Get the column names of a NumPy ndarray in Python
Last updated: Apr 11, 2024
Reading time·4 min

# Table of Contents
- Get the column names of a NumPy ndarray in Python
- Adding column names to a plain NumPy ndarray
- Getting the column names of a Pandas DataFrame
# Get the column names of a NumPy ndarray in Python
Use the dtype.names attribute to get the column names of a NumPy ndarray
in Python.
The dtype.names attribute returns a tuple of the field names of the
ndarray.
import numpy as np data = np.genfromtxt( 'employees.txt', names=True, encoding='utf-8', delimiter=',', dtype=None, ) # [('Alice', 'Smith', '2023-01-05') ('Bobby', 'Hadz', '2023-03-25') print(data) # ('first_name', 'last_name', 'date') print(data.dtype.names)
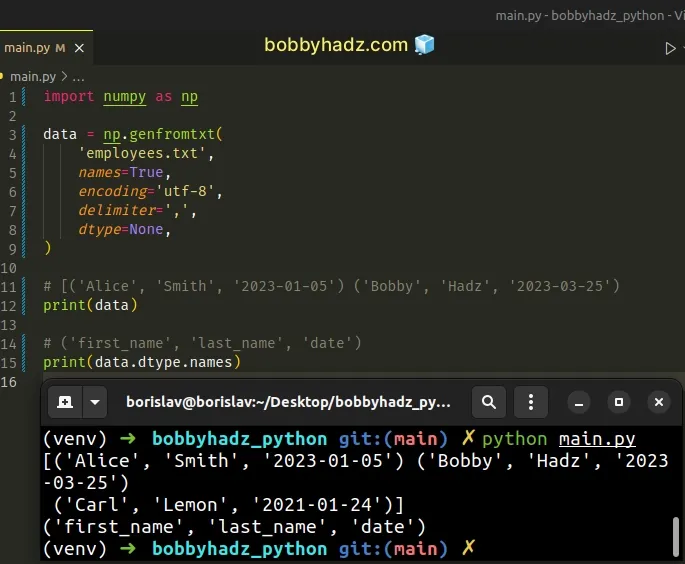
The code sample assumes that you have the following employees.txt file in the
same directory as your main.py script.
first_name,last_name,date Alice,Smith,2023-01-05 Bobby,Hadz,2023-03-25 Carl,Lemon,2021-01-24
We used the
numpy.genfromtext()
method to load the data from the file into a NumPy ndarray.
data = np.genfromtxt( 'employees.txt', names=True, encoding='utf-8', delimiter=',', dtype=None, )
Each line past the first is split at the specified delimiter character (a , in
the example).
We then used the
dtype.names
attribute to get the column names of the ndarray.
# ('first_name', 'last_name', 'date') print(data.dtype.names)
The dtype.names attribute returns a tuple of the field names of the array, or
None if there are no field names.
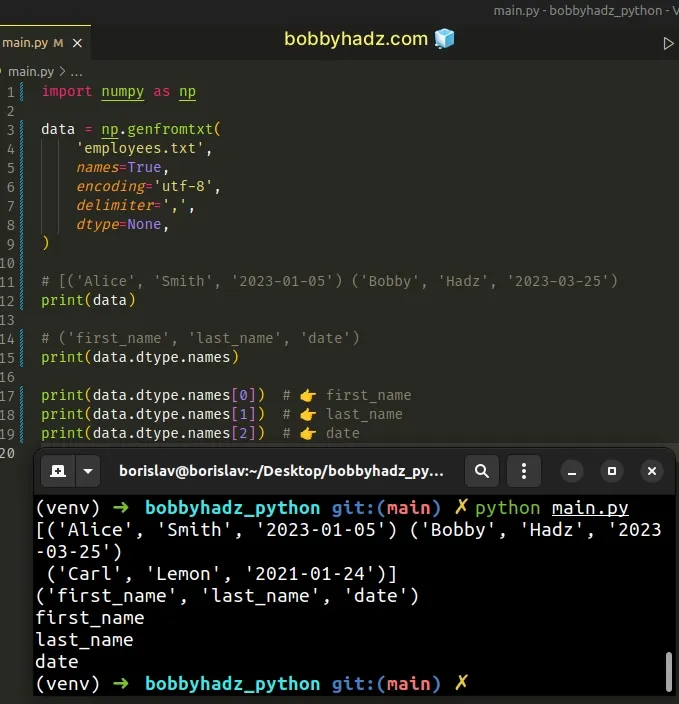
You can use indexing to access specific column names in the tuple.
