Concatenate strings from multiple rows with Pandas GroupBy
Last updated: Apr 12, 2024
Reading time·6 min

# Table of Contents
- Concatenate strings from multiple rows with Pandas GroupBy
- Concatenate strings from multiple rows with Pandas GroupBy based on multiple columns
- Concatenate strings from multiple rows with Pandas GroupBy with apply()
- Concatenate strings from multiple rows with Pandas GroupBy based on multiple columns using apply()
- Concatenate strings from multiple rows with Pandas GroupBy using agg()
# Concatenate strings from multiple rows with Pandas GroupBy
To concatenate strings from multiple rows with Pandas groupby():
- Use the
groupby()method to group theDataFrameon one or more columns. - Access the column you want to join and call the
transform()method. - Use the
str.join()method to concatenate the matching strings.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Bobby', 'Carl', 'Dan', 'Ethan' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-21', '2023-08-23' ] }) # Name Date # 0 Alice 2023-07-12 # 1 Bobby 2023-07-12 # 2 Carl 2023-08-23 # 3 Dan 2023-08-21 # 4 Ethan 2023-08-23 print(df) print('-' * 50) df['Name'] = df.groupby(['Date'])['Name'].transform(','.join) df = df[['Name', 'Date']].drop_duplicates() # Name Date # 0 Alice,Bobby 2023-07-12 # 2 Carl,Ethan 2023-08-23 # 3 Dan 2023-08-21 print(df)
Running the code sample produces the following output.
Name Date 0 Alice 2023-07-12 1 Bobby 2023-07-12 2 Carl 2023-08-23 3 Dan 2023-08-21 4 Ethan 2023-08-23 -------------------------------------------------- Name Date 0 Alice,Bobby 2023-07-12 2 Carl,Ethan 2023-08-23 3 Dan 2023-08-21
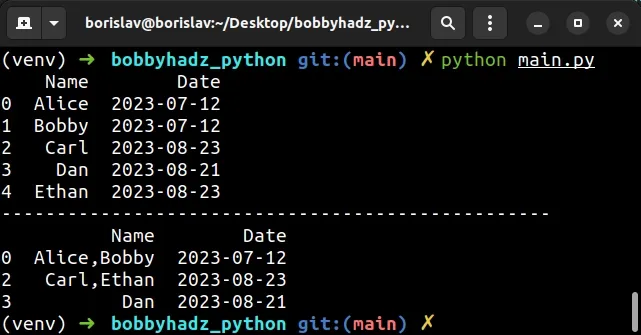
We used the
groupby()
method to group the DataFrame based on the Date column.
The
DataFrame.transform
method is used to call the supplied function on the DataFrame object.
df['Name'] = df.groupby(['Date'])['Name'].transform(','.join) df = df[['Name', 'Date']].drop_duplicates() # Name Date # 0 Alice,Bobby 2023-07-12 # 2 Carl,Ethan 2023-08-23 # 3 Dan 2023-08-21 print(df)
We used the str.join() method to join the matching rows with a comma ",",
however, you can specify any other separator (or a space " ".join).
The last step is to call the DataFrame.drop_duplicates method.
The method returns a DataFrame object with the duplicates removed.
We only removed the duplicates from the Name and Date columns, however, you
can also call the method on the entire DataFrame.
df = df.drop_duplicates()
# Concatenate strings from multiple rows with Pandas GroupBy based on multiple columns
You can use the same approach in the scenario that you have to group based on multiple columns.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Alice', 'Bobby', 'Bobby', 'Carl' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-23', '2023-08-21' ], 'Tasks': ['A', 'B', 'C', 'D', 'E'] }) # Name Date Tasks # 0 Alice 2023-07-12 A # 1 Alice 2023-07-12 B # 2 Bobby 2023-08-23 C # 3 Bobby 2023-08-23 D # 4 Carl 2023-08-21 E print(df) print('-' * 50) df['Tasks'] = df.groupby(['Date', 'Name'])['Tasks'].transform(','.join) df = df.drop_duplicates() # Name Date Tasks # 0 Alice 2023-07-12 A,B # 2 Bobby 2023-08-23 C,D # 4 Carl 2023-08-21 E print(df)
Running the code sample produces the following output.
