Pandas: Unalignable boolean Series provided as indexer
Last updated: Apr 13, 2024
Reading time·4 min

# Pandas: Unalignable boolean Series provided as indexer
The Pandas "pandas.errors.IndexingError: Unalignable boolean Series provided
as indexer" error occurs when you try to filter a DataFrame by columns without
using the loc indexer.
To solve the error, use the loc indexer when filtering by columns.
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) # name salary experience # 0 Alice 175.1 None # 1 Bobby NaN None # 2 Carl 190.3 None # 3 Dan NaN None # 4 Ethan 210.5 None print(df) print('-' * 50) df = df[df.notnull().any(axis=0)] # ⛔️ pandas.errors.IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match). print(df)
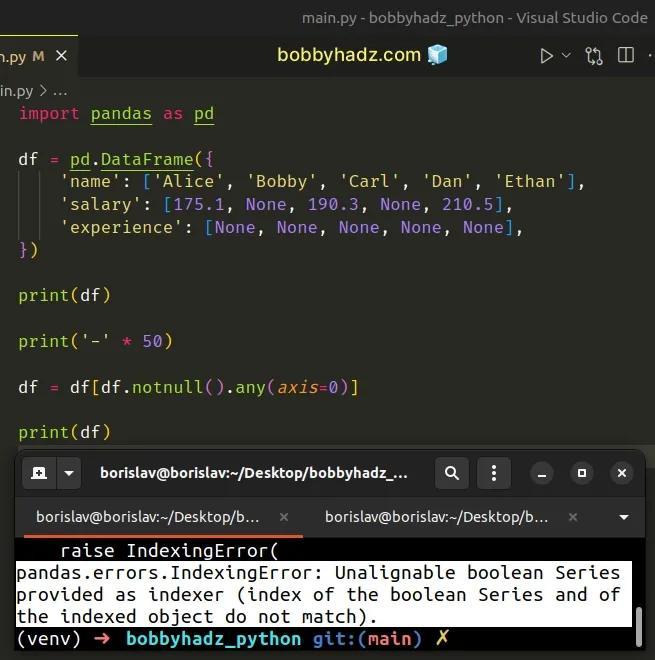
The code sample tries to remove the columns that have only NaN values from the
DataFrame.
However, the df[] syntax is used for a row-based index, not a column-based
index.
# Use the DataFrame.loc indexer when filtering by columns
To solve the error, use the DataFrame.loc indexer when filtering by columns.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df) print('-' * 50) df = df.loc[:, df.notnull().any(axis=0)] print(df)
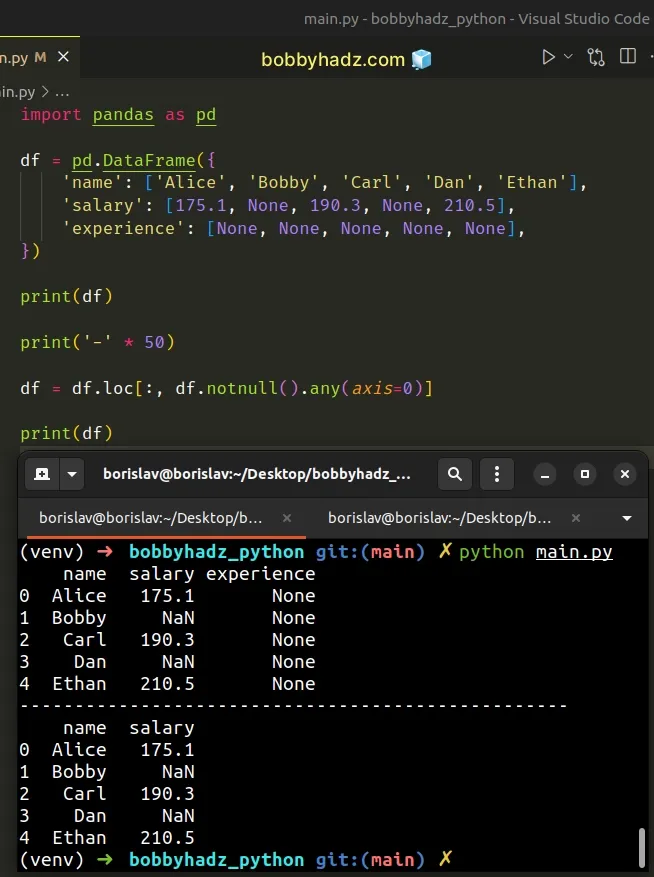
The DataFrame.loc indexer is used to access a group of rows and columns by
label(s) or a boolean array.
