Get the first Row of each Group in a Pandas DataFrame
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Get the first row of each group in a Pandas DataFrame
- Getting the first N rows of each group in a Pandas DataFrame
- Get the first row of each group in a Pandas DataFrame by using nth()
- Using first() vs using nth(0) to get the first row of each group
- Get the first row of each column in a Pandas DataFrame by using drop_duplicates()
# Get the first row of each group in a Pandas DataFrame
To get the first row of each group in a Pandas DataFrame:
- Use the
DataFrame.groupby()method to group theDataFrame. - Use the
DataFrameGroupBy.firstmethod to get the first non-null entry of each column.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Max Speed # Animal # Cat 25 # Dog 45 print(df.groupby('Animal').first())
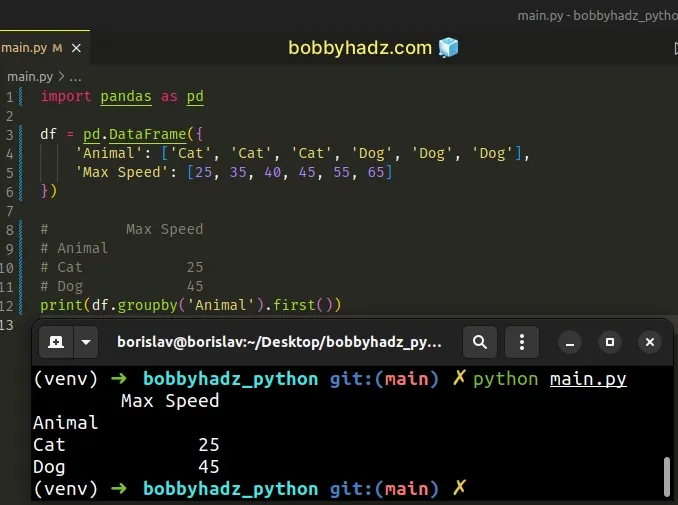
The
DataFrame.groupby()
method groups a DataFrame using one or more columns.
The method returns a DataFrameGroupBy object that contains information about
the groups.
The last step is to call the DataFrameGroupBy.first() method.
The method computes the first non-null entry of each column.
first() method returns a Series or a DataFrame containing the first non-null value within each group.If you need to reset the index, call the DataFrame.reset_index method.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Animal Max Speed # 0 Cat 25 # 1 Dog 45 print(df.groupby('Animal').first().reset_index())

The DataFrame.reset_index() method resets the index of the DataFrame, so the
default index is used.
# Getting the first N rows of each group in a Pandas DataFrame
If you need to get the first N rows of each group in a Pandas DataFrame:
- Use the
DataFrame.head()method to return the first N rows of each group. - Optionally reset the index.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Animal Max Speed # 0 Cat 25 # 1 Cat 35 # 2 Dog 45 # 3 Dog 55 print(df.groupby('Animal').head(2).reset_index(drop=True))
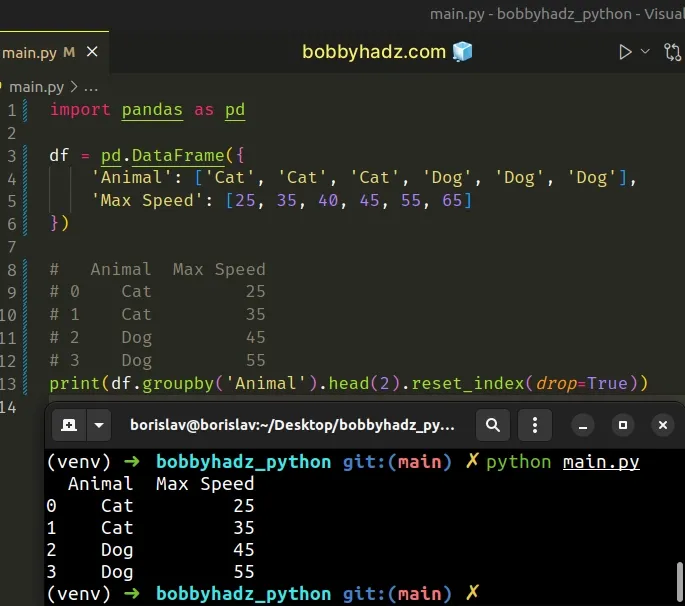
The
DataFrame.head()
method returns the first N rows of the DataFrame based on position.
