Replace whole String if it contains Substring in Pandas
Last updated: Apr 11, 2024
Reading time·6 min

# Table of Contents
- Replace whole String if it contains Substring in Pandas
- Replace whole String if it contains Substring in Pandas ignoring the case
- Replace whole string if it contains substring in Pandas using Regex
- Replace whole string if it contains substring in Pandas using
apply()
# Replace whole String if it contains Substring in Pandas
To replace whole strings if they contain a substring in Pandas:
- Use the
str.contains()method to check if each string contains a substring. - Assign a new value to the matching strings.
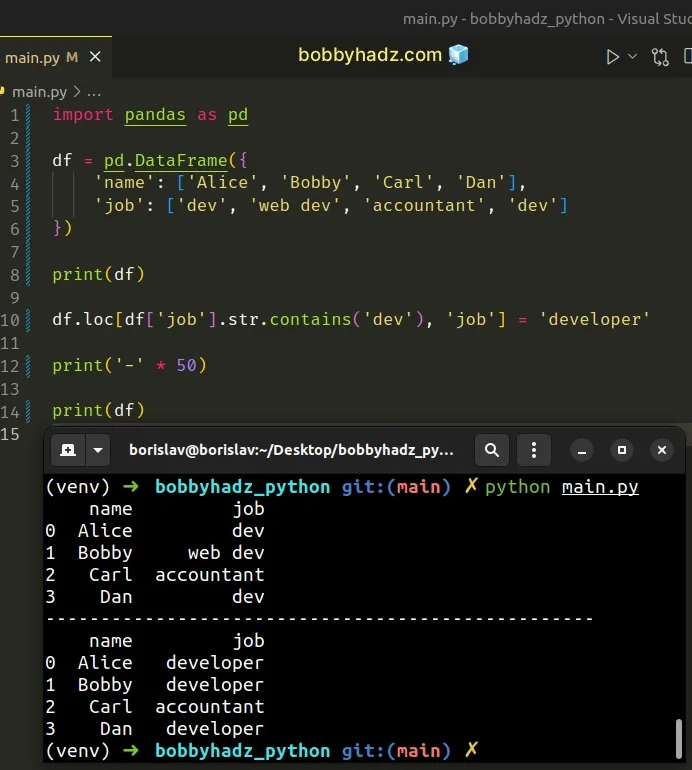
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['dev', 'web dev', 'accountant', 'dev'] }) print(df) df.loc[df['job'].str.contains('dev'), 'job'] = 'developer' print('-' * 50) print(df)
Running the code sample produces the following output.
name job 0 Alice dev 1 Bobby web dev 2 Carl accountant 3 Dan dev -------------------------------------------------- name job 0 Alice developer 1 Bobby developer 2 Carl accountant 3 Dan developer
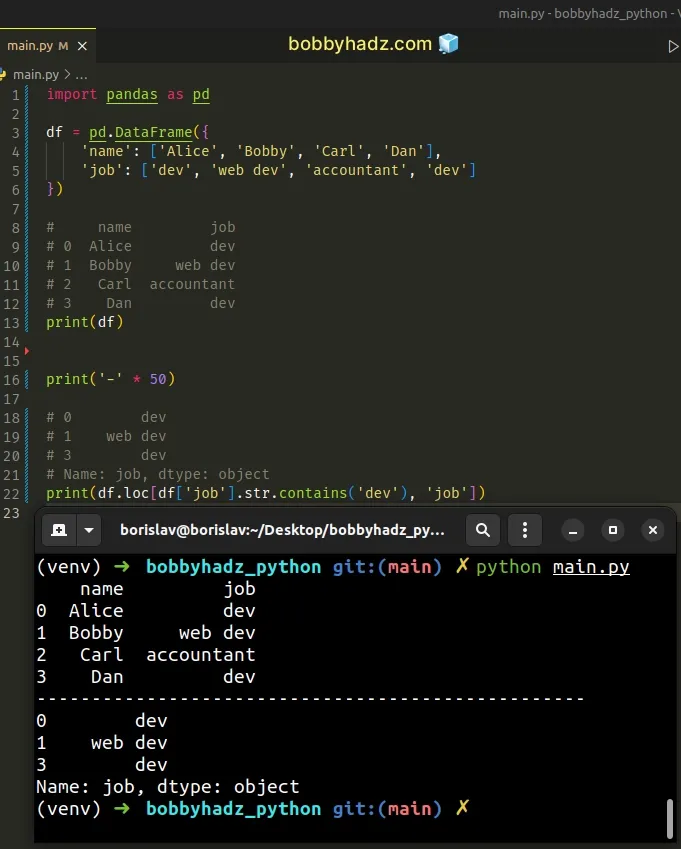
The DataFrame.loc indexer enables us to access a group of rows and columns by label(s) or a boolean array.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['dev', 'web dev', 'accountant', 'dev'] }) # name job # 0 Alice dev # 1 Bobby web dev # 2 Carl accountant # 3 Dan dev print(df) print('-' * 50) # 0 dev # 1 web dev # 3 dev # Name: job, dtype: object print(df.loc[df['job'].str.contains('dev'), 'job'])
Once we have the group of rows that contain the string "dev" in the job
column, we update their values to "developer".
