Pandas: Count the unique combinations of two Columns
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- Pandas: Count the unique combinations of two Columns
- Getting the result as a Series
- Pandas: Count the unique combinations of two Columns using DataFrame.value_counts()
# Pandas: Count the unique combinations of two Columns
To count the unique combinations of two columns in Pandas:
- Use the
DataFrame.groupby()method to group theDataFrameby the two columns. - Use the
size()method to compute the group sizes. - Reset the
indexand optionally rename the column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) result = df.groupby(['name', 'task']).size().reset_index().rename( columns={0: 'count'} ) print(result)
Running the code sample produces the following output.
name task count 0 Alice dev 2 1 Alice test 2 2 Bobby dev 1 3 Bobby test 1
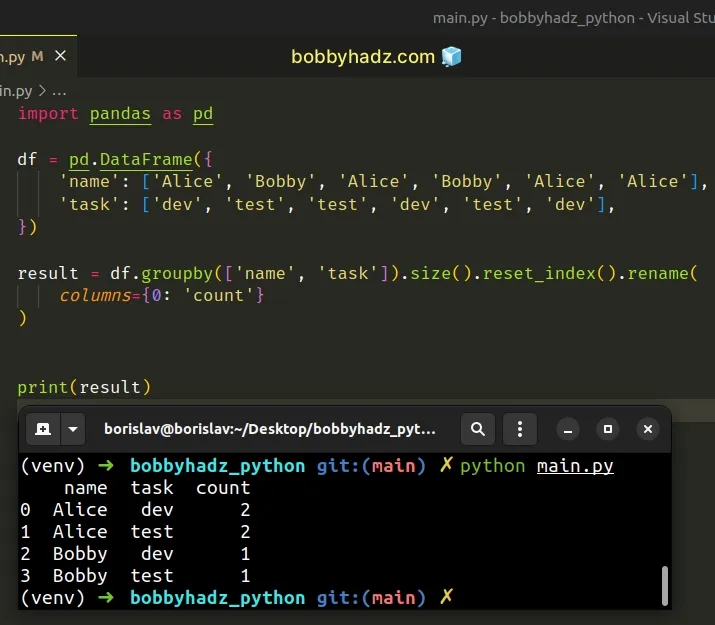
We used the
DataFrame.groupby()
method to group the DataFrame by the name and task columns.
result = df.groupby(['name', 'task']).size().reset_index().rename( columns={0: 'count'} )
By grouping the DataFrame by the two columns, we get the rows where the name
and task column values are the same.
The next step is to use the DataFrameGroupBy.size() method to compute the group sizes.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) # name task # Alice dev 2 # test 2 # Bobby dev 1 # test 1 # dtype: int64 print(df.groupby(['name', 'task']).size())
once we have the size of each group, we can reset the index.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) # name task 0 # 0 Alice dev 2 # 1 Alice test 2 # 2 Bobby dev 1 # 3 Bobby test 1 print(df.groupby(['name', 'task']).size().reset_index())
The last step is to rename the 0 column to "count".
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) result = df.groupby(['name', 'task']).size().reset_index().rename( columns={0: 'count'} ) # name task count # 0 Alice dev 2 # 1 Alice test 2 # 2 Bobby dev 1 # 3 Bobby test 1 print(result)
The DataFrame.rename()
method renames the columns or index labels of a DataFrame.