import numpy as np data = np.genfromtxt( 'employees.txt', names=True, encoding='utf-8', delimiter=',', dtype=None, ) # [('Alice', 'Smith', '2023-01-05') ('Bobby', 'Hadz', '2023-03-25') print(data) # ('first_name', 'last_name', 'date') print(data.dtype.names) print(data.dtype.names[0]) # 👉️ first_name print(data.dtype.names[1]) # 👉️ last_name print(data.dtype.names[2]) # 👉️ date
# Adding column names to a plain NumPy ndarray
If you need to add column names to a plain NumPy ndarray, use the
unstructured_to_structured method.
import numpy as np import numpy.lib.recfunctions as rfn arr = np.array([[1, 2, 3], [4, 5, 6]]) new_arr = rfn.unstructured_to_structured( arr, np.dtype( [ ('Column_1', int), ('Column_2', int), ('Column_3', int) ] ) ) # 👇️ [(1, 2, 3) (4, 5, 6)] print(new_arr) # 👇️ ('Column_1', 'Column_2', 'Column_3') print(new_arr.dtype.names) print(new_arr['Column_1']) # 👉️ [1 4]
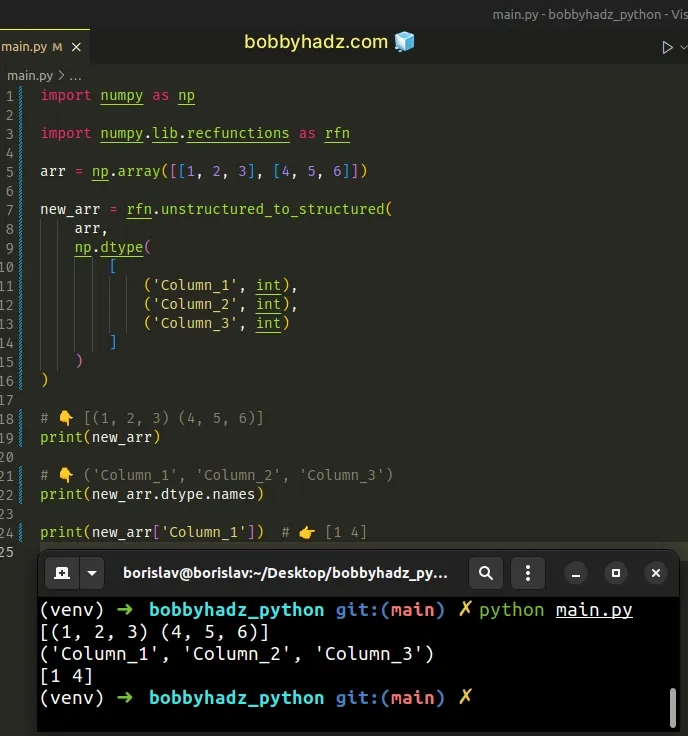
We defined a plain NumPy array and used the unstructured_to_structured()
method to convert the unstructured array to a structured array.
We set the array's column names and used dtype.names to get a tuple containing
the names.
As shown in the code sample, you can use square brackets to access the elements of the array by column names.
# Getting the column names of a Pandas DataFrame
If you need to read values from a CSV file and get the column names, you can
also use the pandas module.
