Cannot convert non-finite values (NA or inf) to integer
Last updated: Apr 13, 2024
Reading time·5 min

# Table of Contents
- Cannot convert non-finite values (NA or inf) to integer
- Use the DataFrame.fillna() method to solve the error
- Only calling fillna() on the specific column
- Setting the errors argument to ignore when calling astype()
- Using the Nullable integer data type to solve the error
- Using the pandas.to_numeric() method to solve the error
# Cannot convert non-finite values (NA or inf) to integer
The Pandas error "Cannot convert non-finite values (NA or inf) to integer" occurs when you try to convert the values in a column with missing or non-finite values to integers.
Use the DataFrame.fillna() method to fill the missing values in the
DataFrame column before converting them to integers to solve the error.
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.0, 2022.0, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].astype(int) # ⛔️ pandas.errors.IntCastingNaNError: Cannot convert non-finite values (NA or inf) to integer print(df)
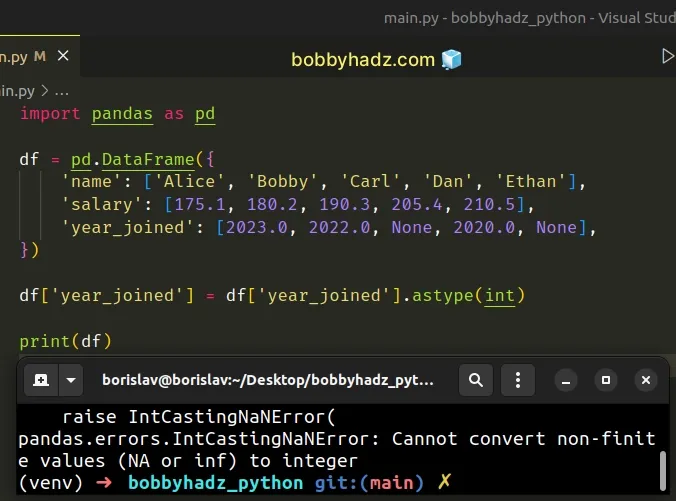
Notice that the year_joined column contains missing values (e.g. None,
NaN, etc).
Trying to convert missing values to integers with DataFrame.astype causes the error.
# Use the DataFrame.fillna() method to solve the error
One way to solve the error is to use the DataFrame.fillna() method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.0, 2022.0, None, 2020.0, None], }) df = df.fillna(value=0) df['year_joined'] = df['year_joined'].astype(int) # name salary year_joined # 0 Alice 175.1 2023 # 1 Bobby 180.2 2022 # 2 Carl 190.3 0 # 3 Dan 205.4 2020 # 4 Ethan 210.5 0 print(df)
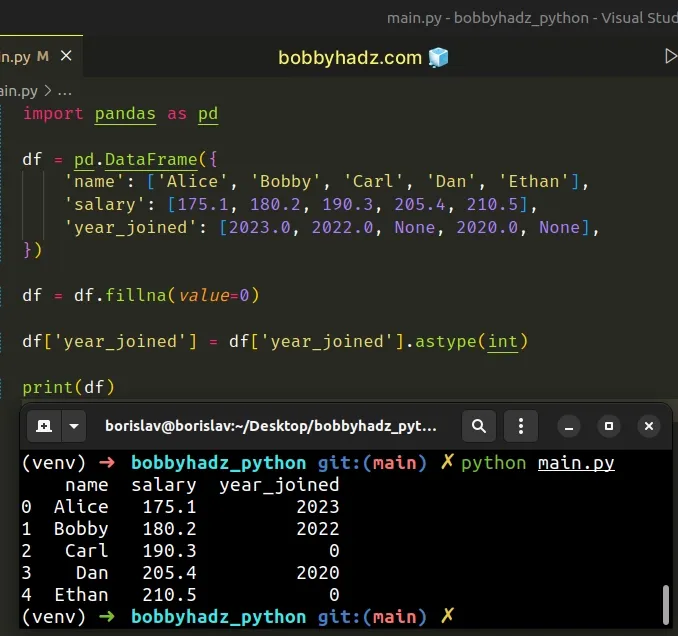
The DataFrame.fillna() method fills the NA/NaN values in the DataFrame.
df = df.fillna(value=0)
The only argument we passed to the method is the replacement value (the value that is used to fill the holes).
I used 0 in the example but you can use any other value.
