Object arrays cannot be loaded when allow_pickle=False
Last updated: Apr 11, 2024
Reading time·4 min

# Object arrays cannot be loaded when allow_pickle=False
The Python "ValueError: Object arrays cannot be loaded when allow_pickle=False
" occurs when you try to load an object array with the allow_pickle argument
set to False.
To solve the error, set the allow_pickle argument to True or change the
type of the array.
Here is an example of how the error occurs.
import numpy as np np.save('data.npy', np.array([[1, 2, 3], [4, 5, 6]], dtype=object)) arr = np.load('data.npy', allow_pickle=False) # ⛔️ ValueError: Object arrays cannot be loaded when allow_pickle=False print(arr)
We used the
numpy.save()
method to save an array to a binary file in NumPy (.npy) format.
The first argument the method takes is the file path.
The second argument is the array that should be saved and the third is the data type.
Notice that we set the
dtype to
object.
The
numpy.load()
method loads arrays or pickled objects from .npy, .npz or pickled files.
The first argument the method takes is the file path.
allow_pickle keyword argument determines whether it is allowed to load pickled object arrays that are stored in .npy files.If the allow_pickle argument is set to False, loading object arrays causes
the error.
By default, the allow_pickle argument is set to False.
# Set the allow_pickle argument to True to solve the error
One way to solve the error is to set the allow_pickle argument to True.
import numpy as np np.save('data.npy', np.array([[1, 2, 3], [4, 5, 6]], dtype=object)) arr = np.load('data.npy', allow_pickle=True) # [[1 2 3] # [4 5 6]] print(arr)
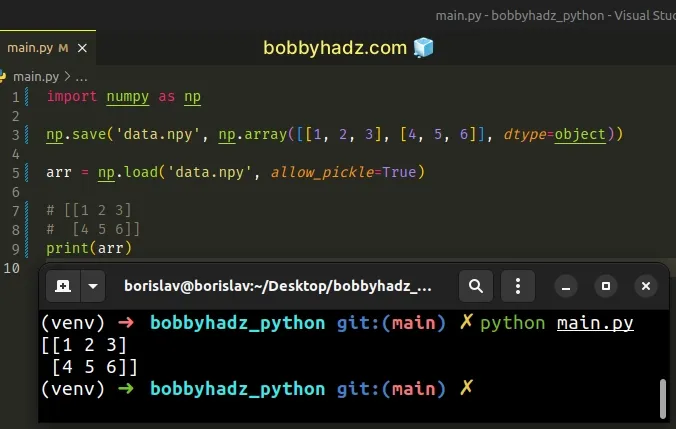
When the allow_pickle keyword argument is set to True, loading object arrays
is allowed.
Note that the default value of the allow_pickle argument is False, so it has
to be explicitly specified.
The allow_pickle argument can also be passed to the numpy.save() method.
import numpy as np np.save( 'data.npy', np.array([[1, 2, 3], [4, 5, 6]], dtype=object), allow_pickle=True ) arr = np.load('data.npy', allow_pickle=True) # [[1 2 3] # [4 5 6]] print(arr)
However, passing the allow_pickle argument to numpy.save() is not necessary
as it defaults to True.
You can also set the allow_pickle argument to True when using the with
statement.
Replace this:
# ⛔️ Incorrect import numpy as np with np.load('data.npy') as arr: print(arr)
With this:
# ✅ Correct import numpy as np with np.load('data.npy', allow_pickle=True) as arr: print(arr)
# Setting a different data type for the NumPy array
You can also set a different data type for the NumPy array to solve the error.
For the error to occur, 2 conditions have to be met:
- The
allow_pickleargument has to be set toFalse. - The data type of the array has to be set to
object.
You can set the data type of the array to int or float to solve the error.
import numpy as np np.save( 'data.npy', np.array([[1, 2, 3], [4, 5, 6]], dtype=int), ) arr = np.load('data.npy') # [[1 2 3] # [4 5 6]] print(arr)
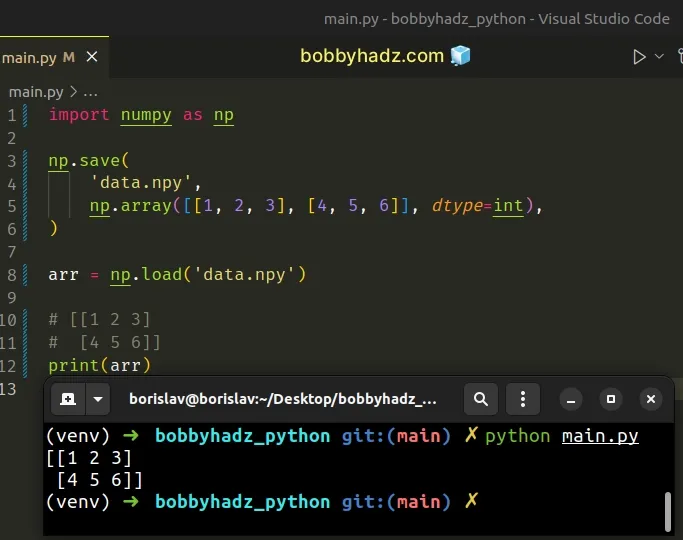
We set the dtype (data type) of the array to int instead of object.
Notice that we didn't have to explicitly set the allow_pickle keyword
argument.
# Try to downgrade numpy to version 1.16.1
If you use keras, you can also try to downgrade your version of the numpy
module to 1.16.1 as the error occurs in numpy version 1.16.4 and more
recent.
Open your terminal in your project's root directory and run the following command.
pip install numpy==1.16.1 # or with pip3 pip3 install numpy==1.16.1 # or in Jupyter notebook !pip install numpy==1.16.1 # or with Anaconda conda install numpy==1.16.1
If you have a requirements.txt file, you can add the following line.
numpy==1.16.1
# Solving the error when using keras
If you got the error when using the load_data() method in keras, try to set
the default value of the allow_pickle keyword argument to True.
import numpy as np from tensorflow import keras np.load.__defaults__ = (None, True, True, 'ASCII') np.save('data.npy', np.array([[1, 2, 3], [4, 5, 6]], dtype=object)) (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() np.load.__defaults__ = (None, False, True, 'ASCII')
We updated the __defaults__ tuple of the numpy.load() method, setting
allow_pickle to True.
allow_pickle is the second argument in the tuple.
Once we're done, we set the default value of the argument back to False.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Cannot import name 'pad_sequences' from 'keras.preprocessing.sequence'
- ModuleNotFoundError: No module named 'tensorflow' in Python
- ValueError: cannot reshape array of size X into shape Y
- lbfgs failed to converge (status=1): STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
- How to draw empty circles on a Scatter Plot in Matplotlib
- TypeError: Image data cannot be converted to float [Solved]
- OverflowError: Python int too large to convert to C long
- How to use numpy.argsort in Descending order in Python
- TypeError: cannot pickle '_thread.lock' object [Solved]
- ValueError: Columns must be same length as key [Solved]
- ufunc 'add' did not contain loop with signature matching types
- ValueError: Found array with dim 3. Estimator expected 2
- Input contains infinity or value too large for dtype(float64)
- ValueError: unsupported pickle protocol: 5 [Solved]
- ValueError: columns overlap but no suffix specified [Solved]
- Get the first Row of each Group in a Pandas DataFrame
- How to Multiply two or more Columns in Pandas
- Add columns of a different Length to a DataFrame in Pandas

