Disable the TOKENIZERS_PARALLELISM=(true | false) warning
Last updated: Apr 12, 2024
Reading time·3 min

# Table of Contents
- Disable the TOKENIZERS_PARALLELISM=(true | false) warning
- Disabling the TOKENIZERS_PARALLELISM environment variable in your shell
- Disabling the TOKENIZERS_PARALLELISM environment variable in your Python script
- If you need to keep the parallelism, don't use FastTokenizers
- Try setting the use_fast argument to False
# Disable the TOKENIZERS_PARALLELISM=(true | false) warning
This article addresses the "The current process just got forked. Disabling parallelism to avoid deadlocks... To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)" warning in PyTorch and transformers.
To disable the warning, set the TOKENIZERS_PARALLELISM environment variable to
false.
# Disabling the TOKENIZERS_PARALLELISM environment variable in your shell
One way to disable the TOKENIZERS_PARALLELISM environment variable is directly
in your shell.
This has to be done before you run your Python script.
Open your terminal in your project's root directory.
If you are on macOS or Linux, issue the following command to set the environment
variable to false.
# on macOS and Linux export TOKENIZERS_PARALLELISM=false
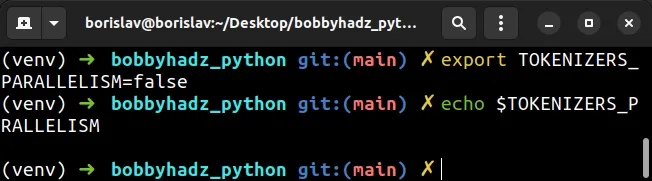
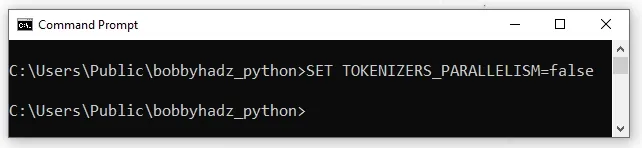
If you are on Windows and use CMD (Command Prompt), issue the following command instead.
# On Windows, CMD SET TOKENIZERS_PARALLELISM=false
If you are on Windows and use PowerShell, issue the following command instead.
# On Windows, PowerShell $env:TOKENIZERS_PARALLELISM=0

After you run the command and set the TOKENIZERS_PARALLELISM environment
variable to false (or 0), rerun your Python script and the warning won't be
shown.
TOKENIZERS_PARALLELISM environment variable to true, your training will freeze and no warning message will be shown.This is caused because the data loader fails and cannot fork the process due to a fear of deadlocks.
# Disabling the TOKENIZERS_PARALLELISM environment variable in your Python script
Alternatively, you can set the TOKENIZERS_PARALLELISM environment variable to
false directly in your Python script.
However, note that the environment variable has to be set to false before your
other import statements.
import os # ✅ Set TOKENIZERS_PARALLELISM to false os.environ["TOKENIZERS_PARALLELISM"] = "false" # ✅ The rest of your code below from transformers import pipeline from transformers import AutoTokenizer, AutoModelForSequenceClassification model_name = "nlptown/bert-base-multilingual-uncased-sentiment" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) pipe = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
The code sample uses the
os.environ mapping
object to set the TOKENIZERS_PARALLELISM environment variable to false.
Note that the line that sets the environment variable has to precede your
transformers import statements.
# If you need to keep the parallelism, don't use FastTokenizers
If you need to keep the parallelism in your code:
- Don't use
FastTokenizersas they do parallel processing in Rust. This causes a conflict when you fork a process via multiprocessing in Python. - Don't use the tokenizer before iterating through your data loader (before the fork). Instead, first fork the process.
Forking happens when you loop over the data loader in the train() method.
If you set the TOKENIZERS_PARALLELISM environment variable to False,
parallelism is disabled and deadlocks are avoided.
In other words, disabling the environment variable doesn't affect your use of parallel threads that leverage multiple GPU cores (e.g. the data loader function).
# Try setting the use_fast argument to False
If none of the suggestions helped, try setting the use_fast argument to
False in the call to AutoTokenizer.from_pretrained().
from transformers import AutoTokenizer, AutoModelForSequenceClassification from transformers import pipeline import os os.environ["TOKENIZERS_PARALLELISM"] = "false" model_name = "nlptown/bert-base-multilingual-uncased-sentiment" model = AutoModelForSequenceClassification.from_pretrained( model_name) # 👇️ Set the `use_false` argument to False tokenizer = AutoTokenizer.from_pretrained( model_name, use_fast=False ) pipe = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
The use_fast argument indicates if transformers should try to load the fast
version of the tokenizer (True) or use the Python one (False).
False, however, the warning is still shown in some cases.In many cases, explicitly setting use_fast to False resolves the issue.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