The only argument the method takes is the number of rows to be selected.
We also called the reset_index method with drop=True in the example.
When the drop argument is set to True, the index is reset to the default
integer index.
The argument defaults to False.
However, calling the reset_index() method on the result is optional.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Animal Max Speed # 0 Cat 25 # 1 Cat 35 # 3 Dog 45 # 4 Dog 55 print(df.groupby('Animal').head(2))
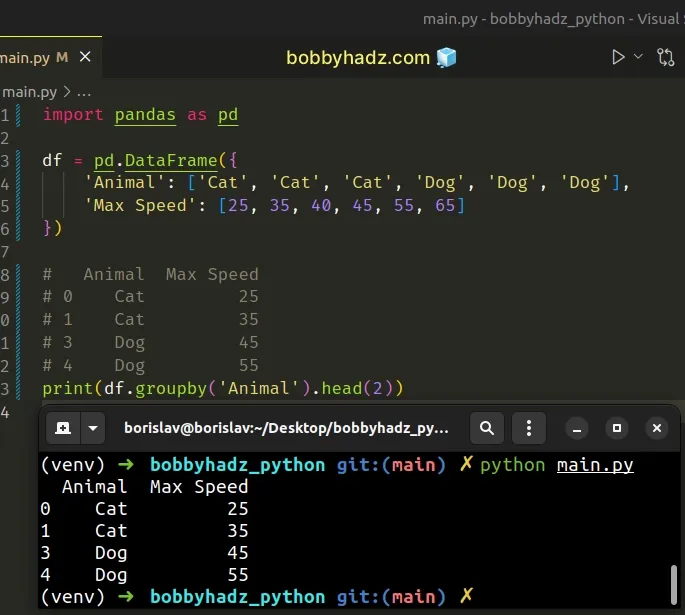
# Get the first row of each group in a Pandas DataFrame by using nth()
You can also use the
DataFrameGroupBy.nth
method to get the first row of each group in a DataFrame.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Animal Max Speed # 0 Cat 25 # 3 Dog 45 print(df.groupby('Animal').nth(0))
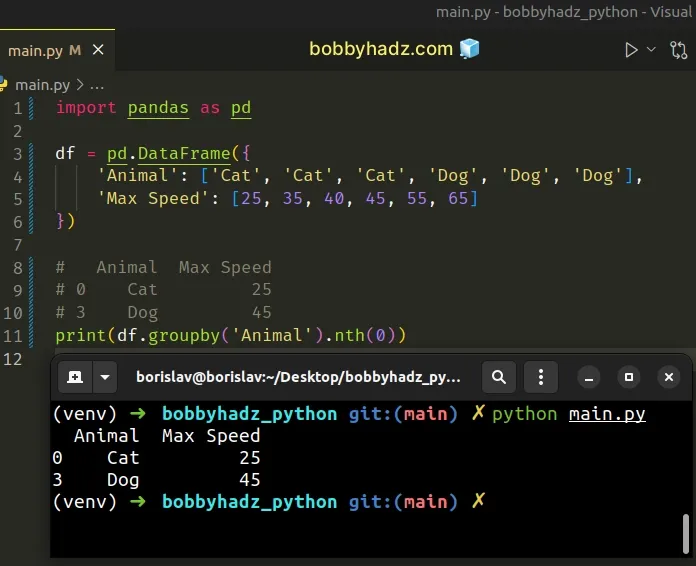
The DataFrameGroupBy.nth() method returns the Nth row from each group.
The only parameter we passed to the method is the row index to be returned.