# Only calling fillna() on the specific column
You can also only call the fillna() method on the specific DataFrame column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.0, 2022.0, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].fillna(value=0) df['year_joined'] = df['year_joined'].astype(int) # name salary year_joined # 0 Alice 175.1 2023 # 1 Bobby 180.2 2022 # 2 Carl 190.3 0 # 3 Dan 205.4 2020 # 4 Ethan 210.5 0 print(df)
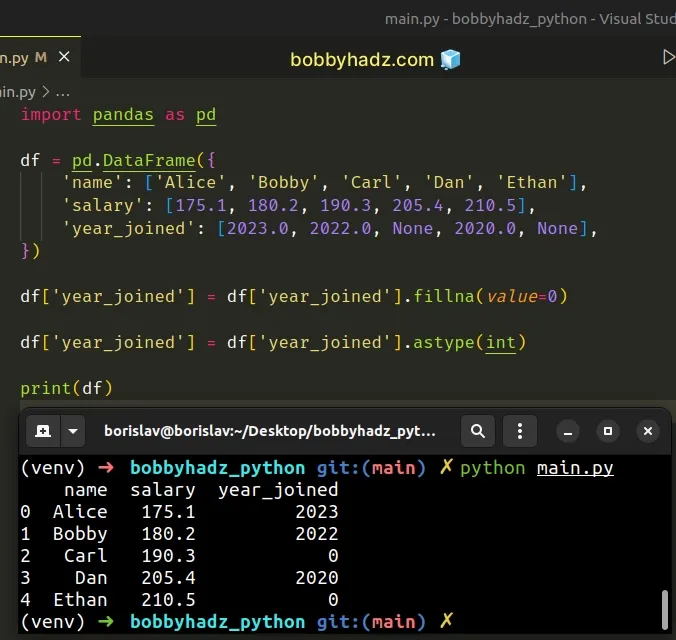
We used bracket notation to select the year_joined column and called the
fillna() method on the specific column.
# Setting the errors argument to ignore when calling astype()
If you'd rather keep the missing values, set the errors argument to ignore
in the call to astype().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.0, 2022.0, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].astype( int, errors='ignore' ) # name salary year_joined # 0 Alice 175.1 2023.0 # 1 Bobby 180.2 2022.0 # 2 Carl 190.3 NaN # 3 Dan 205.4 2020.0 # 4 Ethan 210.5 NaN print(df)
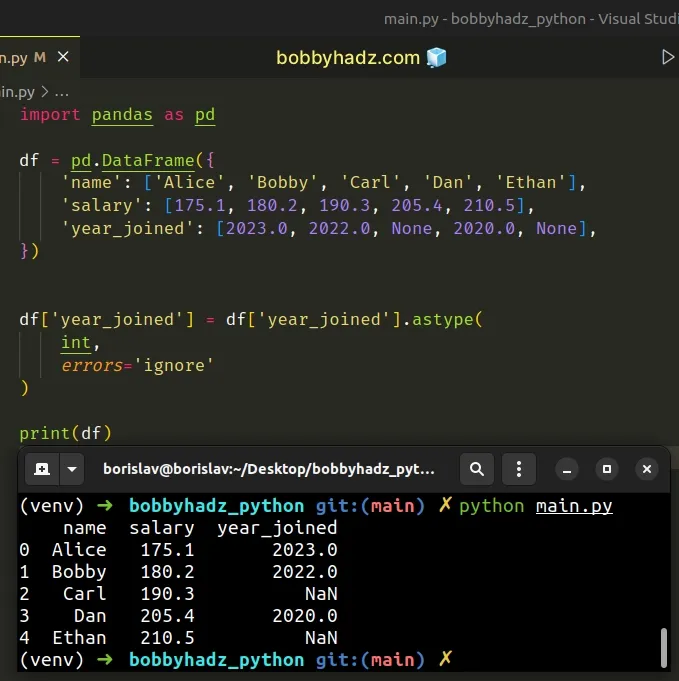
The DataFrame.astype() method takes an optional errors argument.
By default, the argument is set to "raise" which means that exceptions that
occur are raised.
However, you can also set the errors argument to "ignore" to suppress
exceptions.
df['year_joined'] = df['year_joined'].astype( int, errors='ignore' ) # name salary year_joined # 0 Alice 175.1 2023.0 # 1 Bobby 180.2 2022.0 # 2 Carl 190.3 NaN # 3 Dan 205.4 2020.0 # 4 Ethan 210.5 NaN print(df)
When an error occurs, the original object is returned.
However, notice that when using this approach, the not-NaN values don't get converted to integers.
