Usecols do not match columns, columns expected but not found
Last updated: Apr 11, 2024
Reading time·4 min

# Table of Contents
- Usecols do not match columns, columns expected but not found
- Make sure the sep argument is specified correctly
# Usecols do not match columns, columns expected but not found
The Pandas "ValueError: Usecols do not match columns, columns expected but not found" occurs for 2 main reasons:
- Misspelling the names of the columns you want to get from the CSV file.
- Forgetting to specify the
separgument or setting it to an incorrect value.
Let's look at an example of how the error occurs.
Suppose we have the following employees.csv file.
first_name,last_name,date Alice,Smith,2023-01-05 Bobby,Hadz,2023-03-25 Carl,Lemon,2021-01-24
And here is the related main.py file.
import pandas as pd # ⛔️ ValueError: Usecols do not match columns, columns expected but not found: ['last', 'first'] df = pd.read_csv( 'employees.csv', sep=',', encoding='utf-8', usecols=['first', 'last'] ) print(df)
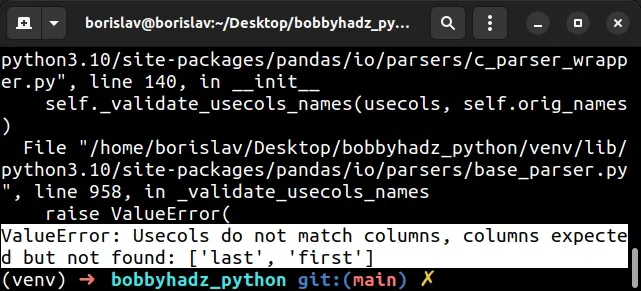
The pandas.read_csv
method reads a comma-separated values (CSV) file into a DataFrame object.
The usecols argument is used to return a subset of the columns when reading
the CSV file.
The CSV file in the example has 3 columns:
first_namelast_namedate
usecols argument to an array containing the strings "first" and "last".These values are not among the available column names which caused the issue.
To solve the error in this case, make sure to specify column names that are contained in the CSV file.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=',', encoding='utf-8', usecols=['first_name', 'date'] ) # first_name date # 0 Alice 2023-01-05 # 1 Bobby 2023-03-25 # 2 Carl 2021-01-24 print(df)
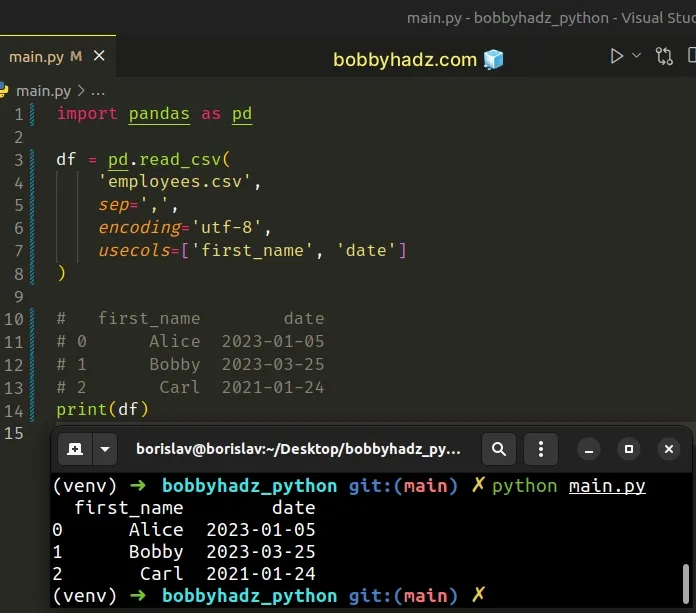
As long as the specified column names exist in the CSV file, everything works as expected.
# Make sure the sep argument is specified correctly
Another common reason the error occurs is when you forget to specify the sep
argument when calling pandas.read_csv or set it to an incorrect value.
Suppose we have the following employees.csv file.
first_name,last_name,date Alice,Smith,2023-01-05 Bobby,Hadz,2023-03-25 Carl,Lemon,2021-01-24
The values in the CSV file are separated by a comma ,.
If you specify a different separator, the error is raised.
import pandas as pd # ⛔️ ValueError: Usecols do not match columns, columns expected but not found: ['date', 'first_name'] df = pd.read_csv( 'employees.csv', sep=';', encoding='utf-8', usecols=['first_name', 'date'] ) print(df)
We used a semicolon ; as the separator, so the pandas.read_csv method
couldn't split the column names correctly which caused the error.
You have to make sure to set the sep argument to the correct delimiter
character.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=',', encoding='utf-8', usecols=['first_name', 'date'] ) # first_name date # 0 Alice 2023-01-05 # 1 Bobby 2023-03-25 # 2 Carl 2021-01-24 print(df)
The values in the CSV file are separated by a comma, so we set the sep
argument to a comma ,.
sep argument specifies the delimiter that should be used and is set to a comma , by default.The character has to reflect the separator that is used in your CSV file.
For example, the following employees.csv file uses a semicolon ; as the
separator.
first_name;last_name;date Alice;Smith;2023-01-05 Bobby;Hadz;2023-03-25 Carl;Lemon;2021-01-24
Therefore the sep argument has to be set to a string containing a semicolon
; character.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=';', encoding='utf-8', usecols=['first_name', 'date'] ) # first_name date # 0 Alice 2023-01-05 # 1 Bobby 2023-03-25 # 2 Carl 2021-01-24 print(df)
You may only omit the sep argument if the values in your CSV file are
separated by a comma.
If you specify a wrong delimiter, the ValueError is raised because the
read_csv() method is not able to split the columns correctly.
I've also written a detailed guide on how to read specific columns from an Excel File in Pandas.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- TypeError: ufunc 'isnan' not supported for the input types
- ValueError: columns overlap but no suffix specified [Solved]
- Columns have mixed types. Specify dtype option on import
- Convert a Row to a Column Header in a Pandas DataFrame
- Drop Unnamed: 0 columns from a Pandas DataFrame in Python
- IndexError: single positional indexer is out-of-bounds [Fix]
- AttributeError: Can only use .dt accessor with datetimelike values
- Count number of non-NaN values in each column of DataFrame
- Add a column with incremental Numbers to a Pandas DataFrame
- Using pandas.read_csv() with multiple delimiters in Python
- Pandas: Create new row for each element in List in DataFrame
- ValueError: Cannot merge a Series without a name [Solved]
- Index(...) must be called with a collection of some kind
- ValueError: Shape of passed values is X, indices imply Y
- Pandas: Select distinct across multiple DataFrame columns

