How to repeat Rows N times in a Pandas DataFrame
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- How to repeat Rows N times in a Pandas DataFrame
- Repeating each row N times in a DataFrame based on another column
- Repeat Rows N times in a Pandas DataFrame using np.repeat()
- Repeat Rows N times in a Pandas DataFrame using pd.concat()
# How to repeat Rows N times in a Pandas DataFrame
Use the DataFrame.index.repeat() method to repeat the rows in a Pandas
DataFrame N times.
The repeat() method will repeat each index in the DataFrame the specified
number of times.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = df.loc[df.index.repeat(2)] print(df2)
Running the code sample produces the following output.
first_name salary 0 Alice 175.1 0 Alice 175.1 1 Bobby 180.2 1 Bobby 180.2 2 Carl 190.3 2 Carl 190.3
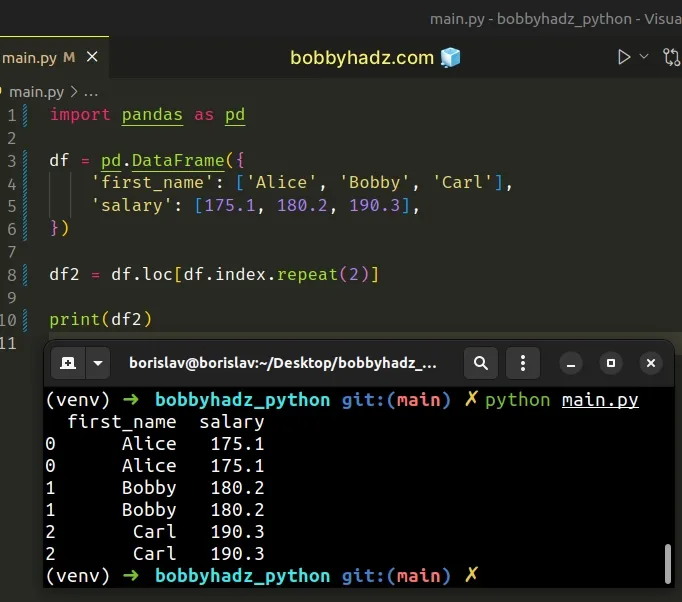
The index.repeat() method repeats the elements of an index.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) # 👇️ Index([0, 0, 1, 1, 2, 2], dtype='int64') print(df.index.repeat(2))
We then used the DataFrame.loc indexer to access the group of rows and columns by the indices.
df2 = df.loc[df.index.repeat(2)] # first_name salary # 0 Alice 175.1 # 0 Alice 175.1 # 1 Bobby 180.2 # 1 Bobby 180.2 # 2 Carl 190.3 # 2 Carl 190.3 print(df2)
Notice that there are also repeat indices in the output.
If you want to reset the indices, use the DataFrame.reset_index() method.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = df.loc[df.index.repeat(2)].reset_index(drop=True) print(df2)
Running the code sample produces the following output.
first_name salary 0 Alice 175.1 1 Alice 175.1 2 Bobby 180.2 3 Bobby 180.2 4 Carl 190.3 5 Carl 190.3
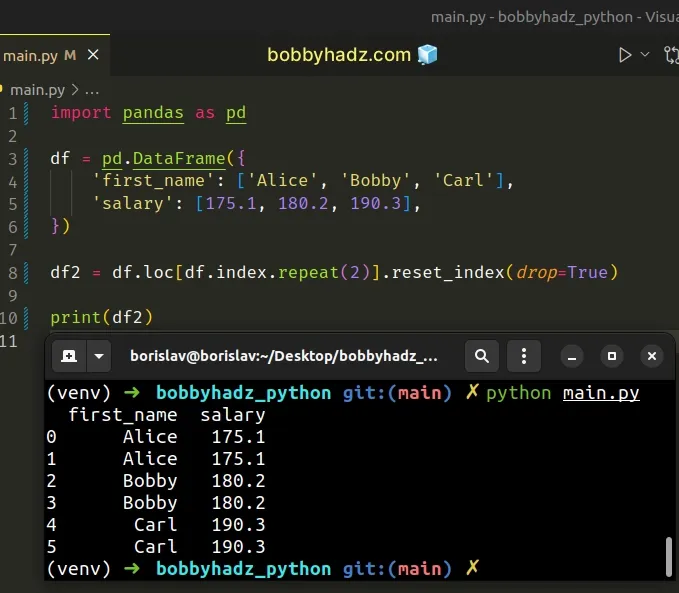
The DataFrame.reset_index
method resets the index of the DataFrame, so the default index is used.
