Pandas: Make new Column from string Slice of another Column
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- Pandas: Make new Column from string Slice of another Column
- Create a new Column from string Slice of another Column using apply()
- Create a Column from string Slice of another Column using find()
# Pandas: Make new Column from string Slice of another Column
To create a new column from a string slice of another column:
- Use the
strattribute to get the string values of the given column. - Use bracket notation to slice each string.
- Assign the sliced strings to the
DataFrameusing bracket notation.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], 'salary': [175.1, 180.2, 190.3, 205.4], }) print(df) df['initials'] = df['name'].str[:1] print('-' * 50) print(df)
Running the code sample produces the following output.
name age salary 0 Alice 29 175.1 1 Bobby 30 180.2 2 Carl 31 190.3 3 Dan 32 205.4 -------------------------------------------------- name age salary initials 0 Alice 29 175.1 A 1 Bobby 30 180.2 B 2 Carl 31 190.3 C 3 Dan 32 205.4 D
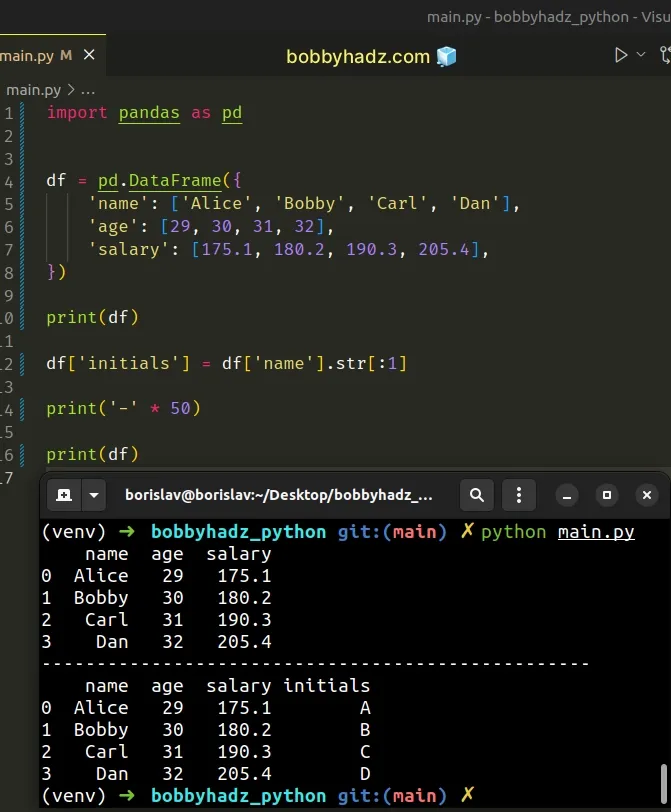
We used bracket notation [] to access the name column of the DataFrame.
df['initials'] = df['name'].str[:1]
You can then access the str attribute on the column to get the string values.
The syntax for string slicing
is my_str[start:stop:step].
start index is inclusive, whereas the stop index is exclusive (up to, but not including).Python indexes are zero-based, so the first character in a string has an index
of 0, and the last character has an index of -1 or len(my_str) - 1.
We used a stop index of 1 to only include the first character of each string
in the new column.
Here is an example that takes the first two letters.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], 'salary': [175.1, 180.2, 190.3, 205.4], }) print(df) df['initials'] = df['name'].str[:2] print('-' * 50) print(df)
The code sample produces the following output.
name age salary 0 Alice 29 175.1 1 Bobby 30 180.2 2 Carl 31 190.3 3 Dan 32 205.4 -------------------------------------------------- name age salary initials 0 Alice 29 175.1 Al 1 Bobby 30 180.2 Bo 2 Carl 31 190.3 Ca 3 Dan 32 205.4 Da
The slice starts at index 0 and goes up to but not including index 2.
df['initials'] = df['name'].str[:2]
You can also use the str.slice() method when slicing the row values.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], 'salary': [175.1, 180.2, 190.3, 205.4], }) print(df) df['initials'] = df['name'].str.slice(0, 1) print('-' * 50) print(df)
The
DataFrame.str.slice()
method slices substrings from each row of the DataFrame.
The first argument the method takes is the start index (inclusive).
The second argument the method takes is the stop index (exclusive).
