Add columns of a different Length to a DataFrame in Pandas
Last updated: Apr 12, 2024
Reading time·7 min

# Table of Contents
- Add columns of a different Length to a DataFrame in Pandas
- Adding columns of different length to a DataFrame by extending them
- Converting the additional column to a Series
- Creating a DataFrame from a dictionary with different lengths
- Creating a DataFrame from a dictionary with different lengths using from_dict()
# Add columns of a different Length to a DataFrame in Pandas
To add columns of a different length to a DataFrame in Pandas:
- Use the
pd.DataFrame()constructor to create a newDataFramewith the additional columns. - Use the
pandas.concat()method to concatenate the existing and the new DataFrames.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl'], 'experience': [10, 13, 15], }) additional_cols = pd.DataFrame({ 'salary': [1500, 1200, 2500, 3500] }) df2 = pd.concat([df, additional_cols], axis=1) print(df2)
Running the code sample produces the following output.
name experience salary 0 Alice 10.0 1500 1 Bobby 13.0 1200 2 Carl 15.0 2500 3 NaN NaN 3500
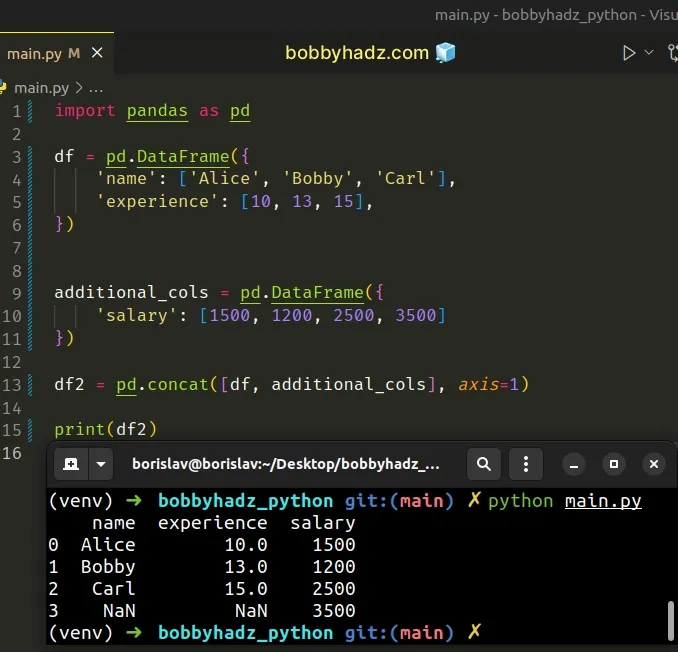
The initial DataFrame has 2 columns and 3 rows.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl'], 'experience': [10, 13, 15], }) # name experience # 0 Alice 10 # 1 Bobby 13 # 2 Carl 15 print(df)
We created a new DataFrame that has 1 column and 4 rows.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl'], 'experience': [10, 13, 15], }) additional_cols = pd.DataFrame({ 'salary': [1500, 1200, 2500, 3500] }) # salary # 0 1500 # 1 1200 # 2 2500 # 3 3500 print(additional_cols)
The last step is to use the
pandas.concat()
method to add the column of a different length to the existing DataFrame.
df2 = pd.concat([df, additional_cols], axis=1) # name experience salary # 0 Alice 10.0 1500 # 1 Bobby 13.0 1200 # 2 Carl 15.0 2500 # 3 NaN NaN 3500 print(df2)
The pandas.concat method concatenates Pandas objects along a given axis.
The axis argument is used to determine the axis along which to concatenate the
DataFrames.
0 and concatenates the objects along the index axis.Setting the axis argument to 1 means "concatenate along the columns
axis".
Notice that the values in the fourth row for the name and experience columns
are missing (NaN).
Make sure the ignore_index argument is set to False when calling
pd.concat().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl'], 'experience': [10, 13, 15], }) additional_cols = pd.DataFrame({ 'salary': [1500, 1200, 2500, 3500] }) df2 = pd.concat([df, additional_cols], axis=1, ignore_index=False) # name experience salary # 0 Alice 10.0 1500 # 1 Bobby 13.0 1200 # 2 Carl 15.0 2500 # 3 NaN NaN 3500 print(df2)
False is the default value for the ignore_index argument.
If you set the argument to True, then the column names will be lost and the
axis will be labeled 0, 1, ..., n - 1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl'], 'experience': [10, 13, 15], }) additional_cols = pd.DataFrame({ 'salary': [1500, 1200, 2500, 3500] }) df2 = pd.concat([df, additional_cols], axis=1, ignore_index=True) # 0 1 2 # 0 Alice 10.0 1500 # 1 Bobby 13.0 1200 # 2 Carl 15.0 2500 # 3 NaN NaN 3500 print(df2)
Setting the ignore_index argument to True is useful if the columns of the
objects you are concatenating don't have meaningful indexing information.
