Cannot mask with non-boolean array containing NA / NaN values
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Cannot mask with non-boolean array containing NA / NaN values
- Set the na argument to False when calling str.contains
- Solving the error by only producing boolean results with equality comparison
- The error also occurs if your column contains non-String values
- Using the DataFrame.fillna() method to solve the error
- Using the DataFrame.dropna() method to solve the error
# Cannot mask with non-boolean array containing NA / NaN values
The Pandas "ValueError: Cannot mask with non-boolean array containing NA / NaN
values" occurs when you use the str.contains method on a column that contains
NA/NaN values or contains non-string values.
To solve the error, set the na argument to False when calling
str.contains.
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) result = df[df['first_name'].str.contains('Bob')] # ⛔️ ValueError: Cannot mask with non-boolean array containing NA / NaN values print(result)
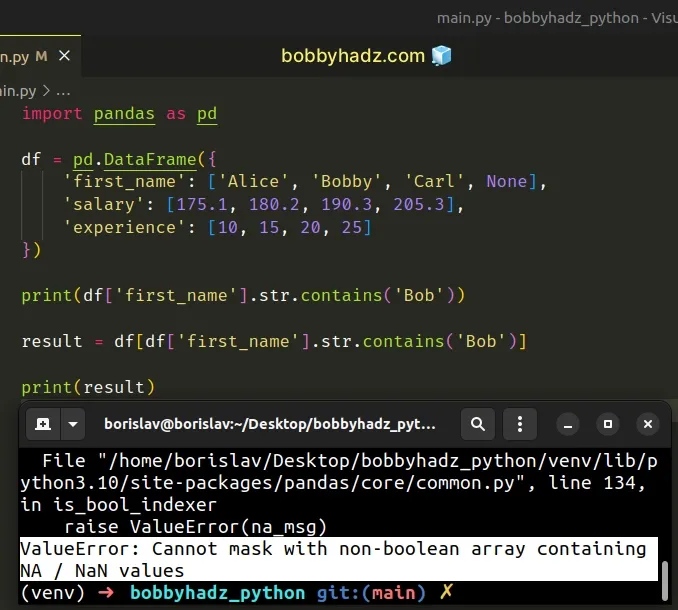
Notice that the first_name column contains a None value.
If you print the output of calling
Series.str.contains(),
you will see a None value.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) # 0 False # 1 True # 2 False # 3 None # Name: first_name, dtype: object print(df['first_name'].str.contains('Bob'))
This is why Pandas won't allow us to mask with a non-boolean array (one containing NA / NaN values).
# Set the na argument to False when calling str.contains
One way to solve the error is to set the na argument to False when calling
the Series.str.contains() method.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) result = df[df['first_name'].str.contains('Bob', na=False)] # first_name salary experience # 1 Bobby 180.2 15 print(result)
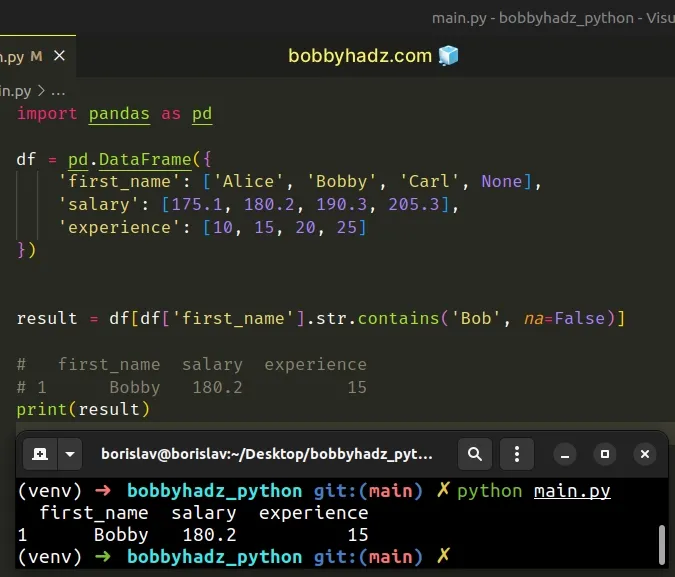
The Series.str.contains() method tests if a pattern or a regex is contained
within a string of a Series or Index.
numpy.nan and string-dtype values with pandas.NA.We set the na argument to False to not have missing values in the produced
boolean Series.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) # 0 False # 1 True # 2 False # 3 False # Name: first_name, dtype: bool print(df['first_name'].str.contains('Bob', na=False))
Now all elements in the Series are booleans, so we can safely use it to filter
the DataFrame.