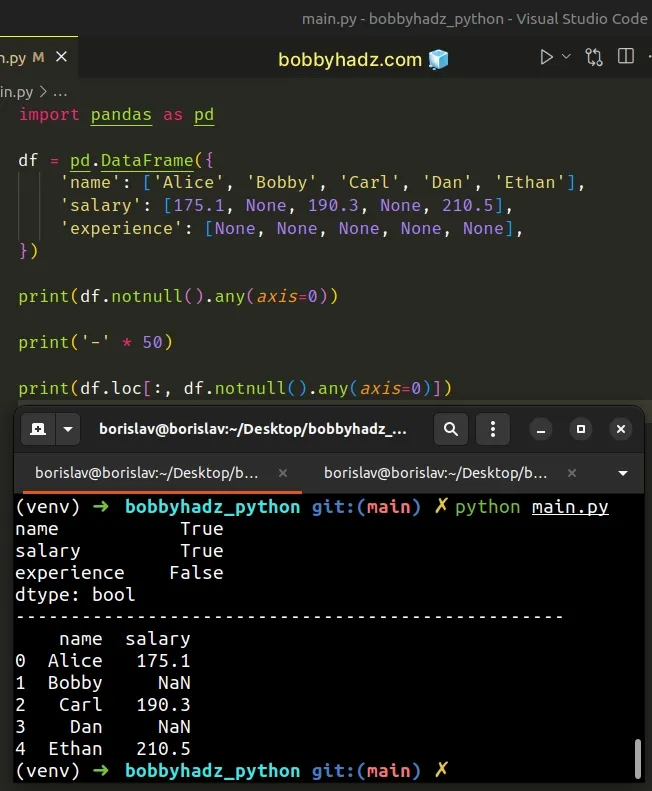
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df.notnull().any(axis=0)) print('-' * 50) print(df.loc[:, df.notnull().any(axis=0)])
Running the code sample produces the following output.
name True salary True experience False dtype: bool -------------------------------------------------- name salary 0 Alice 175.1 1 Bobby NaN 2 Carl 190.3 3 Dan NaN 4 Ethan 210.5
# Filtering the columns first before using bracket notation
Alternatively, you can solve the error by filtering by columns first and then using bracket notation.
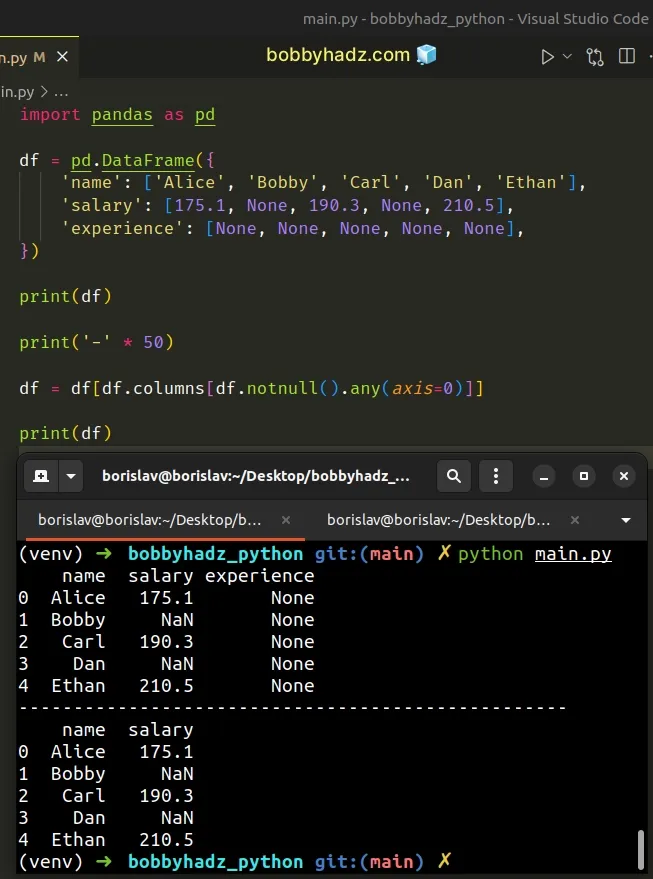
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df) print('-' * 50) df = df[df.columns[df.notnull().any(axis=0)]] print(df)
Running the code sample produces the following output.
