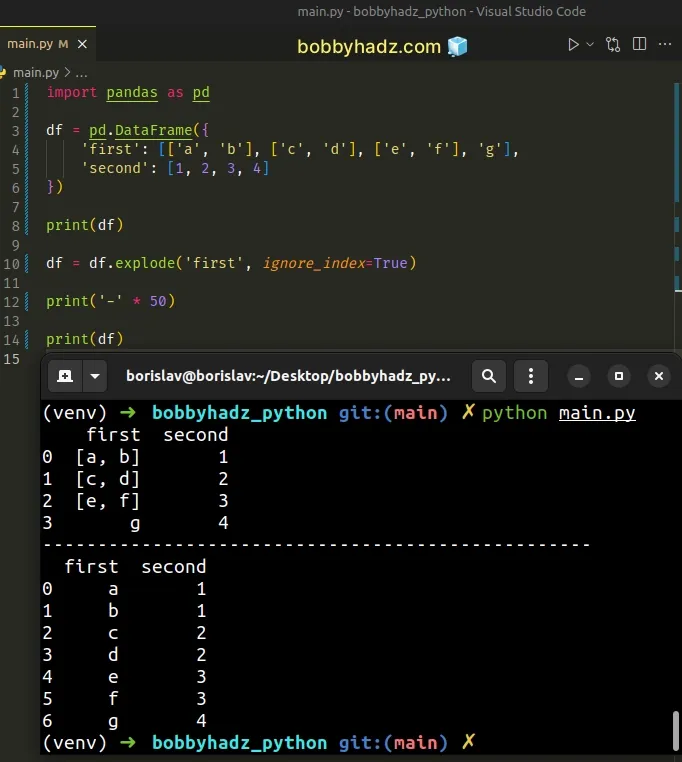
Alternatively, you can use the reset_index() method.
import pandas as pd df = pd.DataFrame({ 'first': [['a', 'b'], ['c', 'd'], ['e', 'f'], 'g'], 'second': [1, 2, 3, 4] }) print(df) df = df.explode('first').reset_index(drop=True) print('-' * 50) print(df)
Running the code sample produces the following output.
first second 0 [a, b] 1 1 [c, d] 2 2 [e, f] 3 3 g 4 -------------------------------------------------- first second 0 a 1 1 b 1 2 c 2 3 d 2 4 e 3 5 f 3 6 g 4
The DataFrame.reset_index()
method resets the index of the DataFrame, causing it to use the default index.
# Creating new rows by exploding only the specific column
You can also create new rows by exploding only the specific column in the
DataFrame.
import pandas as pd df = pd.DataFrame({ 'first': [['a', 'b'], ['c', 'd'], ['e', 'f'], 'g'], 'second': [1, 2, 3, 4] }) print(df) print('-' * 50) print(df['first'].explode())
Running the code sample produces the following output.
first second 0 [a, b] 1 1 [c, d] 2 2 [e, f] 3 3 g 4 -------------------------------------------------- 0 a 0 b 1 c 1 d 2 e 2 f 3 g Name: first, dtype: object
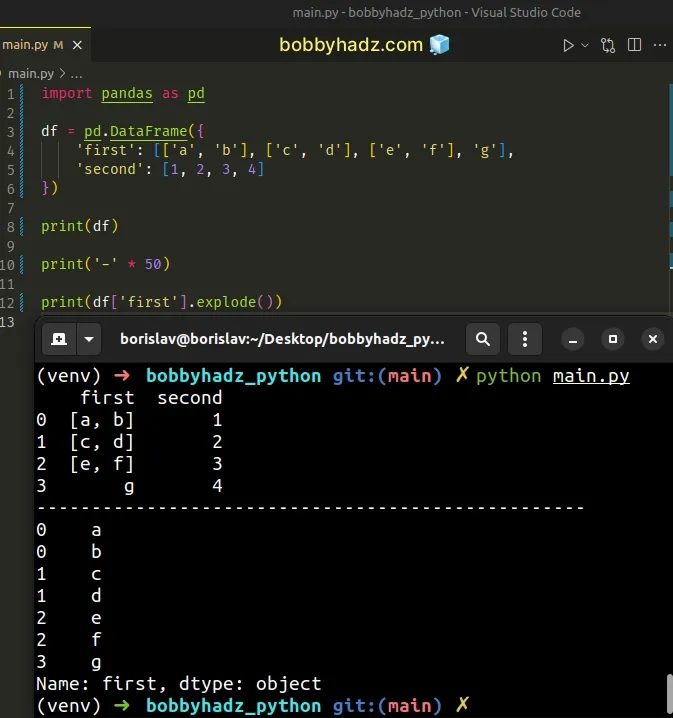
3 things to note when using the DataFrame.explode() method:
- It replaces empty lists with
numpy.nan. - It preserves scalar entries.