First, make sure
you have the pandas module installed by
running the following command from your terminal.
pip install pandas # or with pip3 pip3 install pandas
Here is the employee.csv file for the example.
first_name,last_name,date Alice,Smith,2023-01-05 Bobby,Hadz,2023-03-25 Carl,Lemon,2021-01-24
And here is the related main.py file.
import pandas as pd df = pd.read_csv( 'employees.csv', sep=',', encoding='utf-8' ) # first_name last_name date # 0 Alice Smith 2023-01-05 # 1 Bobby Hadz 2023-03-25 # 2 Carl Lemon 2021-01-24 print(df) print('-' * 50) # 👇️ Index(['first_name', 'last_name', 'date'], dtype='object') print(df.columns) print('-' * 50) # 👇️ ['first_name', 'last_name', 'date'] print(df.columns.tolist())
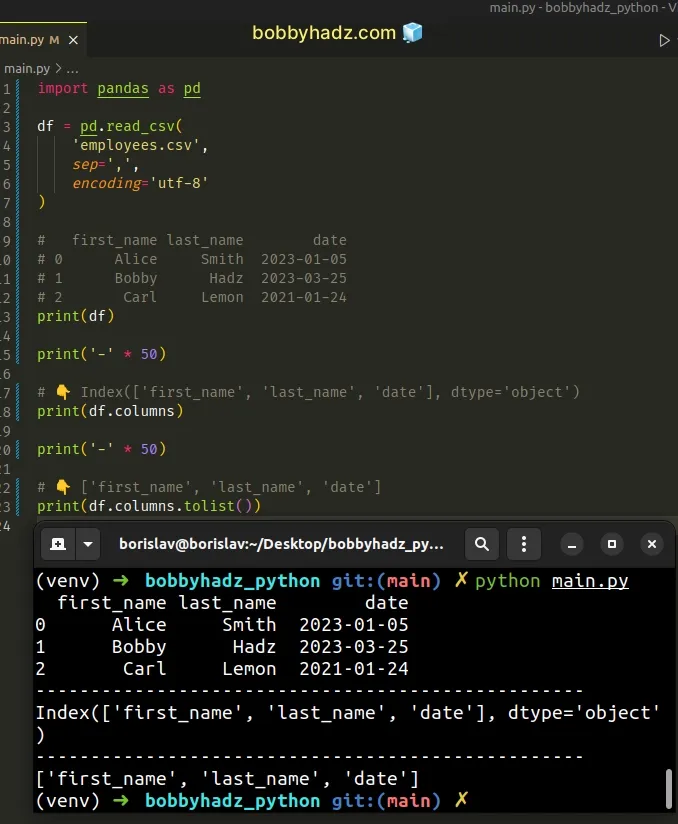
We used the
pandas.read_csv() method
to read the comma-separated CSV file into a DataFrame object.
You can then use the
DataFrame.columns()
method to get the column labels of the DataFrame.
If you need to convert the object to a list, use the tolist() method.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- TypeError: Image data cannot be converted to float [Solved]
- OverflowError: Python int too large to convert to C long
- How to use numpy.argsort in Descending order in Python
- Object arrays cannot be loaded when allow_pickle=False
- ufunc 'add' did not contain loop with signature matching types
- ValueError: Found array with dim 3. Estimator expected 2
- RuntimeWarning: overflow encountered in exp [Solved]
- Columns have mixed types. Specify dtype option on import
- Boolean index did not match indexed array along dimension 0
- Shape mismatch: objects cannot be broadcast to a single shape
- Finding the Range of NumPy Array elements in Python
- Convert Epoch to Datetime in a Pandas DataFrame
- Pandas: Find length of longest String in DataFrame column
- How to add a Count Column to a Pandas DataFrame
- How to swap two DataFrame columns in Pandas
- Pandas: Make new Column from string Slice of another Column
- Get N random Rows from a NumPy Array in Python
- Create Date column from Year, Month and Day in Pandas
- How to flatten only some Dimensions of a NumPy array
- Remove the Duplicate elements from a NumPy Array
- NumPy: Apply a Mask from one Array to another Array
- How to iterate over the Columns of a NumPy Array
- Pandas: Find an element's Index in Series [7 Ways]
- numpy.linalg.LinAlgError: Singular matrix [Solved]
- First argument must be an iterable of pandas objects [Fix]
- Pandas: Remove special characters from Column Values/Names
- Pandas: Count the unique combinations of two Columns
- Pandas: How to efficiently Read a Large CSV File

