Pandas: Remove special characters from Column Values/Names
Last updated: Apr 12, 2024
Reading time·6 min

# Table of Contents
- Pandas: Remove special characters from Column Values
- Pandas: Remove special characters from Column Names
Note, if you need to remove the special characters from column names, click on the second subheading.
# Pandas: Remove special characters from Column Values
To remove the special characters from a column's values in Pandas:
- Use bracket notation to access the specific column.
- Use the
str.replace()method with a regular expression. - The method will replace all special characters with an empty string to remove them.
import pandas as pd df = pd.DataFrame({ '$name$': ['Ali#ce', 'Bobby@', 'Ca$r%l', 'D^a&n'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) df['$name$'] = df['$name$'].str.replace(r'\W', '', regex=True) # $name$ !experience@ ^salary* # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)
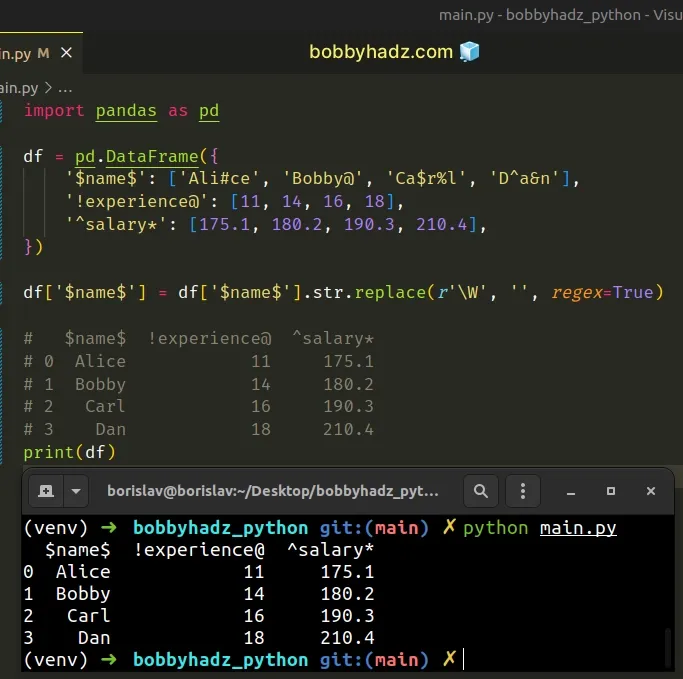
We used bracket notation to select the $name$ column and then called the
str.replace()
method.
df['$name$'] = df['$name$'].str.replace(r'\W', '', regex=True)
The first argument we passed to the method is a regular expression that we want to match against each column value.
The second argument is the replacement string for each match.
regex argument to True to indicate that the passed-in pattern is a regular expression and not a string literal.By default, the regex argument is set to False, which means that the
supplied pattern gets treated like a string literal (and not a regular
expression).
The \W special character is equivalent to [^A-Za-z0-9_].
In other words, the \W character matches:
- any character that is not a word character from the basic Latin alphabet
- non-digit characters
- not underscores
# The \W special character does not remove underscores
Note that the \W special character doesn't remove the underscores from the
string.