# Getting the result as a Series
If you set the as_index argument to False in the call to
DataFrame.groupby(), you will get the result as a Series with a size
column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) result = df.groupby(['name', 'task'], as_index=False).size() # name task size # 0 Alice dev 2 # 1 Alice test 2 # 2 Bobby dev 1 # 3 Bobby test 1 print(result)
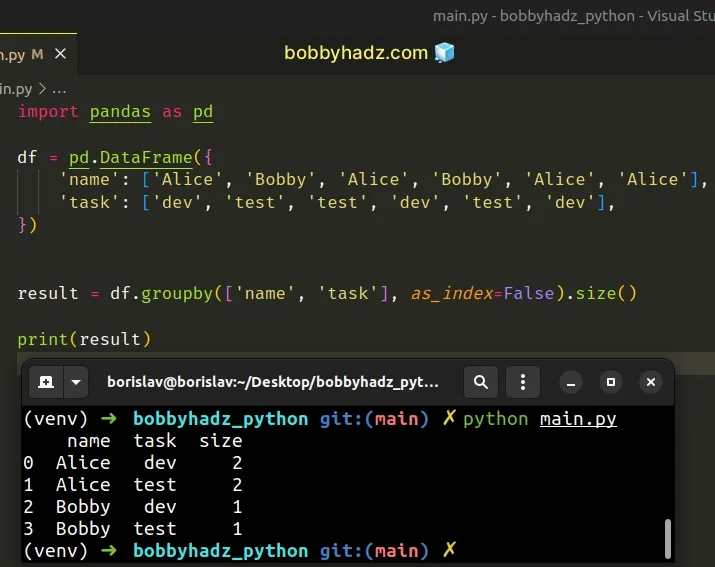
The as_index argument defaults to True and returns an object with group
labels as the index.
When it is set to False, SQL-style grouped output is returned.
# Pandas: Count the unique combinations of two Columns using DataFrame.value_counts()
You can also use the DataFrame.value_counts() method to count the unique combinations of two columns.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) result = df.value_counts() print(result)
Running the code sample produces the following output.
name task Alice dev 2 test 2 Bobby dev 1 test 1 Name: count, dtype: int64
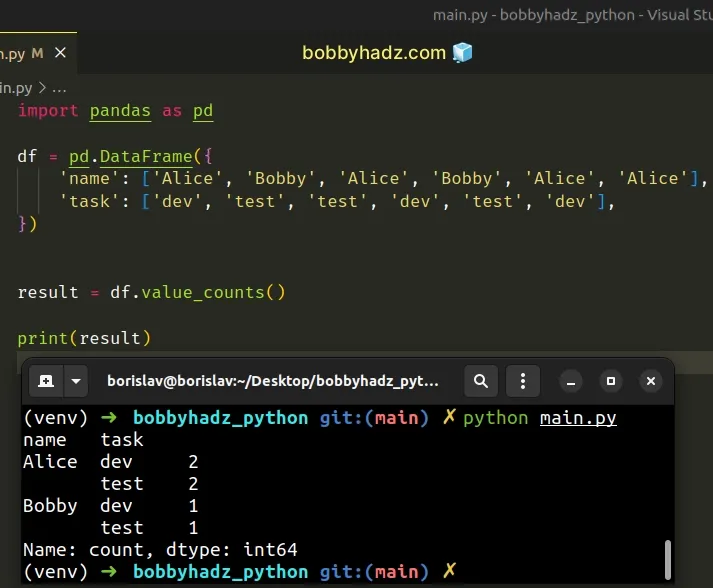
The
DataFrame.value_counts()
method returns a Series containing counts of unique rows in the DataFrame.