Name Date Tasks 0 Alice 2023-07-12 A 1 Alice 2023-07-12 B 2 Bobby 2023-08-23 C 3 Bobby 2023-08-23 D 4 Carl 2023-08-21 E -------------------------------------------------- Name Date Tasks 0 Alice 2023-07-12 A,B 2 Bobby 2023-08-23 C,D 4 Carl 2023-08-21 E
We passed 2 column names to the groupby() method - Date and Name.
The next step is to access the Tasks column and call transform() to join the
matching rows.
df['Tasks'] = df.groupby(['Date', 'Name'])['Tasks'].transform(','.join) df = df.drop_duplicates() # Name Date Tasks # 0 Alice 2023-07-12 A,B # 2 Bobby 2023-08-23 C,D # 4 Carl 2023-08-21 E print(df)
The last step is to remove the duplicate rows by calling drop_duplicates().
# Concatenate strings from multiple rows with Pandas GroupBy with apply()
You can also call the apply() method on the result of calling
DataFrame.groupby()
to concatenate strings from multiple rows with groupby() in pandas.
The apply() method should apply the str.join() method to join the matching
rows.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Bobby', 'Carl', 'Dan', 'Ethan' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-21', '2023-08-23' ] }) # Name Date # 0 Alice 2023-07-12 # 1 Bobby 2023-07-12 # 2 Carl 2023-08-23 # 3 Dan 2023-08-21 # 4 Ethan 2023-08-23 print(df) print('-' * 50) # Date Name # 0 2023-07-12 Alice,Bobby # 1 2023-08-21 Dan # 2 2023-08-23 Carl,Ethan print(df.groupby(['Date'])['Name'].apply(','.join).reset_index())
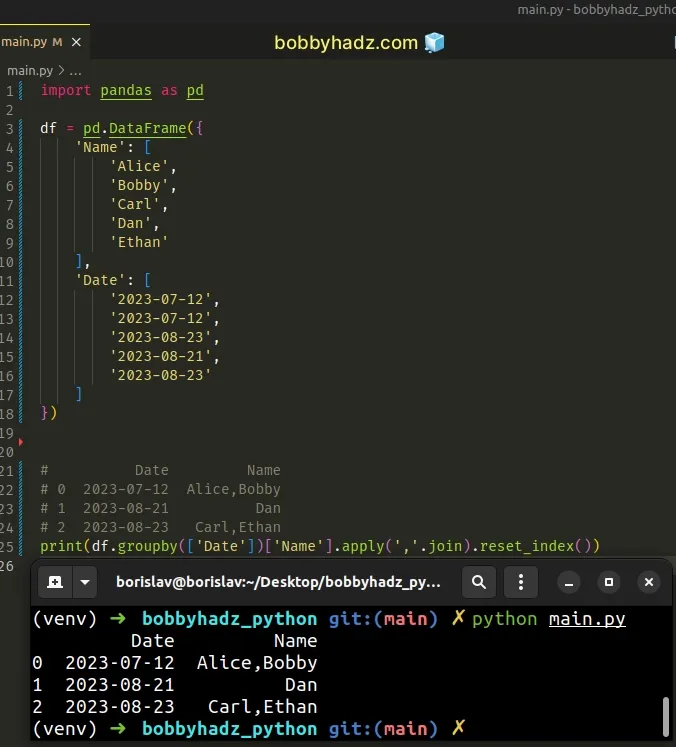
We used the
groupby()
method to group the DataFrame based on the Date column.
We then accessed the Name column and called
apply()
on the result.
The apply() method applies a function along an axis of the DataFrame.