import pandas as pd df = pd.DataFrame({ '$name$': ['Ali#c_e', 'Bo_bby@', 'Ca$r%l', 'D^a&n'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) df['$name$'] = df['$name$'].str.replace(r'\W', '', regex=True) # $name$ !experience@ ^salary* # 0 Alic_e 11 175.1 # 1 Bo_bby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)
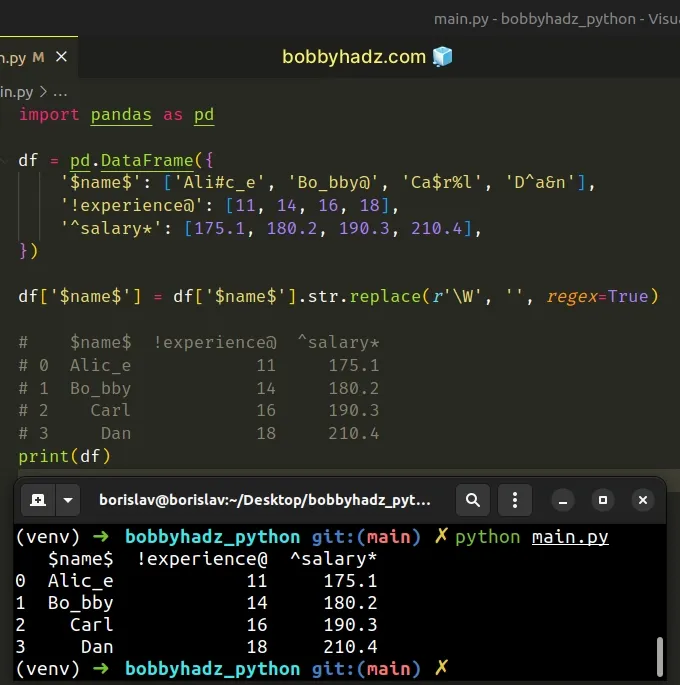
Notice that the underscores were not removed from each value.
# Also considering the underscores to be special characters
If you also want to remove the underscores, use the following regular expression instead.
import re import pandas as pd df = pd.DataFrame({ '$name$': ['Ali#c_e', 'Bo_bby@', 'Ca$r%l', 'D^a&n'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) df['$name$'] = df['$name$'].str.replace( r'[^a-z0-9]', '', regex=True, flags=re.IGNORECASE ) # $name$ !experience@ ^salary* # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)

The updated regular expression also considers underscores to be special characters.
The caret ^ symbol means "NOT the following". In our case, this means not
any letter in the range of a-z and not any number in the range of 0-9.
All other characters get replaced with an empty string.
Notice that we also set the re.IGNORECASE flag in the call to str.replace().
This makes our match case-insensitive by targeting all uppercase and lowercase characters.
# The regular expression also considers spaces to be special characters
The current regular expression also considers spaces to be special characters.
import re import pandas as pd df = pd.DataFrame({ '$name$': ['Ali# c_e', 'Bo_b by@', 'Ca$r %l', 'D^a &n'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) df['$name$'] = df['$name$'].str.replace( r'[^a-z0-9]', '', regex=True, flags=re.IGNORECASE ) # $name$ !experience@ ^salary* # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)
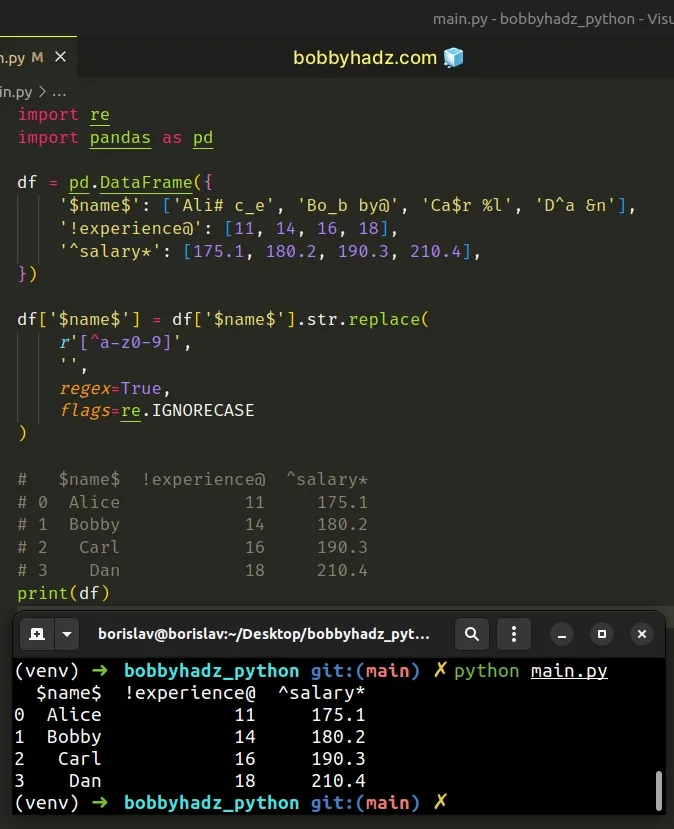
Notice that the spaces in the column values were also removed.