name salary experience 0 Alice 175.1 None 1 Bobby NaN None 2 Carl 190.3 None 3 Dan NaN None 4 Ethan 210.5 None -------------------------------------------------- name salary 0 Alice 175.1 1 Bobby NaN 2 Carl 190.3 3 Dan NaN 4 Ethan 210.5
The
DataFrame.columns
property returns an Index object that contains the column names.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df.columns) print('-' * 50) print(df.columns[df.notnull().any(axis=0)])
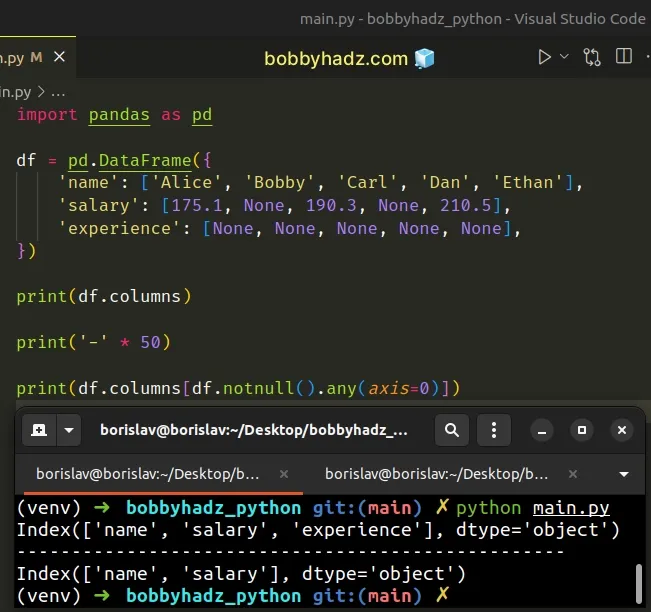
# Solving the error with the DataFrame.dropna() method
You can also solve the error by setting the how parameter to "all" when
calling
DataFrame.dropna().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df) print('-' * 50) df = df.dropna(how='all', axis=1) print(df)
Running the code sample produces the following output.
name salary experience 0 Alice 175.1 None 1 Bobby NaN None 2 Carl 190.3 None 3 Dan NaN None 4 Ethan 210.5 None -------------------------------------------------- name salary 0 Alice 175.1 1 Bobby NaN 2 Carl 190.3 3 Dan NaN 4 Ethan 210.5
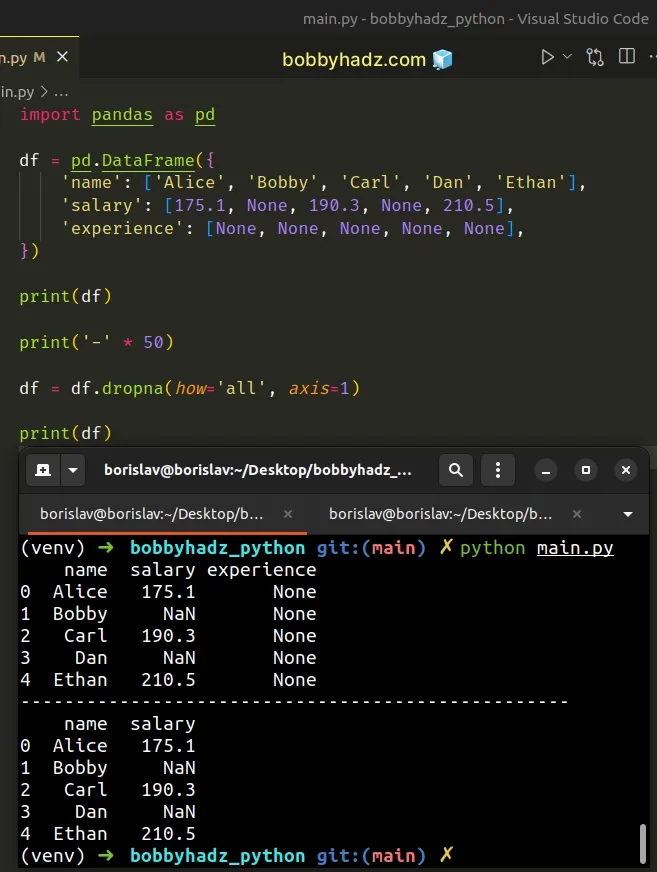
The DataFrame.dropna() method removes the missing values from the DataFrame.