We passed the str.join method
to apply() to join the matching rows from the Name column with a comma
separator.
Note: we used a comma in the example, however, you can use any other separator
(or a space " ").
The last step is to use the
DataFrame.reset_index() method
to reset the index of the DataFrame and use the default index instead.
# Concatenate strings from multiple rows with Pandas GroupBy based on multiple columns using apply()
In some cases, you might have to call groupby() with multiple columns.
Let's look at an example.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Alice', 'Bobby', 'Bobby', 'Carl' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-23', '2023-08-21' ], 'Tasks': ['A', 'B', 'C', 'D', 'E'] }) # Name Date Tasks # 0 Alice 2023-07-12 A # 1 Alice 2023-07-12 B # 2 Bobby 2023-08-23 C # 3 Bobby 2023-08-23 D # 4 Carl 2023-08-21 E print(df) print('-' * 50) # Name Date Tasks # 0 Alice 2023-07-12 A,B # 1 Bobby 2023-08-23 C,D # 2 Carl 2023-08-21 E print( df.groupby(['Name', 'Date'])['Tasks'].apply(','.join).reset_index() )
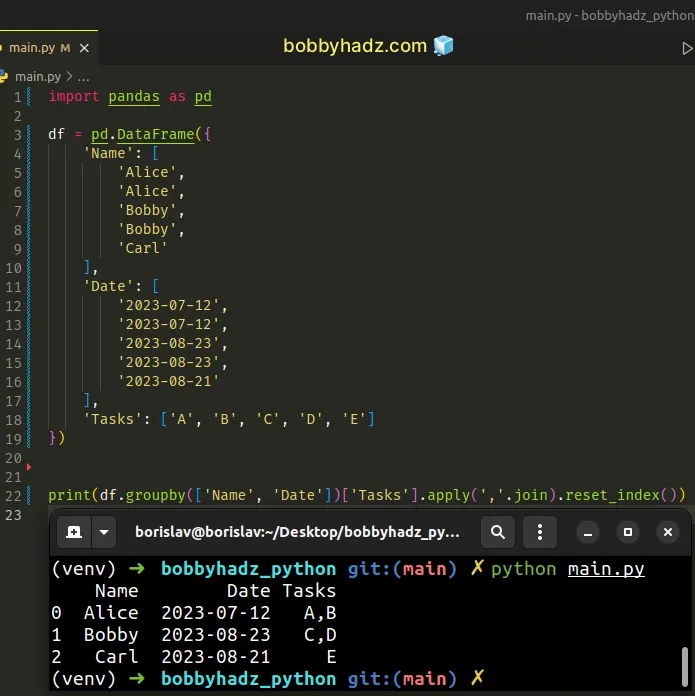
We grouped the DataFrame based on the Name and Date columns, accessed the
Tasks column and joined the matching rows.
In some cases, you might also just want to concatenate the strings into a column of lists.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Alice', 'Bobby', 'Bobby', 'Carl' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-23', '2023-08-21' ], 'Tasks': ['A', 'B', 'C', 'D', 'E'] }) # Name Date Tasks # 0 Alice 2023-07-12 A # 1 Alice 2023-07-12 B # 2 Bobby 2023-08-23 C # 3 Bobby 2023-08-23 D # 4 Carl 2023-08-21 E print(df) print('-' * 50) # Date Name # 2023-07-12 Alice [A, B] # 2023-08-21 Carl [E] # 2023-08-23 Bobby [C, D] # Name: Tasks, dtype: object print(df.groupby(['Date', 'Name'])['Tasks'].apply(list))
The list class gets called with the matching
rows and converts them to list objects.
