Pandas: How to efficiently Read a Large CSV File [6 Ways]
Last updated: Apr 13, 2024
Reading time·5 min

# Table of Contents
- Pandas: How to efficiently Read a Large CSV File
- Using a nested for loop to read a large CSV file in Pandas
- Pandas: Reading a large CSV file by only loading in specific columns
- Pandas: Read a large CSV file by using the Dask package
- Only selecting the first N rows of the CSV file
- Pandas: Reading a large CSV file with the Modin module
# Pandas: How to efficiently Read a Large CSV File
To efficiently read a large CSV file in Pandas:
- Use the
pandas.read_csv()method to read the file. - Set the
chunksizeargument to the number of rows each chunk should contain. - Iterate over the rows of each chunk.
MemoryError exception.Instead, you should process the file in chunks.
Suppose we have the following example.csv file.
1Bobby,Hadz,Com 2Bobby,Hadz,Com 3Bobby,Hadz,Com 4Bobby,Hadz,Com 5Bobby,Hadz,Com 6Bobby,Hadz,Com 7Bobby,Hadz,Com 8Bobby,Hadz,Com 9Bobby,Hadz,Com 10Bobby,Hadz,Com 11Bobby,Hadz,Com 12Bobby,Hadz,Com 13Bobby,Hadz,Com 14Bobby,Hadz,Com 15Bobby,Hadz,Com 16Bobby,Hadz,Com 17Bobby,Hadz,Com 18Bobby,Hadz,Com 19Bobby,Hadz,Com 20Bobby,Hadz,Com
Here is the related Python script.
import pandas as pd file_name = 'example.csv' rows_per_chunk = 5 with pd.read_csv( file_name, chunksize=rows_per_chunk ) as csv_reader: for chunk in csv_reader: print(chunk) print('-' * 50)
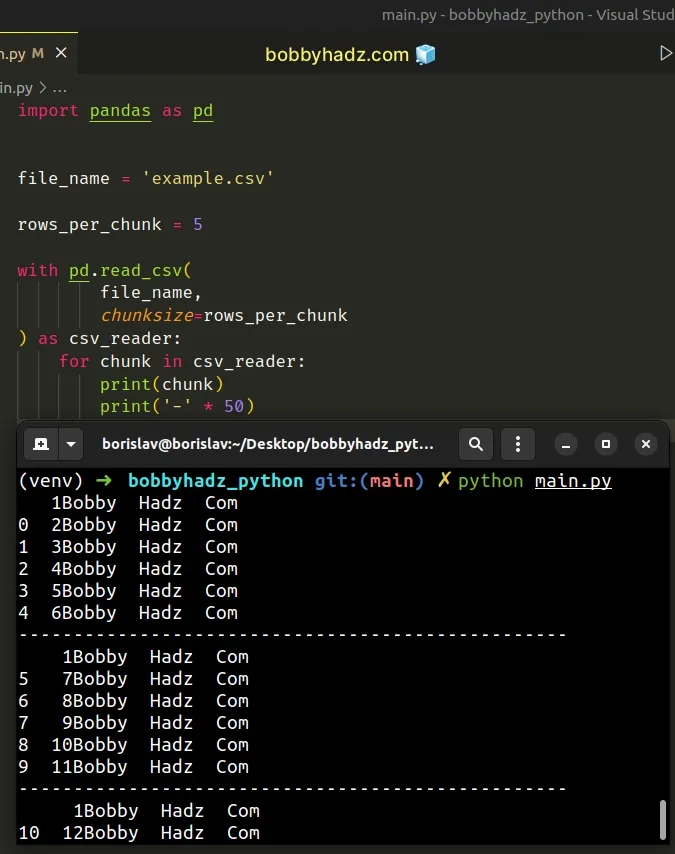
The pandas.read_csv()
method reads a comma-separated values (CSV) file into a DataFrame.
The first argument we passed to the method is the path to the .csv file.
example.csv file in the same directory as your Python script.The chunksize argument is an integer value that determines the number of rows
each chunk should consist of.
# Using a nested for loop to read a large CSV file in Pandas
You can also use a nested for loop to achieve the same result.