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['dev', 'web dev', 'accountant', 'dev'] }) # 0 Alice dev # 1 Bobby web dev # 2 Carl accountant # 3 Dan dev print(df) df.loc[df['job'].str.contains('dev'), 'job'] = 'developer' print('-' * 50) # name job # 0 Alice developer # 1 Bobby developer # 2 Carl accountant # 3 Dan developer print(df)
You can see that the rows with values dev and web dev were updated to
developer.
The str.contains() method takes a pattern as a parameter and checks if the supplied pattern or regex is contained within a string.
The method returns a boolean Series or Index indicating the result.
# Replace whole String if it contains Substring in Pandas ignoring the case
If you need to replace a whole string if it contains a substring in pandas,
ignoring the case, set the case argument to False when calling
str.contains().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['DEV', 'web Dev', 'accountant', 'dev'] }) print(df) df.loc[df['job'].str.contains('dev', case=False), 'job'] = 'developer' print('-' * 50) # name job # 0 Alice developer # 1 Bobby developer # 2 Carl accountant # 3 Dan developer print(df)
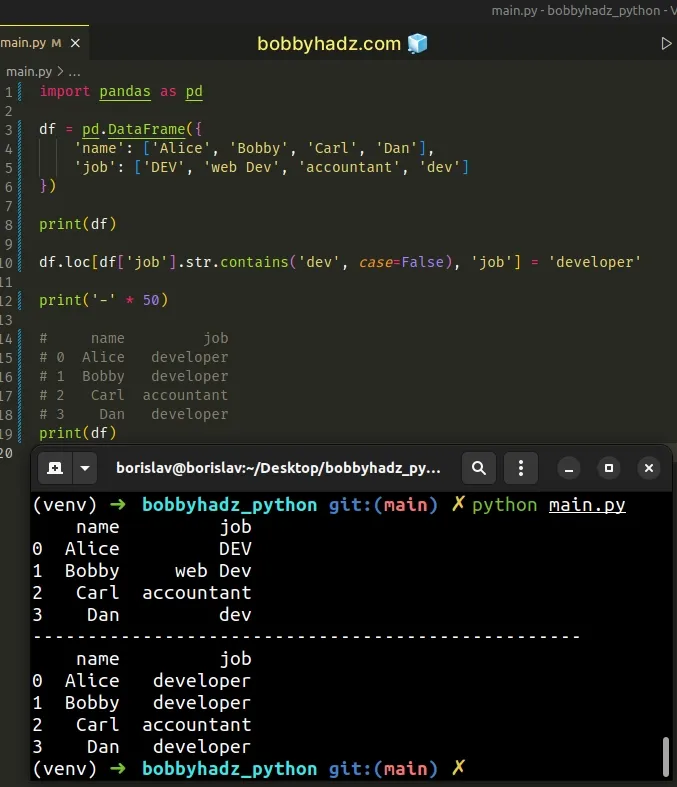
Notice that the values in the job column are not consistently cased.
The str.contains method takes a case argument that can be used to make the
method case-insensitive.
case argument is set to True, which means that str.contains() is case-sensitive.Setting the argument to False means that the case is ignored when matching the
substring in each string.
