Using pandas.read_csv() with multiple delimiters in Python
Last updated: Apr 11, 2024
Reading time·5 min

# Table of Contents
- Using pandas.read_csv() with multiple delimiters in Python
- Using pandas.read_csv() with multiple delimiters with a character class
- Specifying multiple delimiters when parsing CSV file in Python
# Using pandas.read_csv() with multiple delimiters in Python
Set the sep argument to a regular expression to use the pandas.read_csv()
method with multiple delimiters.
The sep argument is used to specify the delimiter(s) that should be used
when parsing the CSV file.
Suppose we have the following employees.csv file.
first_name,last_name,date Alice;Smith;2023-01-05 Bobby,Hadz,2023-03-25 Carl@Lemon@2021-01-24
And here is the related main.py script.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=r',|;|@', encoding='utf-8', engine='python' ) # first_name last_name date # 0 Alice Smith 2023-01-05 # 1 Bobby Hadz 2023-03-25 # 2 Carl Lemon 2021-01-24 print(df)
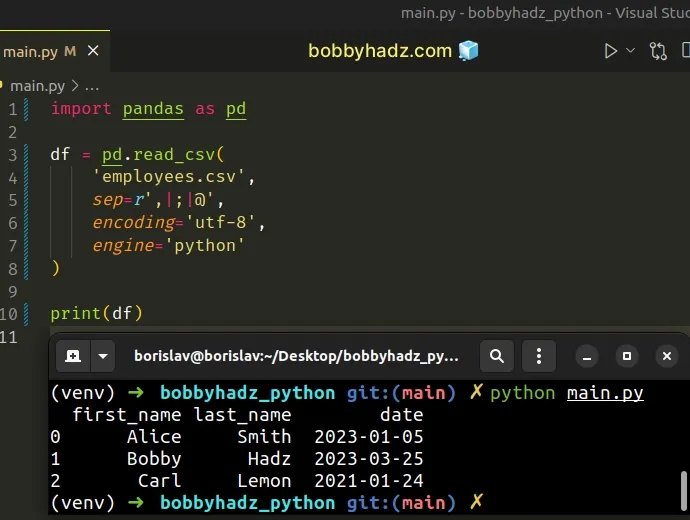
The
pandas.read_csv()
method reads a comma-separated values (CSV) file into a DataFrame.
sep argument to a regular expression to be able to specify multiple delimiters when parsing the CSV file.The CSV file in the example has 3 delimiters:
- A comma
,. - A semicolon
;. - An
@symbol.
df = pd.read_csv( 'employees.csv', sep=r',|;|@', encoding='utf-8', engine='python' )
We prefixed the string with an r to mark it as a raw string.
The pipe | special character means OR, e.g. X|Y matches X or Y.
In its entirety, the regular expression means: "The separator is a comma ,,
a semicolon ; or an @ symbol".
Some commonly used delimiters include:
- a comma
, - a semicolon
; - a space
- a tab character
\t - a pipe
|
engine keyword argument to "python".If you forget to set the engine explicitly, you'd get a warning:
- ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
The C engine doesn't support regex separators, so we should explicitly set the
engine to "python" to solve the issue.
df = pd.read_csv( 'employees.csv', sep=r',|;|@', encoding='utf-8', engine='python' )
Let's look at a CSV file that also uses a space as the delimiter.
first_name,last_name,date Alice;Smith;2023-01-05 Bobby Hadz 2023-03-25 Carl@Lemon@2021-01-24
You can use the space approach to read the CSV file with a comma ,, a
semicolon ;, a space and an @ symbol delimiters.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=r',|;|@| ', encoding='utf-8', engine='python' ) # first_name last_name date # 0 Alice Smith 2023-01-05 # 1 Bobby Hadz 2023-03-25 # 2 Carl Lemon 2021-01-24 print(df)
Notice that we added a space after the last pipe | character.
You can also use the special \s character to match whitespace characters.
df = pd.read_csv( 'employees.csv', sep=r',|;|@|\s+', encoding='utf-8', engine='python' )
The \s+ characters match one or more whitespace characters.
# Using pandas.read_csv() with multiple delimiters with a character class
You can also set the sep argument to a character class to use the
pandas.read_csv() method with multiple delimiters.