df = df.dropna(how='all', axis=1)
We set the axis parameter to 1 so the method drops the columns that contain
a missing value.
When the how parameter is set to "all", then all values have to be NA for
the method to drop the column.
You can achieve the same result by setting the thresh argument to 1.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df) print('-' * 50) df = df.dropna(thresh=1, axis=1) print(df)
Running the code sample produces the following output.
name salary experience 0 Alice 175.1 None 1 Bobby NaN None 2 Carl 190.3 None 3 Dan NaN None 4 Ethan 210.5 None -------------------------------------------------- name salary 0 Alice 175.1 1 Bobby NaN 2 Carl 190.3 3 Dan NaN 4 Ethan 210.5
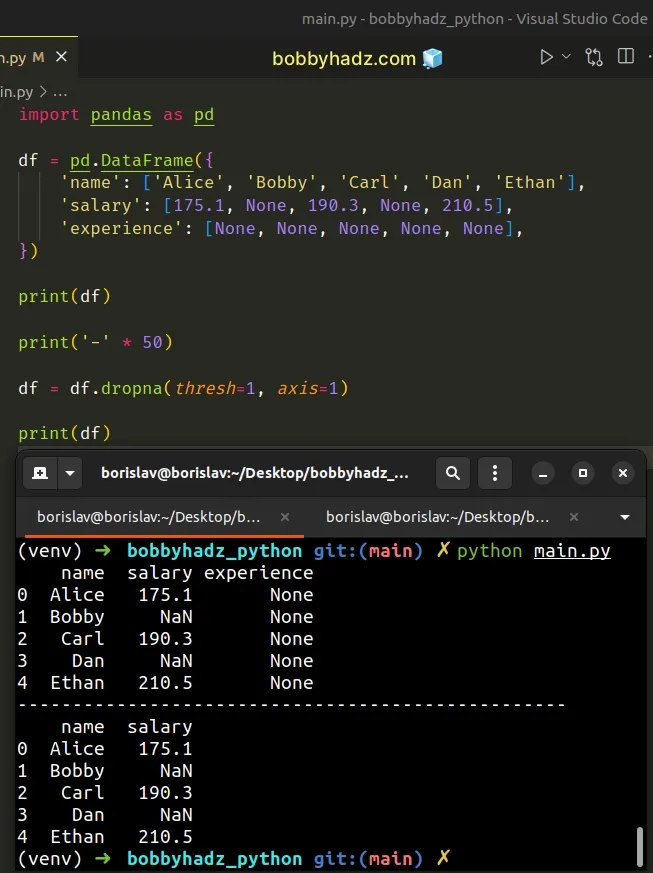
When the thresh argument is set to 1, the method drops all columns that
don't have at least 1 non-NA value.
df = df.dropna(thresh=1, axis=1)
In other words, all columns with all NA values are dropped.
# Forgetting to use the .str attribute
You might also get the error when you forget to use the str attribute.