# Replace whole string if it contains substring in Pandas using Regex
You can also use a regular expression to replace a whole string if it contains a
substring in pandas.
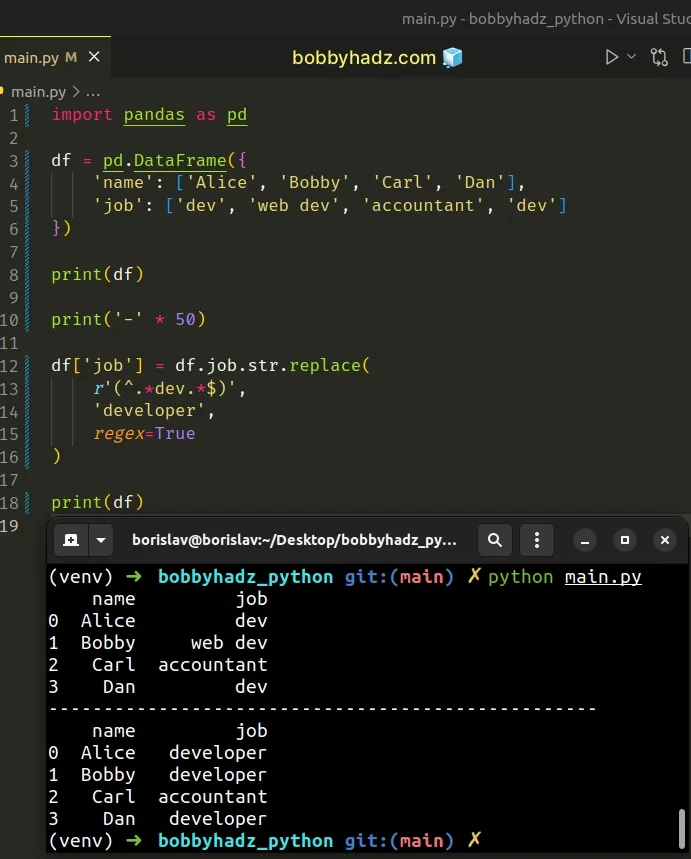
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['dev', 'web dev', 'accountant', 'dev'] }) print(df) print('-' * 50) df['job'] = df.job.str.replace( r'(^.*dev.*$)', 'developer', regex=True ) print(df)
Running the code sample produces the following output.
name job 0 Alice dev 1 Bobby web dev 2 Carl accountant 3 Dan dev -------------------------------------------------- name job 0 Alice developer 1 Bobby developer 2 Carl accountant 3 Dan developer
We passed a regular expression as the first parameter to the str.replace() method.
df['job'] = df.job.str.replace( r'(^.*dev.*$)', 'developer', regex=True )
The regular expression matches a string that contains the substring dev.
The replacement string is provided as the second argument.
Notice that we also had to set the regex keyword argument to True.
regex argument determines if the supplied pattern is a regular expression.By default, the argument is set to False, so it has to be explicitly
specified when using a regex with str.replace().
If you want to ignore the case when matching the substring in the strings, set
the flags keyword argument to re.IGNORECASE
import re import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['DEV', 'web Dev', 'accountant', 'dev'] }) print(df) print('-' * 50) df['job'] = df.job.str.replace( r'(^.*dev.*$)', 'developer', regex=True, flags=re.IGNORECASE ) print(df)
Running the code sample produces the following output.
name job 0 Alice DEV 1 Bobby web Dev 2 Carl accountant 3 Dan dev -------------------------------------------------- name job 0 Alice developer 1 Bobby developer 2 Carl accountant 3 Dan developer
When the flags argument is set to re.IGNORECASE, the substring is matched in
the string in a case-insensitive manner.