You can use the reset_index() method to get the result as a DataFrame.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) result = df.value_counts().reset_index(name='count') # name task count # 0 Alice dev 2 # 1 Alice test 2 # 2 Bobby dev 1 # 3 Bobby test 1 print(result)
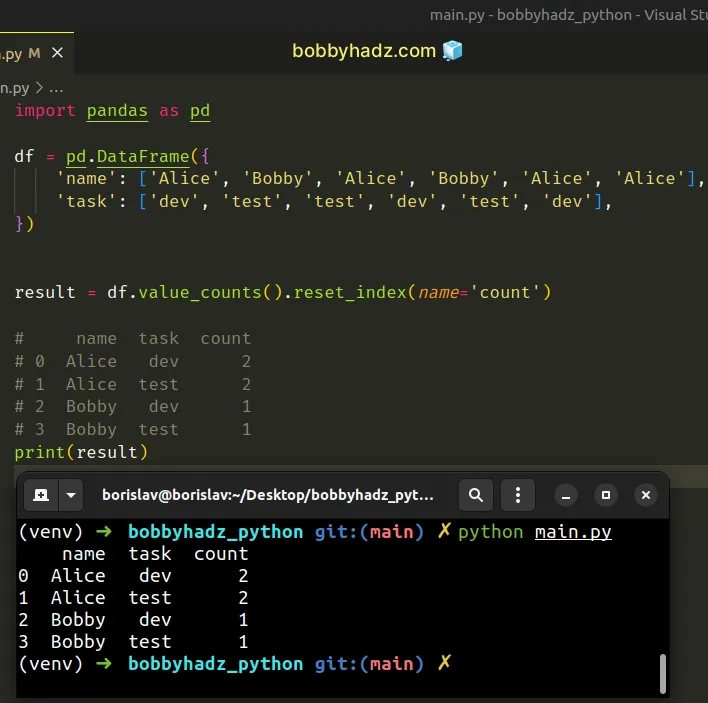
By default, the value_counts() method returns the values sorted in descending
order.
If you want to sort the values in ascending order, set the ascending argument
to True.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', 'test', 'dev', 'test', 'dev'], }) result = df.value_counts(ascending=True).reset_index(name='count') # name task count # 0 Bobby dev 1 # 1 Bobby test 1 # 2 Alice dev 2 # 3 Alice test 2 print(result)
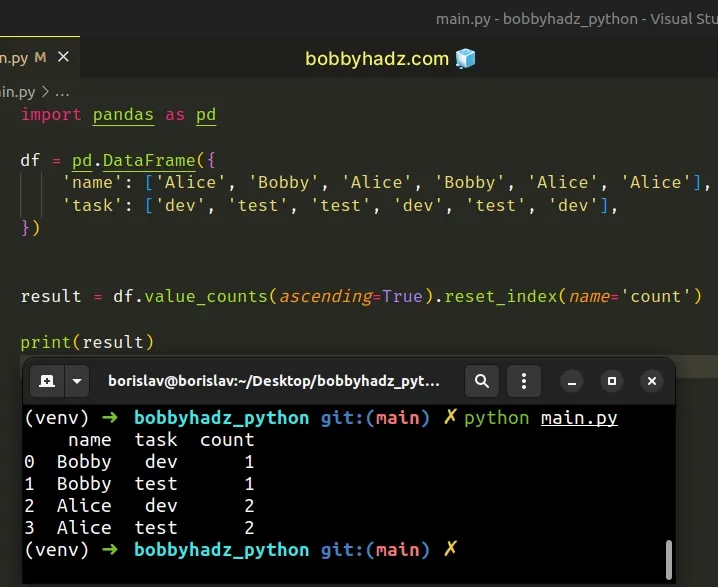
When the ascending argument is set to True, the results are sorted in
ascending order.
The argument defaults to False.
By default, the value_counts() method doesn't include counts of rows that
contain NA values.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', None, 'dev', 'test', None], }) result = df.value_counts().reset_index(name='count') # name task count # 0 Alice dev 1 # 1 Alice test 1 # 2 Bobby dev 1 # 3 Bobby test 1 print(result)
If you also want to include counts of rows that contain NA values, set the
dropna argument to False.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Alice', 'Bobby', 'Alice', 'Alice'], 'task': ['dev', 'test', None, 'dev', 'test', None], }) result = df.value_counts(dropna=False).reset_index(name='count') # name task count # 0 Alice NaN 2 # 1 Alice dev 1 # 2 Alice test 1 # 3 Bobby dev 1 # 4 Bobby test 1 print(result)
When the dropna argument is set to False, counts of rows that contain NA
values are included.
By default, the argument is set to True.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