For example, the following code sample causes the error.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df) print('-' * 50) new_df = df[(df['name'][0:2] != 'Bo')] print(new_df)
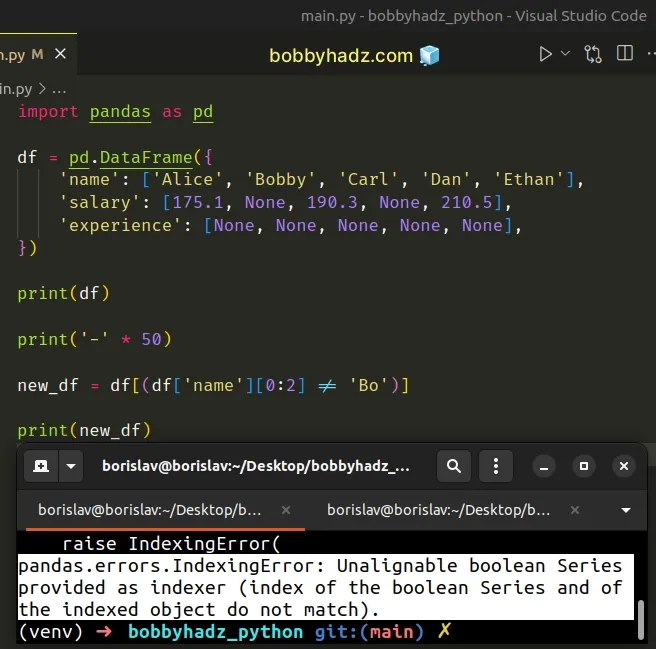
The code sample attempts to filter out the strings in the name column that
start with "Bo".
To solve the error, use the .str attribute after selecting the values in the
"name" column.
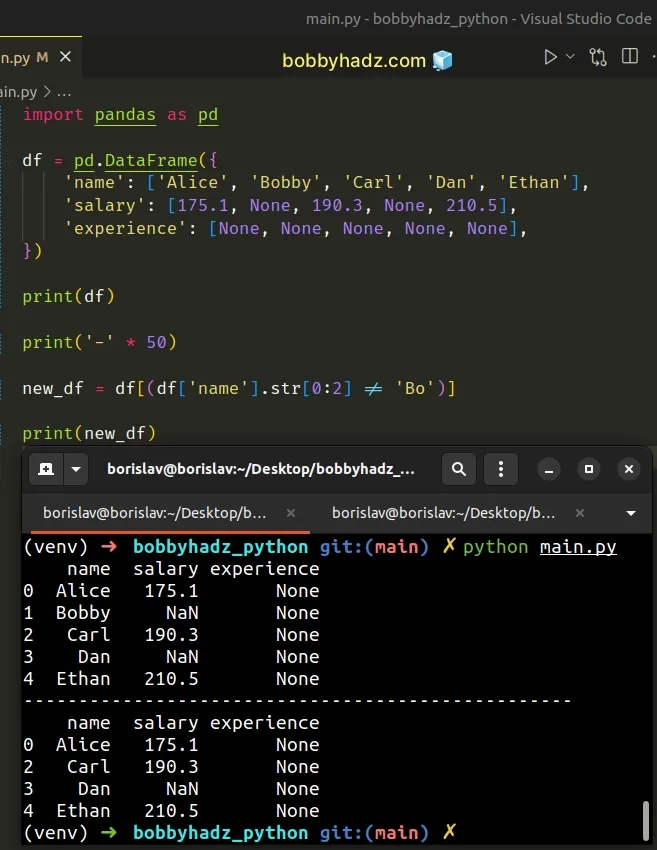
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, None, 190.3, None, 210.5], 'experience': [None, None, None, None, None], }) print(df) print('-' * 50) new_df = df[(df['name'].str[0:2] != 'Bo')] print(new_df)
Running the code sample produces the following output.
name salary experience 0 Alice 175.1 None 1 Bobby NaN None 2 Carl 190.3 None 3 Dan NaN None 4 Ethan 210.5 None -------------------------------------------------- name salary experience 0 Alice 175.1 None 2 Carl 190.3 None 3 Dan NaN None 4 Ethan 210.5 None
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: Element-wise logical NOT and logical OR operators
- Update a Pandas DataFrame while iterating over its rows
- Matplotlib: No artists with labels found to put in legend
- ValueError: If using all scalar values, you must pass index
- Pandas: How to Convert a Pivot Table to a DataFrame
- Pandas: Count the unique combinations of two Columns
- Python: Compare two CSV files and print the differences
- Pandas: Unalignable boolean Series provided as indexer