# Create a new Column from string Slice of another Column using apply()
You can also use the DataFrame.apply() method to create a new column from a string slicing of another column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'age': [29, 30, 31, 32], 'salary': [175.1, 180.2, 190.3, 205.4], }) print(df) df['initials'] = df['name'].apply(lambda x: x[:1]) print('-' * 50) print(df)
Running the code sample produces the following output.
name age salary 0 Alice 29 175.1 1 Bobby 30 180.2 2 Carl 31 190.3 3 Dan 32 205.4 -------------------------------------------------- name age salary initials 0 Alice 29 175.1 A 1 Bobby 30 180.2 B 2 Carl 31 190.3 C 3 Dan 32 205.4 D
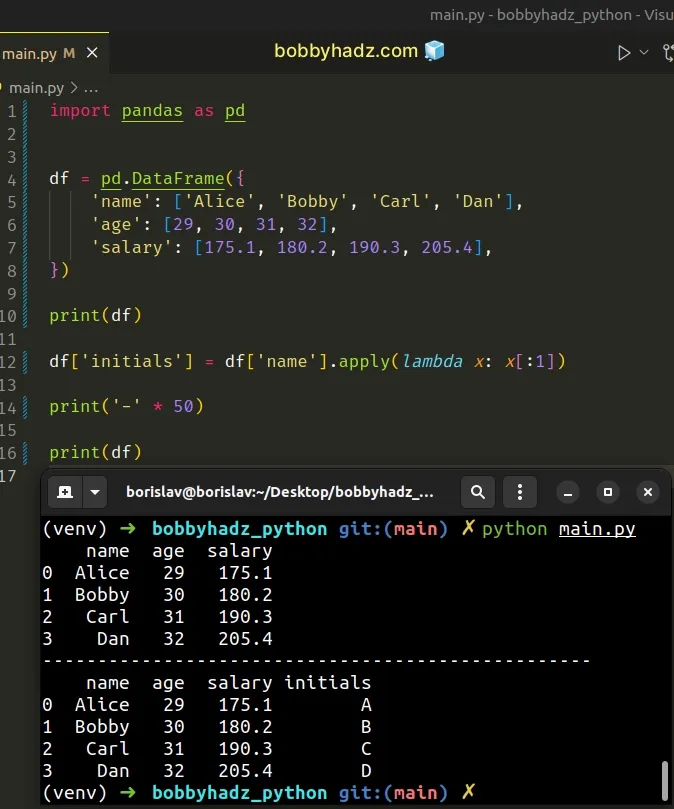
The DataFrame.apply() method applies a function along an axis of the
DataFrame.
The lambda function we passed to the method gets called with the value of each row, accesses the first character and returns the result.
df['initials'] = df['name'].apply(lambda x: x[:1])
# Create a Column from string Slice of another Column using find()
In some cases, you might not know the slice indices in advance.
You can use the str.find() method to get the index of a common character that is then used when slicing.
import pandas as pd df = pd.DataFrame({ 'email': ['Alice@example.com', 'Bobby@example.com', 'Carl@example.com'], 'age': [29, 30, 31], 'salary': [175.1, 180.2, 190.3], }) print(df) df['stop_index'] = df['email'].str.find('@') df['name'] = df.apply(lambda x: x['email'][:x['stop_index']], axis=1) print('-' * 50) print(df)
Running the code sample produces the following output.
email age salary 0 Alice@example.com 29 175.1 1 Bobby@example.com 30 180.2 2 Carl@example.com 31 190.3 -------------------------------------------------- email age salary stop_index name 0 Alice@example.com 29 175.1 5 Alice 1 Bobby@example.com 30 180.2 5 Bobby 2 Carl@example.com 31 190.3 4 Carl
We used the find() method to get the index of each @ symbol in the email
column.
df['stop_index'] = df['email'].str.find('@')
The next step is to use the apply() method to slice the email column with
the results used as stop indices.
df['name'] = df.apply(lambda x: x['email'][:x['stop_index']], axis=1)
The axis argument determines the axis along which the supplied function is
applied.
When the axis argument is set to 1, the function is applied to each row.
By default, the axis argument is set to 0, which means that the function is
applied to each column.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- How to Remove the trailing Zeros from a Decimal in Python
- Round a Float to 1, 2 or 3 Decimal places in Python
- Split a Float into Integer and Decimal parts in Python
- Format number with comma as thousands separator in Python
- SyntaxError: invalid decimal literal in Python [Solved]
- SyntaxError: leading zeros in decimal integer literals are not permitted