Notice that indices are zero-based, so the first row has an index of 0, the
second an index of 1, etc.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Animal Max Speed # 1 Cat 35 # 4 Dog 55 print(df.groupby('Animal').nth(1))
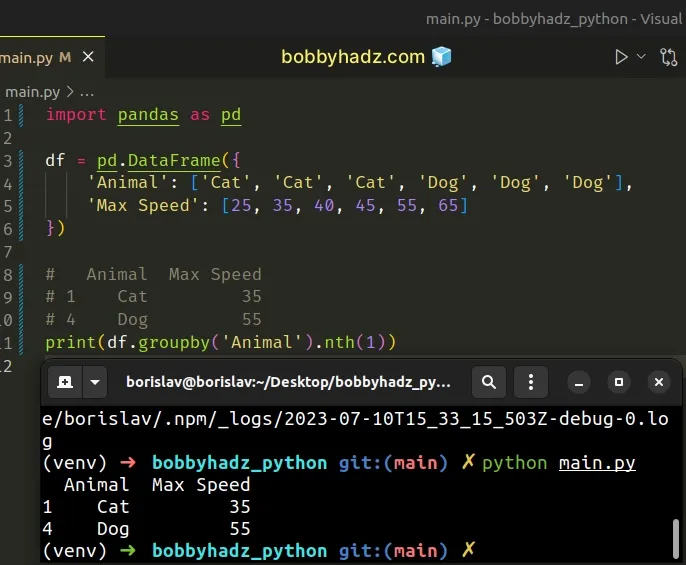
We used an index of 1, so the second row of each group in the DataFrame is
returned.
# Using first() vs using nth(0) to get the first row of each group
Note that there are some minor differences between using first() and nth(0)
to get the first row of each group.
The nth(0) approach returns the first row of each group regardless of what the
values in the row are.
On the other hand, the first() method returns the first non-null (or
non-NaN) value in each column.
Here is an example that better illustrates how this works.
import pandas as pd import numpy as np df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [np.nan, 35, 40, 45, 55, 65] }) # Max Speed # Animal # Cat 35.0 # Dog 45.0 print(df.groupby('Animal').first()) print('-' * 50) # Animal Max Speed # 0 Cat NaN # 3 Dog 45.0 print(df.groupby('Animal').nth(0))
The first row in the Max Speed column is a NaN value.
Calling the first() method returned the first not-NaN row of each group.
On the other hand, calling nth(0) simply returned the first row of each group,
without checking for NaN.
# Get the first row of each column in a Pandas DataFrame by using drop_duplicates()
You can also use the
DataFrame.drop_duplicates()
method to get the first row of each column in a Pandas DataFrame.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) # Animal Max Speed # 0 Cat 25 # 3 Dog 45 print(df.drop_duplicates('Animal'))
The drop_duplicates() method returns a DataFrame object with the duplicate
rows removed.
By default, all of the columns are considered when identifying duplicates.
If you want to modify the original DataFrame to only contain the first row of
each group, set the inplace argument to True.
import pandas as pd df = pd.DataFrame({ 'Animal': ['Cat', 'Cat', 'Cat', 'Dog', 'Dog', 'Dog'], 'Max Speed': [25, 35, 40, 45, 55, 65] }) df.drop_duplicates('Animal', inplace=True) # Animal Max Speed # 0 Cat 25 # 3 Dog 45 print(df)
When the inplace argument is set to True, the method returns None and
modifies the original DataFrame rather than creating a new one.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: Columns must be same length as key [Solved]
- ValueError: DataFrame constructor not properly called [Fix]
- Usecols do not match columns, columns expected but not found
- Using pandas.read_csv() with multiple delimiters in Python
- ValueError: Cannot merge a Series without a name [Solved]
- Index(...) must be called with a collection of some kind
- ValueError: Shape of passed values is X, indices imply Y
- ValueError: Length of values does not match length of index
- Convert Epoch to Datetime in a Pandas DataFrame
- How to get the Memory size of a DataFrame in Pandas
- Pandas: Select distinct across multiple DataFrame columns
- Pandas: Strip whitespace from Column Headers in DataFrame
- Replace negative Numbers in a Pandas DataFrame with Zero
- Calculate the Average for each Row in a Pandas DataFrame
- How to drop all Rows in a Pandas DataFrame in Python
- How to drop all Rows in a Pandas DataFrame in Python
- Pandas: Get Nth row or every Nth row in a DataFrame
- Pandas: Select Rows between two values in DataFrame
- Sklearn ValueError: Unknown label type: 'continuous' [Fixed]
- ValueError: If using all scalar values, you must pass index