Suppose we have the following employees.csv file.
first_name,last_name,date Alice;Smith;2023-01-05 Bobby Hadz 2023-03-25 Carl@Lemon@2021-01-24
Here is the related main.py file.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=r'[ ,;@]', encoding='utf-8', engine='python' ) # first_name last_name date # 0 Alice Smith 2023-01-05 # 1 Bobby Hadz 2023-03-25 # 2 Carl Lemon 2021-01-24 print(df)
Note that this approach should only be used when your delimiters only consist of a single character.
If your delimiters consist of multiple characters, use the approach from the previous subheading.
[] syntax is called a character class and matches any of the characters between the brackets.The example uses a space, a comma ,, a semicolon ; and an @ symbol as the
delimiters.
# Specifying multiple delimiters when parsing CSV file in Python
If you need to specify multiple delimiters when parsing a CSV file in pure Python, without loading any third-party libraries, use the re.split method.
Here is the employee.csv file for the example.
first_name,last_name,date Alice;Smith;2023-01-05 Bobby Hadz 2023-03-25 Carl@Lemon@2021-01-24
And here is the related main.py file.
import re with open('employees.csv', 'r', encoding='utf-8') as csv_file: for line in csv_file: line_values = re.split(r',|;| |@', line) print(line_values)
Running the code sample produces the following output.
['first_name', 'last_name', 'date\n'] ['Alice', 'Smith', '2023-01-05\n'] ['Bobby', 'Hadz', '2023-03-25\n'] ['Carl', 'Lemon', '2021-01-24\n']
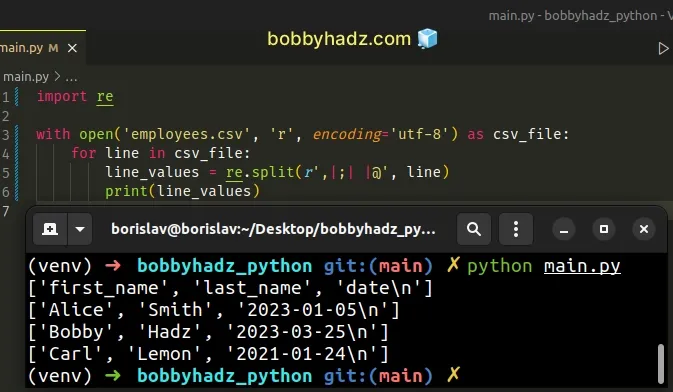
We used the with open() statement to open the CSV file.
The with statement takes care of automatically closing the file even if an
error occurs.
The next step is to use a for loop to iterate over the lines in the file.
re.split() method to split each line string on multiple delimiters.The re.split() method takes a pattern and a string and splits the string on
each occurrence of the pattern.
You can use the pipe | character to separate your delimiters.
Alternatively, you can use a character class and specify your delimiters between the square brackets.
import re with open('employees.csv', 'r', encoding='utf-8') as csv_file: for line in csv_file: line_values = re.split(r'[,; @]', line) # ['first_name', 'last_name', 'date\n'] # ['Alice', 'Smith', '2023-01-05\n'] # ['Bobby', 'Hadz', '2023-03-25\n'] # ['Carl', 'Lemon', '2021-01-24\n'] print(line_values)
The example uses a comma ,, a semicolon ;, a space and the @ symbol as
delimiters.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- You are trying to merge on int64 and object columns [Fixed]
- Copy a column from one DataFrame to another in Pandas
- ValueError: cannot reindex on an axis with duplicate labels
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- ValueError: cannot reshape array of size X into shape Y
- Object arrays cannot be loaded when allow_pickle=False
- ValueError: Columns must be same length as key [Solved]
- ValueError: DataFrame constructor not properly called [Fix]
- Usecols do not match columns, columns expected but not found
- Pandas: Create new row for each element in List in DataFrame
- ValueError: Cannot merge a Series without a name [Solved]
- Index(...) must be called with a collection of some kind
- ValueError: Shape of passed values is X, indices imply Y
- ValueError: Length of values does not match length of index
- Cannot concatenate object of type 'X'; only Series and DataFrame objs are valid
- How to add a Count Column to a Pandas DataFrame
- Cannot set a DataFrame with multiple columns to single column
- How to swap two DataFrame columns in Pandas