# Repeating each row N times in a DataFrame based on another column
The same approach can be used to repeat each row N times based on another column.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'times': [1, 2, 3], }) df2 = df.loc[df.index.repeat(df.times)].reset_index(drop=True) # first_name times # 0 Alice 1 # 1 Bobby 2 # 2 Bobby 2 # 3 Carl 3 # 4 Carl 3 # 5 Carl 3 print(df2)
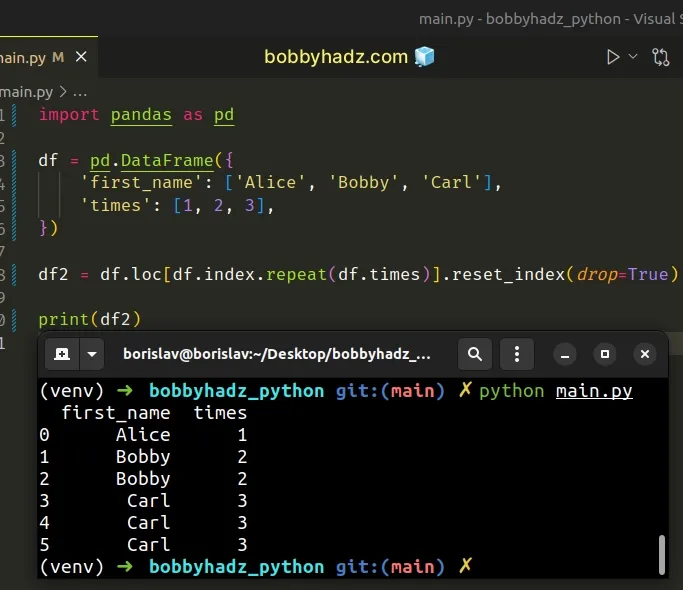
We used the times column to repeat each row N times.
The first row is not repeated, the second row is repeated once and the third row is repeated twice in the example.
The code sample also uses the reset_index() method to reset the index,
however, this is optional.
# Repeat Rows N times in a Pandas DataFrame using np.repeat()
You can also use the
numpy.repeat()
method to repeat the rows of a DataFrame N times.
import pandas as pd import numpy as np df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = pd.DataFrame(np.repeat(df.values, 2, axis=0)) df2.columns = df.columns print(df2)
Running the code sample produces the following output.
first_name salary 0 Alice 175.1 1 Alice 175.1 2 Bobby 180.2 3 Bobby 180.2 4 Carl 190.3 5 Carl 190.3
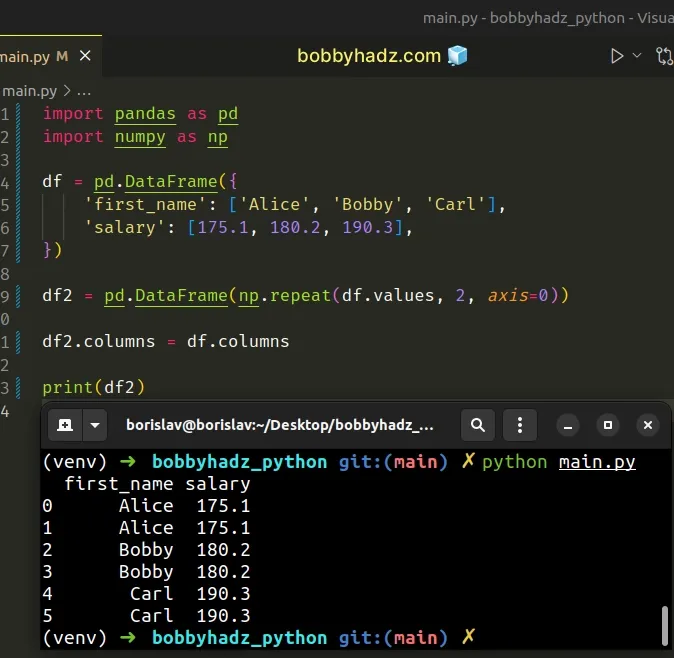
Make sure you have the numpy module installed to be able to run the code sample.
pip install pandas numpy # or with pip3 pip3 install pandas numpy
The numpy.repeat() method takes an input array, the number of repetitions and
the axis as parameters and returns an array with the repeated values.
import pandas as pd import numpy as np df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) # [['Alice' 175.1] # ['Alice' 175.1] # ['Bobby' 180.2] # ['Bobby' 180.2] # ['Carl' 190.3] # ['Carl' 190.3]] print(np.repeat(df.values, 2, axis=0))
We have to pass the array to the pandas.DataFrame() constructor and set the
columns of the new DataFrame to the columns of the existing DataFrame.
df2 = pd.DataFrame(np.repeat(df.values, 2, axis=0)) df2.columns = df.columns
You can also set the columns when initializing the new DataFrame.
import pandas as pd import numpy as np df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = pd.DataFrame(np.repeat(df.values, 2, axis=0), columns=df.columns) # first_name salary # 0 Alice 175.1 # 1 Alice 175.1 # 2 Bobby 180.2 # 3 Bobby 180.2 # 4 Carl 190.3 # 5 Carl 190.3 print(df2)
The code sample uses the column argument of the pandas.DataFrame() class to
achieve the same result.