import pandas as pd file_name = 'example.csv' rows_per_chunk = 5 for chunk in pd.read_csv(file_name, chunksize=rows_per_chunk): for index, row in chunk.iterrows(): print(row) print('-' * 50)
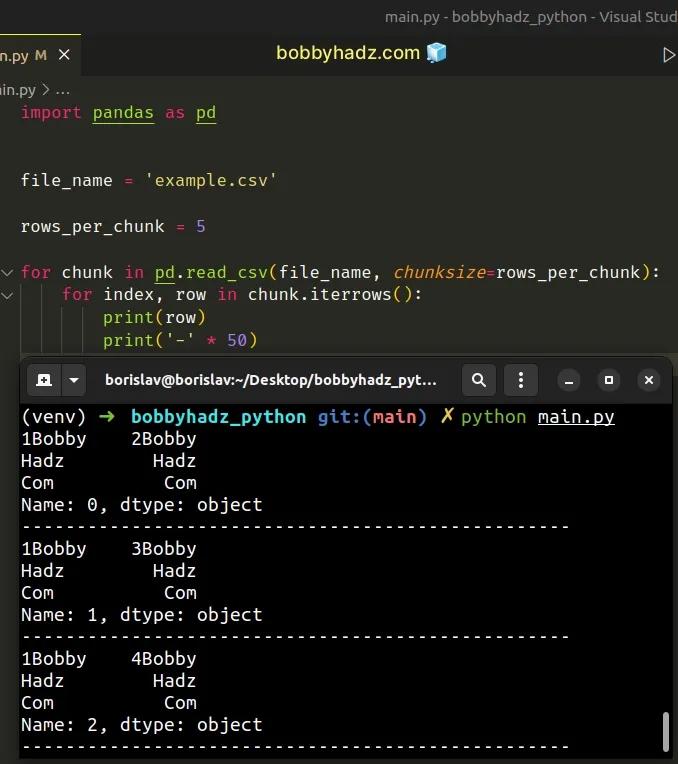
The outer for loop iterates over the file chunks.
The inner for loop iterates over the rows in each chunk.
If you print the chunk variable, you will see that each chunk consists of 5
rows because that is what we set the chunksize argument to.
import pandas as pd file_name = 'example.csv' rows_per_chunk = 5 for chunk in pd.read_csv(file_name, chunksize=rows_per_chunk): print(chunk) print('-' * 50)
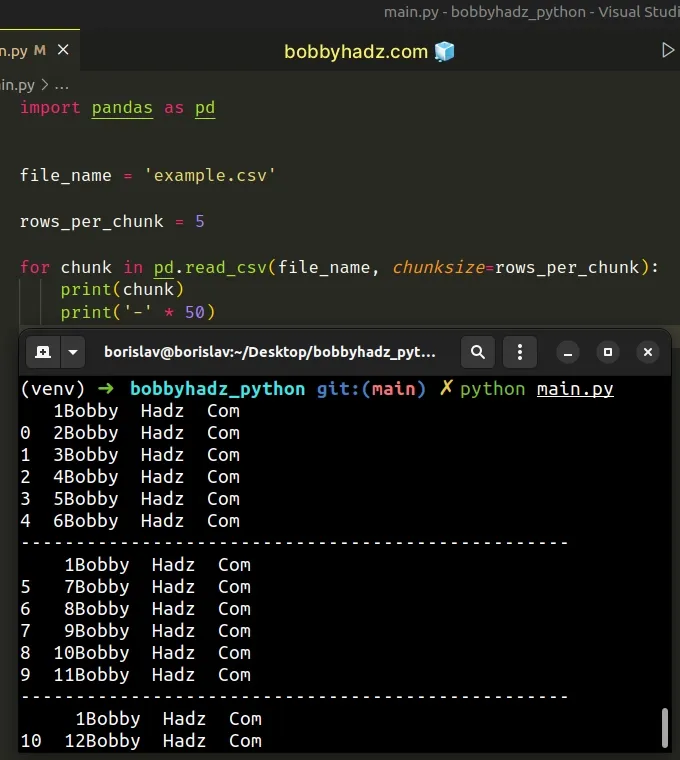
Note that using the with pd.read_csv context manager is more performant than
using a nested for loop.
# Pandas: Reading a large CSV file by only loading in specific columns
In some cases, you might be able to lower your memory consumption by only
loading in specific columns of the file
via the usecols argument.
Suppose we have the following example.csv file.
A,B,C 1Bobby,Hadz,Com 2Bobby,Hadz,Com 3Bobby,Hadz,Com 4Bobby,Hadz,Com 5Bobby,Hadz,Com 6Bobby,Hadz,Com 7Bobby,Hadz,Com 8Bobby,Hadz,Com 9Bobby,Hadz,Com 10Bobby,Hadz,Com 11Bobby,Hadz,Com 12Bobby,Hadz,Com 13Bobby,Hadz,Com 14Bobby,Hadz,Com 15Bobby,Hadz,Com 16Bobby,Hadz,Com 17Bobby,Hadz,Com 18Bobby,Hadz,Com 19Bobby,Hadz,Com 20Bobby,Hadz,Com
Here is the related Python code.