If you want to keep the spaces when removing the special characters, use the following regular expression instead.
import re import pandas as pd df = pd.DataFrame({ '$name$': ['Ali# c_e', 'Bo_b by@', 'Ca$r %l', 'D^a &n'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) df['$name$'] = df['$name$'].str.replace( r'[^a-z0-9\s]', '', regex=True, flags=re.IGNORECASE ) # $name$ !experience@ ^salary* # 0 Ali ce 11 175.1 # 1 Bob by 14 180.2 # 2 Car l 16 190.3 # 3 Da n 18 210.4 print(df)
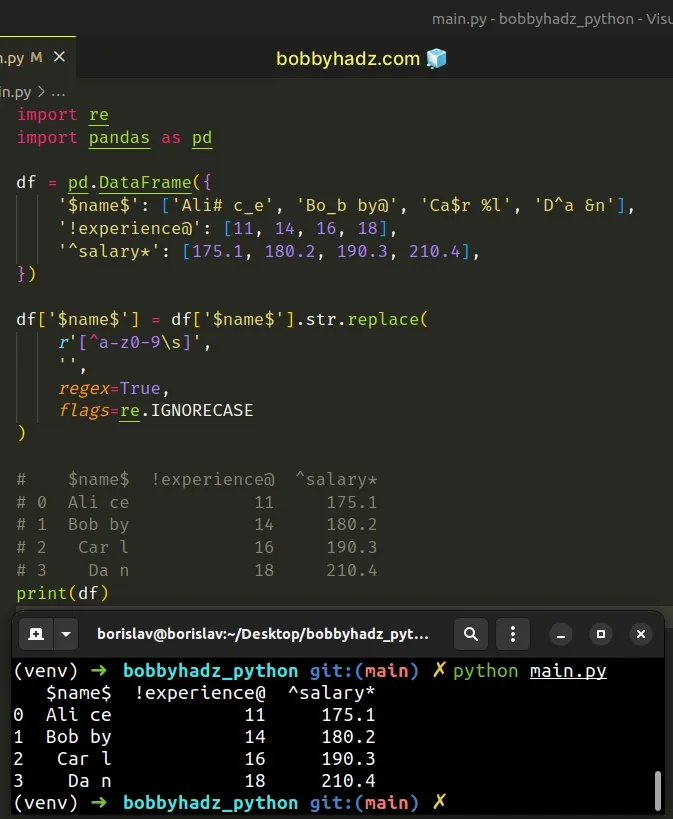
The \s character matches Unicode whitespace characters like [ \t\n\r\f\v].
All spaces in the column values are kept in the result.
I've also written a detailed guide on how to remove special characters except spaces in Python.
# Pandas: Remove special characters from Column Names
To remove the special characters from column names in Pandas:
- Access the
DataFrame.columnsproperty to get an Index containing the column names. - Set the property to the result of calling
str.replace()method with a regular expression. - Replace all special characters with an empty string to remove them.