You can also use the loc indexer as we did in the first subheading.
import pandas as pd import numpy as np df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = df.loc[np.repeat(df.index, 2)].reset_index(drop=True) # first_name salary # 0 Alice 175.1 # 1 Alice 175.1 # 2 Bobby 180.2 # 3 Bobby 180.2 # 4 Carl 190.3 # 5 Carl 190.3 print(df2)
However, when using the df.loc indexer, we have to manually reset the indices
of the DataFrame by calling reset_index().
# Repeat Rows N times in a Pandas DataFrame using pd.concat()
You can also use the
pandas.concat
method to repeat the rows in a DataFrame N times.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = pd.concat([df] * 2).sort_index().reset_index(drop=True) # first_name salary # 0 Alice 175.1 # 1 Alice 175.1 # 2 Bobby 180.2 # 3 Bobby 180.2 # 4 Carl 190.3 # 5 Carl 190.3 print(df2)
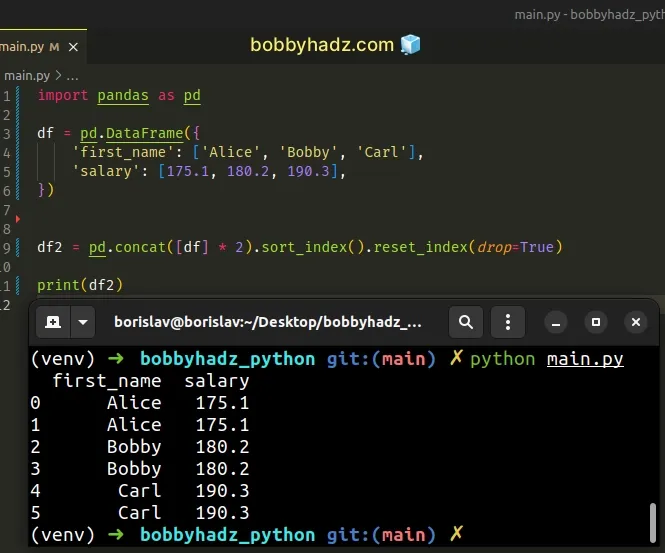
The pandas.concat() method concatenates Pandas objects along a particular
axis.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) # first_name salary # 0 Alice 175.1 # 1 Bobby 180.2 # 2 Carl 190.3 # 0 Alice 175.1 # 1 Bobby 180.2 # 2 Carl 190.3 print(pd.concat([df] * 2))
We then have to:
- Use the sort_index method to sort the indices.
- Use the
reset_index()method to reset the indices of theDataFrame.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'salary': [175.1, 180.2, 190.3], }) df2 = pd.concat([df] * 2).sort_index().reset_index(drop=True) # first_name salary # 0 Alice 175.1 # 1 Alice 175.1 # 2 Bobby 180.2 # 3 Bobby 180.2 # 4 Carl 190.3 # 5 Carl 190.3 print(df2)
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- AttributeError: Can only use .dt accessor with datetimelike values
- Count number of non-NaN values in each column of DataFrame
- Add a column with incremental Numbers to a Pandas DataFrame
- Usecols do not match columns, columns expected but not found
- ValueError: Shape of passed values is X, indices imply Y
- ValueError: Length of values does not match length of index
- How to add a Level to Pandas MultiIndex in Python
- Pandas: Convert GroupBy results to Dictionary of Lists
- Pandas: How to get the Max and Min Dates in a DataFrame
- Cannot perform 'rand_' with a dtyped [int64] array and scalar of type [bool]
- Pandas ValueError: Cannot index with multidimensional key
- ValueError: Grouper for 'X' not 1-dimensional [Solved]
- Cannot subset columns with tuple with more than one element
- Pandas: Get Nth row or every Nth row in a DataFrame
- Pandas: Convert Month Number to Month Name and vice versa
- Pandas: Select first N or last N columns of DataFrame
- Filter rows in a Pandas DataFrame using Regex
- Pandas: Element-wise logical NOT and logical OR operators
- Update a Pandas DataFrame while iterating over its rows
- NumPy: Get the indices of the N largest values in an Array