import pandas as pd file_name = 'example.csv' df = pd.read_csv(file_name, usecols=['A', 'B']) # A B # 0 1Bobby Hadz # 1 2Bobby Hadz # 2 3Bobby Hadz # 3 4Bobby Hadz # ... the rest of the rows here print(df)
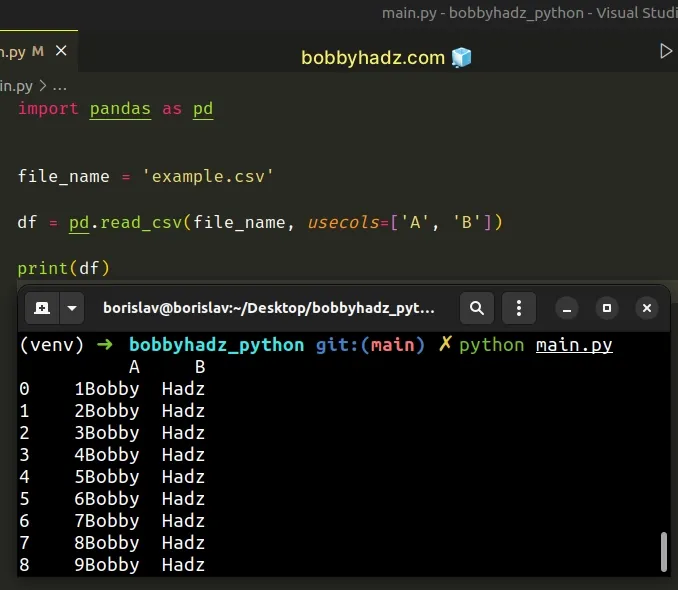
We set the usecols argument in the call to pandas.read_csv() to only load
the A and B columns from the CSV file.
df = pd.read_csv(file_name, usecols=['A', 'B'])
The DataFrame only contains the specified columns.
The usecols argument is a list-like object that contains a subset of the
column names.
I've also written a detailed guide on how to read specific columns from an Excel file in Pandas.
# Pandas: Read a large CSV file by using the Dask package
You can also use the popular dask package to read a large CSV file in Pandas.
First, install the package by running the following command.
pip install dask # or with pip3 pip3 install dask
Suppose we have the following example.csv file.
A,B,C 1Bobby,Hadz,Com 2Bobby,Hadz,Com 3Bobby,Hadz,Com 4Bobby,Hadz,Com 5Bobby,Hadz,Com 6Bobby,Hadz,Com 7Bobby,Hadz,Com 8Bobby,Hadz,Com 9Bobby,Hadz,Com 10Bobby,Hadz,Com 11Bobby,Hadz,Com 12Bobby,Hadz,Com 13Bobby,Hadz,Com 14Bobby,Hadz,Com 15Bobby,Hadz,Com 16Bobby,Hadz,Com 17Bobby,Hadz,Com 18Bobby,Hadz,Com 19Bobby,Hadz,Com 20Bobby,Hadz,Com
Import and use the dask module as follows.
import dask.dataframe as dd file_name = 'example.csv' df = dd.read_csv(file_name) print(df.head())
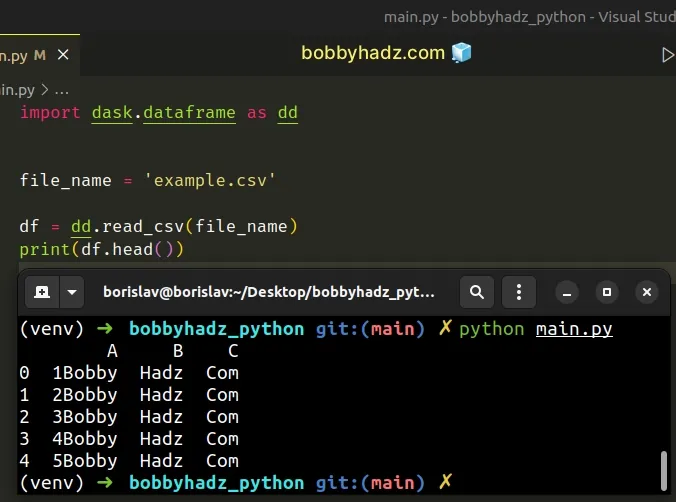
A Dask DataFrame is a large parallel DataFrame that is composed of many
smaller Pandas DataFrames split along the index.
These Pandas DataFrames may live on disk to allow for larger-than-memory computing on a single machine.
# Only selecting the first N rows of the CSV file
If you only want to work with the first N rows of the CSV file, set the nrows
argument when calling pandas.read_csv.
import pandas as pd file_name = 'example.csv' df = pd.read_csv(file_name, nrows=10) print(df)
Running the code sample produces the following output.