# Concatenate strings from multiple rows with Pandas GroupBy using agg()
Once you group the columns, you can also use the DataFrame.agg() method to concatenate strings from multiple rows.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Alice', 'Bobby', 'Bobby', 'Carl' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-23', '2023-08-21' ], 'Tasks': ['A', 'B', 'C', 'D', 'E'] }) # Name Date Tasks # 0 Alice 2023-07-12 A # 1 Alice 2023-07-12 B # 2 Bobby 2023-08-23 C # 3 Bobby 2023-08-23 D # 4 Carl 2023-08-21 E print(df) print('-' * 50) # Date Name Tasks # 0 2023-07-12 Alice A,B # 1 2023-08-21 Carl E # 2 2023-08-23 Bobby C,D print(df.groupby(['Date', 'Name'], as_index=False)[ 'Tasks'].agg({'Tasks': ','.join}))
Running the code sample produces the following output.
Name Date Tasks 0 Alice 2023-07-12 A 1 Alice 2023-07-12 B 2 Bobby 2023-08-23 C 3 Bobby 2023-08-23 D 4 Carl 2023-08-21 E -------------------------------------------------- Date Name Tasks 0 2023-07-12 Alice A,B 1 2023-08-21 Carl E 2 2023-08-23 Bobby C,D
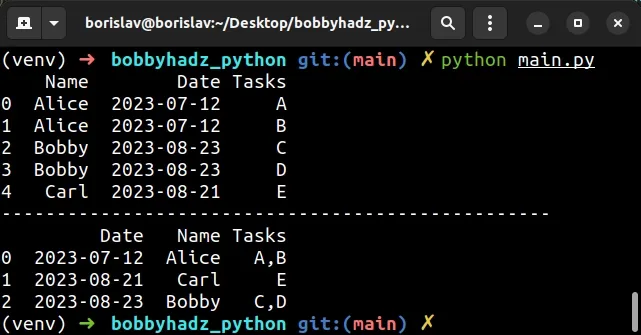
The
DataFrame.agg
method can be called with a dict of axis labels -> functions.
The method aggregates over one or more operations over the specified axis.
In some cases, you might also just want to concatenate the strings into a column of lists.
import pandas as pd df = pd.DataFrame({ 'Name': [ 'Alice', 'Alice', 'Bobby', 'Bobby', 'Carl' ], 'Date': [ '2023-07-12', '2023-07-12', '2023-08-23', '2023-08-23', '2023-08-21' ], 'Tasks': ['A', 'B', 'C', 'D', 'E'] }) # Name Date Tasks # 0 Alice 2023-07-12 A # 1 Alice 2023-07-12 B # 2 Bobby 2023-08-23 C # 3 Bobby 2023-08-23 D # 4 Carl 2023-08-21 E print(df) print('-' * 50) # Date Name Tasks # 0 2023-07-12 Alice [A, B] # 1 2023-08-21 Carl [E] # 2 2023-08-23 Bobby [C, D] print(df.groupby(['Date', 'Name'], as_index=False)[ 'Tasks'].agg({'Tasks': list}))
The list class gets called with the matching
rows and converts them to list objects.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Convert a Row to a Column Header in a Pandas DataFrame
- IndexError: single positional indexer is out-of-bounds [Fix]
- Arrays used as indices must be of integer (or boolean) type
- Boolean index did not match indexed array along dimension 0
- AttributeError: Can only use .dt accessor with datetimelike values
- Replace whole String if it contains Substring in Pandas
- Pandas: Create new row for each element in List in DataFrame
- ValueError: Length of values does not match length of index
- Get the first Row of each Group in a Pandas DataFrame
- Convert Epoch to Datetime in a Pandas DataFrame
- Calculate the Average for each Row in a Pandas DataFrame
- How to drop all Rows in a Pandas DataFrame in Python
- Pandas: Drop columns if Name contains a given String
- Pandas: How to get the Max and Min Dates in a DataFrame
- Pandas SpecificationError: nested renamer is not supported
- Pandas: Convert a DataFrame to a List of Dictionaries
- Pandas: GroupBy columns with NaN (missing) values
- NumPy: Get the indices of the N largest values in an Array
- Pandas: Find an element's Index in Series [7 Ways]