# Adding columns of different length to a DataFrame by extending them
You can also use the list.extend() method to extend the column before you add
it to the DataFrame.
import pandas as pd a = ['Alice', 'Bobby'] b = [10, 13, 15] c = [1000, 2000, 3000, 4000] a_len, b_len, c_len = len(a), len(b), len(c) max_len = max(a_len, b_len, c_len) if not max_len == a_len: a.extend([''] * (max_len - a_len)) if not max_len == b_len: b.extend([''] * (max_len - b_len)) if not max_len == c_len: c.extend([''] * (max_len - b_len)) df = pd.DataFrame({ 'A': a, 'B': b, 'C': c }) # A B C # 0 Alice 10 1000 # 1 Bobby 13 2000 # 2 15 3000 # 3 4000 print(df)
The lists in the example have different lengths.
We used the len() function to get the length of each list.
a_len, b_len, c_len = len(a), len(b), len(c)
The len() function returns the length (the number of items) of an object.
The next step is to get the maximum length.
max_len = max(a_len, b_len, c_len)
We know that the columns we have to add to the DataFrame have to be of the
same length, so we use the
list.extend() method
if the length is insufficient.
if not max_len == a_len: a.extend([''] * (max_len - a_len))
Once all lists have the same length, we use the pd.DataFrame() constructor.
df = pd.DataFrame({ 'A': a, 'B': b, 'C': c }) # A B C # 0 Alice 10 1000 # 1 Bobby 13 2000 # 2 15 3000 # 3 4000 print(df)
# Converting the additional column to a Series
If you convert the values of the additional column to Series, the extra rows
will get dropped.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl'], 'experience': [10, 13, 15], }) print(df) salary_col = [1500, 1200, 2500, 3500] df['salary'] = pd.Series(salary_col) print('-' * 50) print(df)
Running the code sample produces the following output.
name experience 0 Alice 10 1 Bobby 13 2 Carl 15 -------------------------------------------------- name experience salary 0 Alice 10 1500 1 Bobby 13 1200 2 Carl 15 2500
Notice that the new column has 4 rows.
We converted the list to a Series and added the result to the existing
DataFrame and the last row got automatically dropped.
If you omit the conversion to Series, you'd get the
ValueError: Length of values does not match length of index
error.
# Creating a DataFrame from a dictionary with different lengths
If you need to create a DataFrame from a dictionary with different length
values:
- Use a list comprehension to convert each dictionary value to a
Series. - Use the
dict()class to convert the list of key, value tuples to a dictionary. - Pass the result to the
pandas.DataFrame()constructor.
import pandas as pd a_dict = { 'name': ['Alice', 'Bobby'], 'experience': [10, 13, 15], 'salary': [1000, 2000, 3000, 4000] } df = pd.DataFrame( dict( [(key, pd.Series(value)) for key, value in a_dict.items()] ) ) # name experience salary # 0 Alice 10.0 1000 # 1 Bobby 13.0 2000 # 2 NaN 15.0 3000 # 3 NaN NaN 4000 print(df)
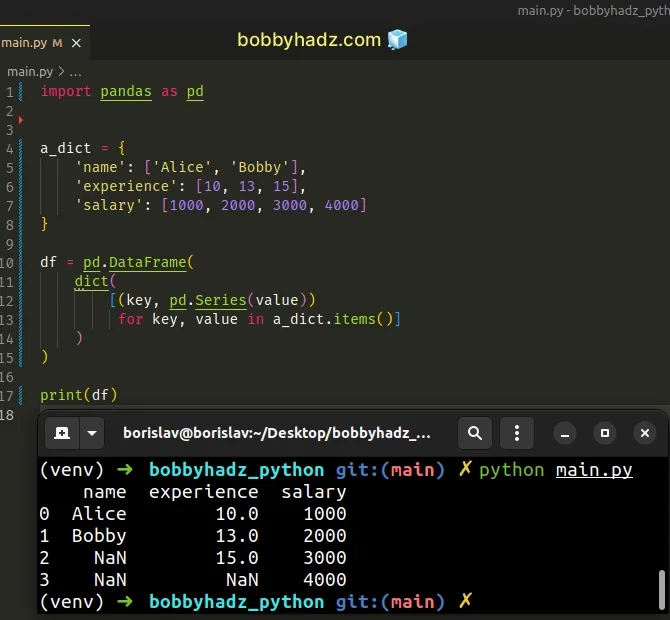
We used a list comprehension to iterate over the dictionary's items.