# Using the Nullable integer data type to solve the error
You can also use the nullable integer data type to solve the error.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.0, 2022.0, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].astype('Int64') # name salary year_joined # 0 Alice 175.1 2023 # 1 Bobby 180.2 2022 # 2 Carl 190.3 <NA> # 3 Dan 205.4 2020 # 4 Ethan 210.5 <NA> print(df)
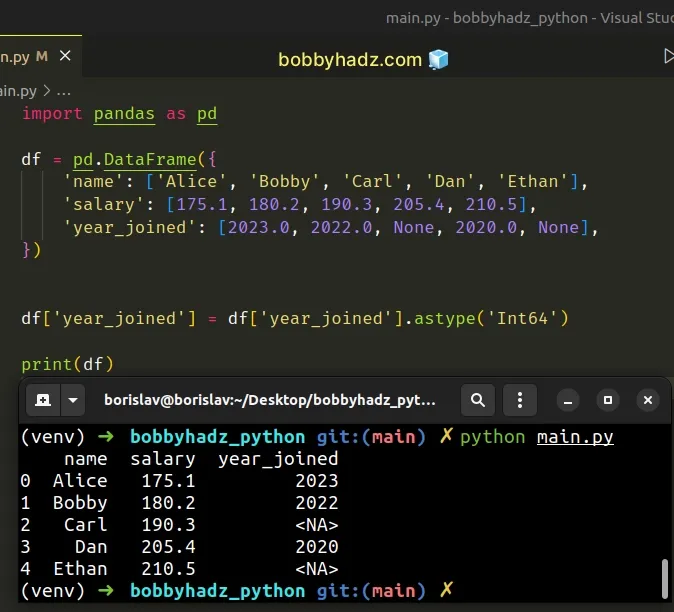
The "Int64" type is nullable, so we didn't get an error when astype()
encountered missing values.
I in "Int64". Not to be confused with the NumPy int64 type.The "Int64" type uses the pandas.NA value for the missing values (and not
numpy.nan).
If you want to round the values before calling the astype() method, use the
round() method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.5, 2022.4, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].round().astype('Int64') # name salary year_joined # 0 Alice 175.1 2024 # 1 Bobby 180.2 2022 # 2 Carl 190.3 <NA> # 3 Dan 205.4 2020 # 4 Ethan 210.5 <NA> print(df)
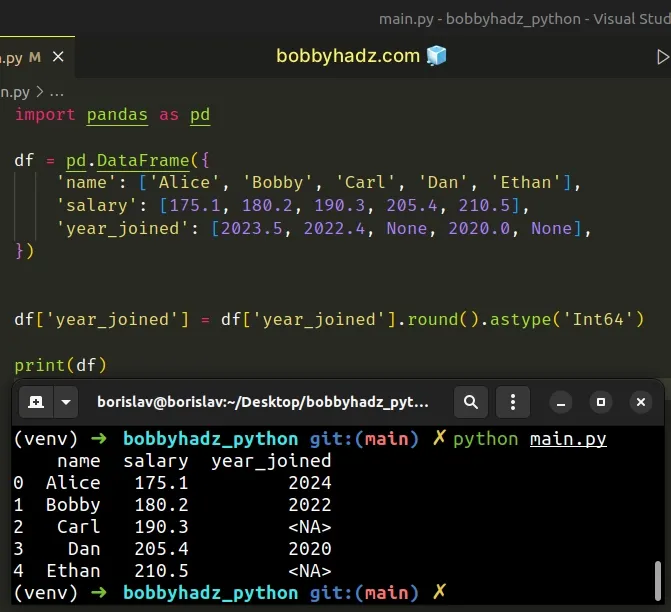
The round() method rounds the DataFrame to a variable number of decimal
places (0 by default).
If you want to round each float down or up, use the DataFrame.apply() method.
Here is an example that rounds down using numpy.floor().
import numpy as np import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.5, 2022.4, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].apply(np.floor).astype('Int64') # name salary year_joined # 0 Alice 175.1 2023 # 1 Bobby 180.2 2022 # 2 Carl 190.3 <NA> # 3 Dan 205.4 2020 # 4 Ethan 210.5 <NA> print(df)
Make sure you have the NumPy module installed.