- The dtype of
the resulting
DataFrameorSeriesis alwaysobject.
import pandas as pd df = pd.DataFrame({ 'first': [['a', 'b'], ['c', 'd'], [], 'e'], 'second': [1, 2, 3, 4] }) print(df) df = df.explode('first') print('-' * 50) print(df) print('-' * 50) print(df.dtypes)
Running the code sample produces the following output.
first second 0 [a, b] 1 1 [c, d] 2 2 [] 3 3 e 4 -------------------------------------------------- first second 0 a 1 0 b 1 1 c 2 1 d 2 2 NaN 3 3 e 4 -------------------------------------------------- first object second int64 dtype: object
# Expanding comma-separated strings in a column in Pandas
The DataFrame.explode() method is commonly used to expand comma-separated
strings in a column.
Here is an example.
import pandas as pd df = pd.DataFrame([ { 'one': 'a,b', 'two': 1 }, { 'one': 'c,d', 'two': 2 } ]) print(df) df = df.assign(one=df.one.str.split(',')).explode('one') print('-' * 50) print(df)
Running the code sample produces the following output.
one two 0 a,b 1 1 c,d 2 -------------------------------------------------- one two 0 a 1 0 b 1 1 c 2 1 d 2
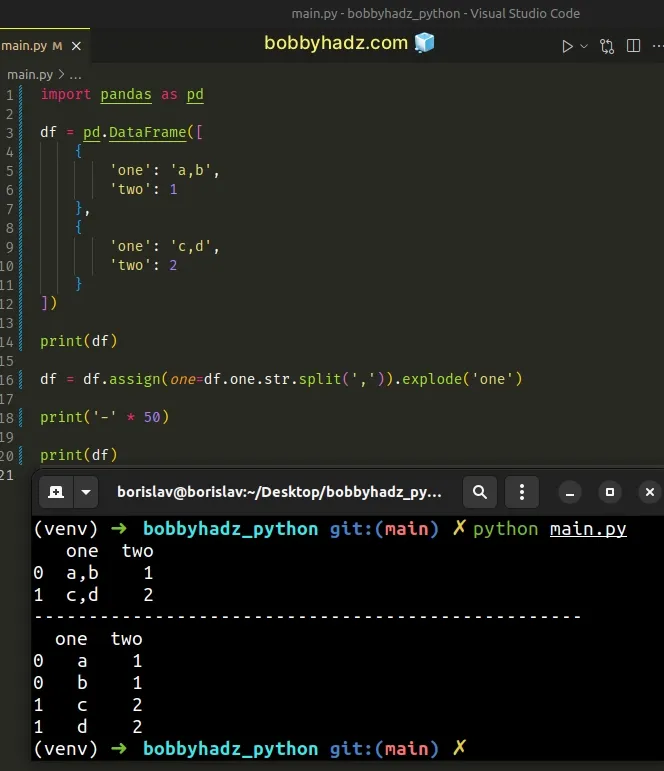
We used the str.split() method to split the values in the one column into a
list on each comma.
The
DataFrame.assign
method assigns new columns to a DataFrame.
The last step is to call the explode() method on the result.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: cannot reindex on an axis with duplicate labels
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- ValueError: cannot reshape array of size X into shape Y
- Object arrays cannot be loaded when allow_pickle=False
- ValueError: Columns must be same length as key [Solved]
- ValueError: DataFrame constructor not properly called [Fix]
- Usecols do not match columns, columns expected but not found
- Using pandas.read_csv() with multiple delimiters in Python
- ValueError: Cannot merge a Series without a name [Solved]
- Index(...) must be called with a collection of some kind
- ValueError: Shape of passed values is X, indices imply Y
- ValueError: Length of values does not match length of index
- Get the first Row of each Group in a Pandas DataFrame
- How to drop all Rows in a Pandas DataFrame in Python