The dict.items() method returns a new view of the dictionary's items ((key, value) pairs).
import pandas as pd a_dict = { 'name': ['Alice', 'Bobby'], 'experience': [10, 13, 15], 'salary': [1000, 2000, 3000, 4000] } # 👇️ dict_items([('name', ['Alice', 'Bobby']), ('experience', [10, 13, 15]), ('salary', [1000, 2000, 3000, 4000])]) print(a_dict.items())
On each iteration, we convert the current value (list) to a Series and return
the key-value pair in a tuple.
Lastly, we use the dict() class to convert the list of key-value pair tuples
to a dictionary and pass the dictionary to the pandas.DataFrame() constructor.
df = pd.DataFrame( dict( [(key, pd.Series(value)) for key, value in a_dict.items()] ) ) # name experience salary # 0 Alice 10.0 1000 # 1 Bobby 13.0 2000 # 2 NaN 15.0 3000 # 3 NaN NaN 4000 print(df)
Notice that missing values are marked as NaN in the DataFrame.
# Creating a DataFrame from a dictionary with different lengths using from_dict()
You can also use the
DataFrame.from_dict()
method to create a DataFrame from a dictionary with different lengths, as long
as the orient argument is set to index.
import pandas as pd a_dict = { 'name': ['Alice', 'Bobby'], 'experience': [10, 13, 15], 'salary': [1000, 2000, 3000, 4000] } df = pd.DataFrame.from_dict(a_dict, orient='index') # 0 1 2 3 # name Alice Bobby NaN NaN # experience 10 13 15.0 NaN # salary 1000 2000 3000.0 4000.0 print(df)
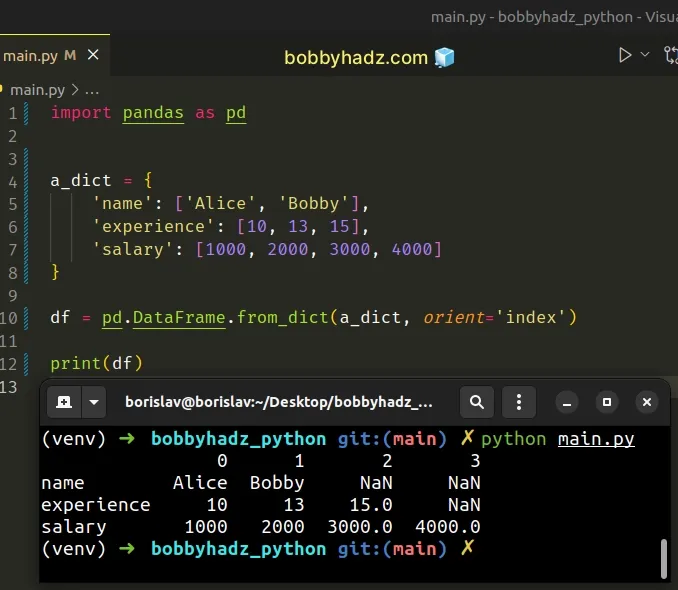
The from_dict() method constructs a DataFrame from a dictionary of
array-like objects.
The orient argument determines the orientation of the data.
We set the orient to index so the keys of the dict become rows in the
DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ufunc 'add' did not contain loop with signature matching types
- ValueError: Found array with dim 3. Estimator expected 2
- ValueError: columns overlap but no suffix specified [Solved]
- Usecols do not match columns, columns expected but not found
- Converting a Nested Dictionary to a Pandas DataFrame
- Convert column Values to Columns in a Pandas DataFrame
- How to Multiply two or more Columns in Pandas
- Pandas: Make new Column from string Slice of another Column
- Pandas: Calculate mean (average) across multiple DataFrames
- NumPy or Pandas: How to check a Value or an Array for NaT
- Reading specific columns from an Excel File in Pandas
- Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of X
- Pandas: Check if a Date is during the Weekend or Weekday
- Create Date column from Year, Month and Day in Pandas
- Pandas: How to Query a Column name with Spaces
- Pandas: Create a Tuple from two DataFrame Columns
- Cannot mask with non-boolean array containing NA / NaN values
- Disable the TOKENIZERS_PARALLELISM=(true | false) warning
- RuntimeError: Expected scalar type Float but found Double
- Pandas: Convert timezone-aware DateTimeIndex to naive timestamp
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type float)
- Mixing dicts with non-Series may lead to ambiguous ordering
- ValueError: NaTType does not support strftime [Solved]
- Cannot convert non-finite values (NA or inf) to integer
- Pandas: How to efficiently Read a Large CSV File
- Pandas: Unalignable boolean Series provided as indexer
- Pandas: Apply a Function to each Cell of a DataFrame