We could've also used the DataFrame.loc label indexer to achieve the same result.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) result = df.loc[df['first_name'].str.contains('Bob', na=False)] # first_name salary experience # 1 Bobby 180.2 15 print(result)
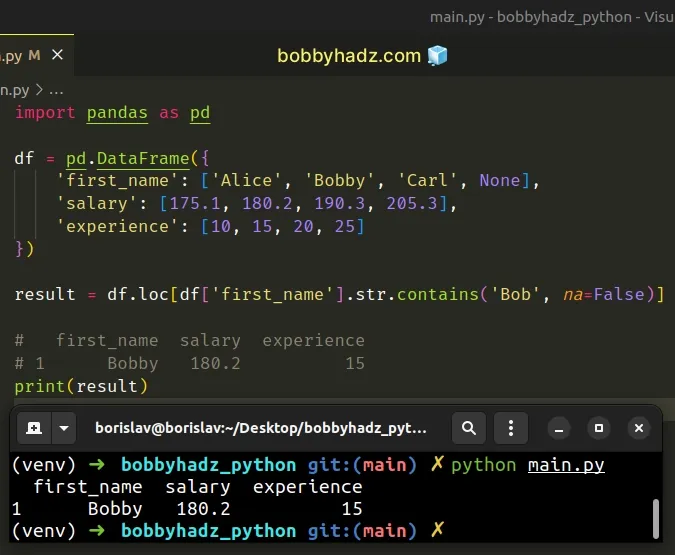
Make sure to set the na argument to False when calling
Series.str.contains().
This probably should've been the default value for the na argument, however,
it is not.
# Solving the error by only producing boolean results with equality comparison
You can also use the equality operator to solve the error.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) result = df[df['first_name'].str.contains('Bob') == True] # first_name salary experience # 1 Bobby 180.2 15 print(result)
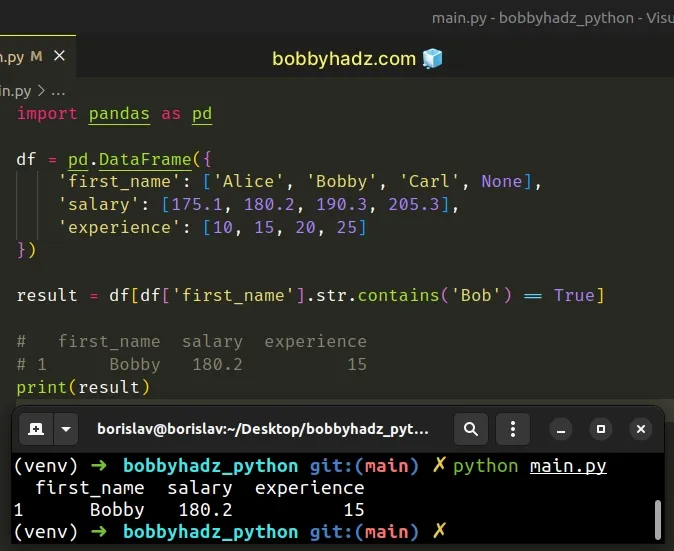
By comparing the results of calling the Series.str.contains() method to the
True boolean value, we only get boolean results.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) # 0 False # 1 True # 2 False # 3 False # Name: first_name, dtype: bool print(df['first_name'].str.contains('Bob') == True)
The equality comparison only returns True for True values.
If the value is False, NA or NaN, then False is returned, so the Series
only contains booleans.
# The error also occurs if your column contains non-String values
The error also occurs if the column on which you used Series.str.contains()
has non-string values or contains values of multiple types.
Here is an example.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', 1000], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) # ⛔️ ValueError: Cannot mask with non-boolean array containing NA / NaN values result = df[df['first_name'].str.contains('Bob')]
Notice that the first_name column has string and integer values.
You can use the
DataFrame.astype()
method to convert the column values to strings before calling str.contains()
to solve the error.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', 1000], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) result = df[df['first_name'].astype(str).str.contains('Bob')] # first_name salary experience # 1 Bobby 180.2 15 print(result)
Alternatively, you can simply convert the values in the column to strings.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', 1000], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) df['first_name'] = df['first_name'].astype(str) result = df[df['first_name'].str.contains('Bob')] # first_name salary experience # 1 Bobby 180.2 15 print(result)
Once all values in the column are strings (and it doesn't contain any NA/NaN values), the error will be resolved.
# Using the DataFrame.fillna() method to solve the error
You can also use the DataFrame.fillna() method to solve the error.
The method fills the NA/NaN values in the DataFrame.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) result = df[df['first_name'].str.contains('Bob').fillna(False)] # first_name salary experience # 1 Bobby 180.2 15 print(result)
We used the method to fill na NA/NaN values with False values.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) # 0 False # 1 True # 2 False # 3 False # Name: first_name, dtype: bool print(df['first_name'].str.contains('Bob').fillna(False))
The returned boolean Series no longer contains any NA/NaN values, so we can
safely filter the DataFrame.
# Using the DataFrame.dropna() method to solve the error
You can also use the DataFrame.dropna() method to solve the error.
The method removes any missing values from the DataFrame.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl', None], 'salary': [175.1, 180.2, 190.3, 205.3], 'experience': [10, 15, 20, 25] }) df.dropna(inplace=True) # first_name salary experience # 0 Alice 175.1 10 # 1 Bobby 180.2 15 # 2 Carl 190.3 20 print(df) print('-' * 50) result = df[df['first_name'].str.contains('Bob')] # first_name salary experience # 1 Bobby 180.2 15 print(result)
Make sure to only use this approach if you want to remove all rows that contain
missing values from the DataFrame.
As shown in the code sample, the DataFrame only contains 3 rows after calling
DataFrame.dropna().
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