import pandas as pd df = pd.DataFrame({ '$name$': ['Alice', 'Bobby', 'Carl', 'Dan'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) df.columns = df.columns.str.replace(r'\W', '', regex=True) # name experience salary # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)
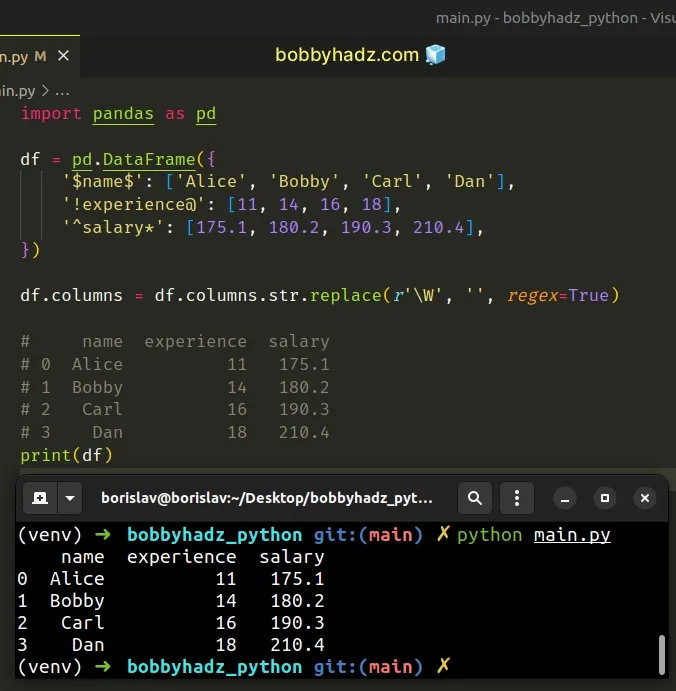
The
DataFrame.columns
property returns an Index object that contains the column names.
import pandas as pd df = pd.DataFrame({ '$name$': ['Alice', 'Bobby', 'Carl', 'Dan'], '!experience@': [11, 14, 16, 18], '^salary*': [175.1, 180.2, 190.3, 210.4], }) # Index(['$name$', '!experience@', '^salary*'], dtype='object') print(df.columns)
We set the property to the result of calling replace() on the Index object.
df.columns = df.columns.str.replace(r'\W', '', regex=True)
The first argument we passed to replace() is a regular expression.
The \W special character is equivalent to [^A-Za-z0-9_].
In other words, the \W character matches:
- any character that is not a word character from the basic Latin alphabet
- non-digit characters
- not underscores
The third sets the regex argument to True to indicate to replace() that we
passed it a regular expression and not a string literal.
# By default, underscores won't be removed from column names
By default, the \W special character won't remove underscores from column
names.
import pandas as pd df = pd.DataFrame({ '$na_me$': ['Alice', 'Bobby', 'Carl', 'Dan'], '!expe_rience@': [11, 14, 16, 18], '^sal_ary*': [175.1, 180.2, 190.3, 210.4], }) df.columns = df.columns.str.replace(r'\W', '', regex=True) # na_me expe_rience sal_ary # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)
If you also want to remove the underscores from the column names, use the following regular expression instead.
import re import pandas as pd df = pd.DataFrame({ '$na_me$': ['Alice', 'Bobby', 'Carl', 'Dan'], '!expe_rience@': [11, 14, 16, 18], '^sal_ary*': [175.1, 180.2, 190.3, 210.4], }) df.columns = df.columns.str.replace( r'[^a-z0-9]', '', regex=True, flags=re.IGNORECASE ) # name experience salary # 0 Alice 11 175.1 # 1 Bobby 14 180.2 # 2 Carl 16 190.3 # 3 Dan 18 210.4 print(df)
The caret ^ symbol means "NOT the following". In our case, this means not
any letter in the range of a-z and not any number in the range of 0-9.
All other characters get replaced with an empty string.
Notice that we also set the re.IGNORECASE flag in the call to str.replace().
This makes our match case-insensitive by targeting all uppercase and lowercase characters.
I've also written an article on how to filter rows in a Pandas DataFrame using a Regex.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove the Duplicate elements from a NumPy Array
- NumPy: Apply a Mask from one Array to another Array
- How to iterate over the Columns of a NumPy Array
- Pandas: Find an element's Index in Series [7 Ways]
- numpy.linalg.LinAlgError: Singular matrix [Solved]
- First argument must be an iterable of pandas objects [Fix]
- PyTorch: Trying to backward through the graph a second time