A B C 0 1Bobby Hadz Com 1 2Bobby Hadz Com 2 3Bobby Hadz Com 3 4Bobby Hadz Com 4 5Bobby Hadz Com 5 6Bobby Hadz Com 6 7Bobby Hadz Com 7 8Bobby Hadz Com 8 9Bobby Hadz Com 9 10Bobby Hadz Com
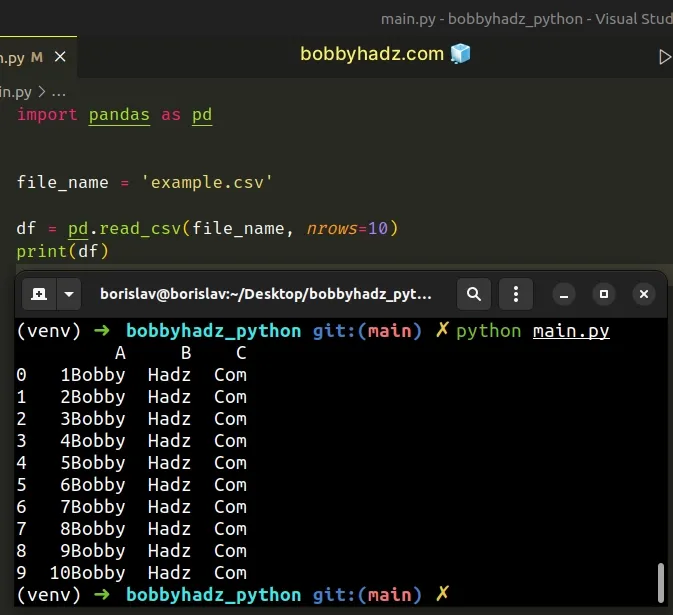
The nrows argument is an integer that represents the number of rows of the CSV
file to read.
df = pd.read_csv(file_name, nrows=10)
# Pandas: Reading a large CSV file with the modin module
You can also use the modin module to read a large CSV file in Pandas.
First, install the module by running the following command.
pip install "modin[all]" # or with pip3 pip3 install "modin[all]"
The command installs the Modin module and all of its supported engines.
Suppose we have the same example.csv file.
A,B,C 1Bobby,Hadz,Com 2Bobby,Hadz,Com 3Bobby,Hadz,Com 4Bobby,Hadz,Com 5Bobby,Hadz,Com 6Bobby,Hadz,Com 7Bobby,Hadz,Com 8Bobby,Hadz,Com 9Bobby,Hadz,Com 10Bobby,Hadz,Com 11Bobby,Hadz,Com 12Bobby,Hadz,Com 13Bobby,Hadz,Com 14Bobby,Hadz,Com 15Bobby,Hadz,Com 16Bobby,Hadz,Com 17Bobby,Hadz,Com 18Bobby,Hadz,Com 19Bobby,Hadz,Com 20Bobby,Hadz,Com
Here is the related Python code.
import modin.pandas as pd file_name = 'example.csv' df = pd.read_csv(file_name) print(df)
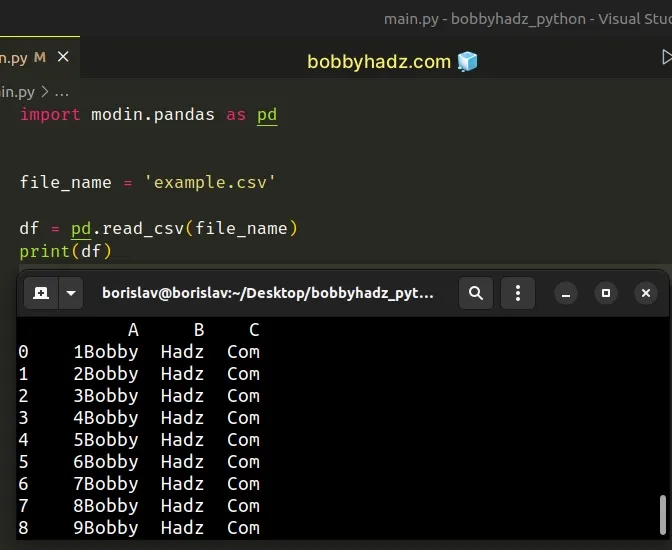
The Modin module is a drop-in replacement for Pandas.
The Modin module enables you to scale Pandas by using all of your cores.
On the other hand, Pandas is single-threaded.
The Modin module is especially useful if you're running into MemoryError
exceptions when using Pandas or when processing your data takes too much time.
Notice that the only thing we had to update is the import statement.
According to the modin docs, the
pandas.read_csv() method should be about 2.5x faster if it comes from the
Modin module.
I've also written an article on how to split a Pandas DataFrame into chunks.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- How to read a .mat (Matplotlib) file in Python
- Python: How to center the Title in Plotly
- ValueError: Expected object or value with
pd.read_json() - Mixing dicts with non-Series may lead to ambiguous ordering
- RuntimeError: CUDA out of memory. Tried to allocate X MiB