pip install numpy # or with pip3 pip3 install numpy
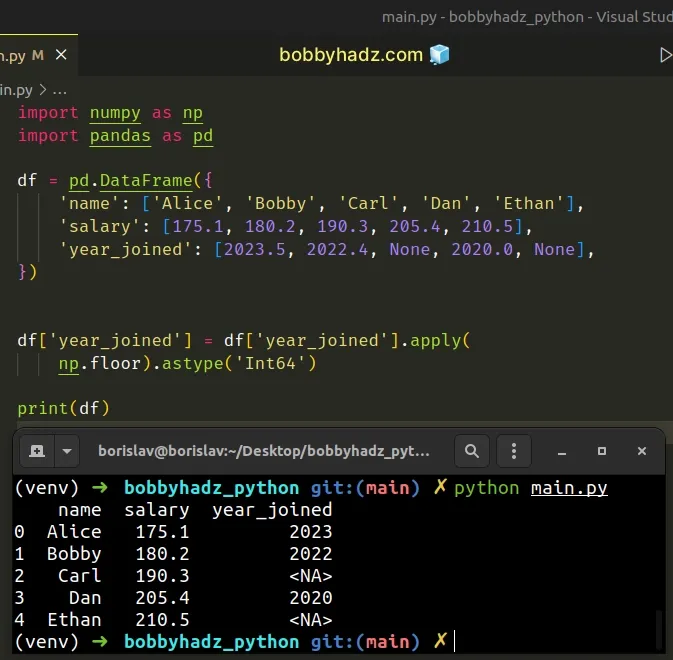
As the name suggests, the numpy.floor() method returns the floor of the supplied value, element-wise.
If you only want to round up, use the numpy.ceil() method.
import numpy as np import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.5, 2022.4, None, 2020.0, None], }) df['year_joined'] = df['year_joined'].apply( np.ceil).astype('Int64') # name salary year_joined # 0 Alice 175.1 2024 # 1 Bobby 180.2 2023 # 2 Carl 190.3 <NA> # 3 Dan 205.4 2020 # 4 Ethan 210.5 <NA> print(df)
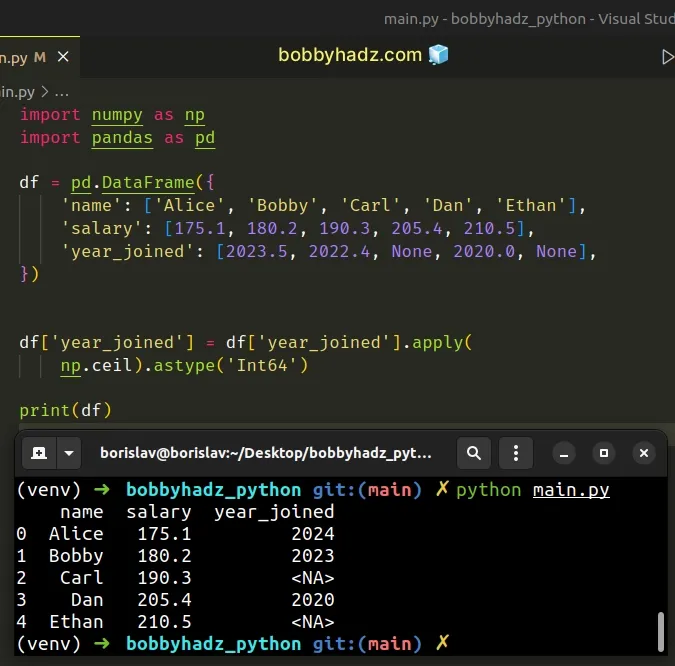
The numpy.ceil() method returns the ceiling of the supplied value,
element-wise.
# Using the pandas.to_numeric() method to solve the error
You can also use the pandas.to_numeric() method to solve the error.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], 'year_joined': [2023.0, 2022.0, None, 2020.0, None], }) df['year_joined'] = pd.to_numeric( df['year_joined'], errors='coerce' ).fillna(0) df['year_joined'] = df['year_joined'].astype(int) # name salary year_joined # 0 Alice 175.1 2023 # 1 Bobby 180.2 2022 # 2 Carl 190.3 0 # 3 Dan 205.4 2020 # 4 Ethan 210.5 0 print(df)
The pandas.to_numeric() method converts the supplied argument to a numeric
type.
df['year_joined'] = pd.to_numeric( df['year_joined'], errors='coerce' ).fillna(0)
By default, the returned dtype is float64 or int64 depending on the
supplied data.
We also set the errors argument to "coerce".
When the errors argument is set to "coerce", then values that cannot be
parsed are set to NaN.
We called the fillna() method on the result to replace the missing values with
zeros.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Disable the TOKENIZERS_PARALLELISM=(true | false) warning
- RuntimeError: Expected scalar type Float but found Double
- Pandas: Convert timezone-aware DateTimeIndex to naive timestamp
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type float)