# Replace whole string if it contains substring in Pandas using apply()
You can also use the DataFrame.apply() method to replace a whole string if it contains a substring in Pandas.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['dev', 'web dev', 'accountant', 'dev'] }) print(df) print('-' * 50) df['job'] = df.job.apply( lambda x: 'developer' if 'dev' in x else x ) print(df)
Running the code sample produces the following output.
name job 0 Alice dev 1 Bobby web dev 2 Carl accountant 3 Dan dev -------------------------------------------------- name job 0 Alice developer 1 Bobby developer 2 Carl accountant 3 Dan developer
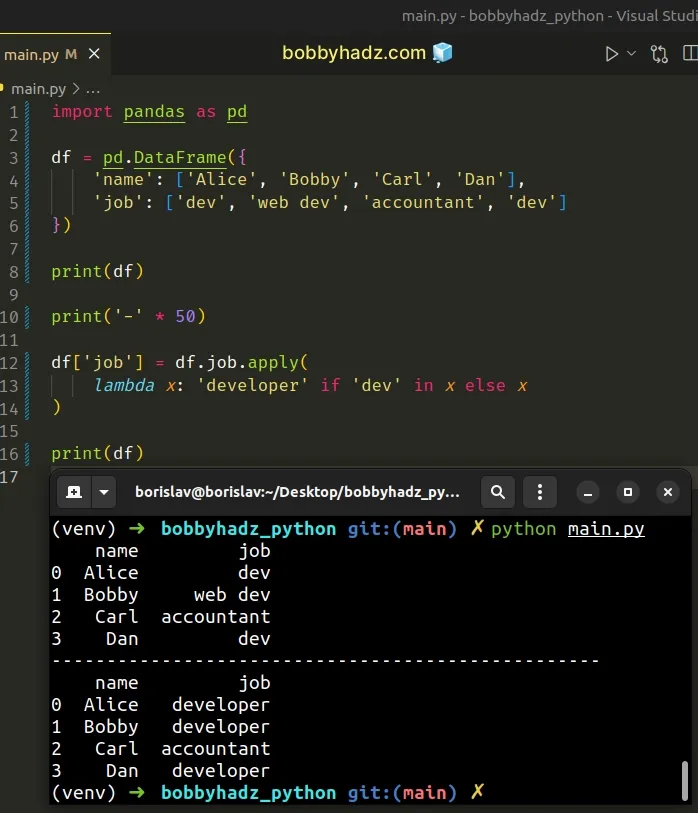
The
DataFrame.apply
method applies a function along an axis of the DataFrame.
df['job'] = df.job.apply( lambda x: 'developer' if 'dev' in x else x )
Our lambda function returns the string developer if the substring dev is
contained in the current value, otherwise, the current value is returned.
If you need to ignore the case when matching the substring in the string, use the str.lower() method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'job': ['DEV', 'web Dev', 'accountant', 'dev'] }) print(df) print('-' * 50) df['job'] = df.job.apply( lambda x: 'developer' if 'dev'.lower() in x.lower() else x ) print(df)
Running the code sample produces the following output.
name job 0 Alice DEV 1 Bobby web Dev 2 Carl accountant 3 Dan dev -------------------------------------------------- name job 0 Alice developer 1 Bobby developer 2 Carl accountant 3 Dan developer
Converting the substring we're checking for and the current string to lowercase enables us to perform a case-insensitive test whether the substring is contained in the string.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- You are trying to merge on int64 and object columns [Fixed]
- Copy a column from one DataFrame to another in Pandas
- ValueError: cannot reindex on an axis with duplicate labels
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- ValueError: cannot reshape array of size X into shape Y
- Object arrays cannot be loaded when allow_pickle=False
- ValueError: Columns must be same length as key [Solved]
- ValueError: DataFrame constructor not properly called [Fix]
- Usecols do not match columns, columns expected but not found
- Using pandas.read_csv() with multiple delimiters in Python
- Pandas: Create new row for each element in List in DataFrame
- ValueError: Length of values does not match length of index
- Reindexing only valid with uniquely valued Index objects
- Get the first Row of each Group in a Pandas DataFrame
- Convert Epoch to Datetime in a Pandas DataFrame
- How to get the Memory size of a DataFrame in Pandas
- Convert column Values to Columns in a Pandas DataFrame
- Pandas: Find length of longest String in DataFrame column
- Pandas ValueError: Cannot index with multidimensional key
- ValueError: Grouper for 'X' not 1-dimensional [Solved]
- Cannot subset columns with tuple with more than one element
- Pandas: Split a Column of Lists into Multiple Columns

