ValueError: Grouper for 'X' not 1-dimensional [Solved]
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- ValueError: Grouper for 'X' not 1-dimensional
- Creating MultiIndex columns by mistake
- Calling pandas.pivot_table() incorrectly
# ValueError: Grouper for 'X' not 1-dimensional [Solved]
The Pandas "ValueError: Grouper for 'X' not 1-dimensional" occurs when you
have duplicate column names in your DataFrame and try to call the groupby()
method.
To solve the error, make sure you don't have any duplicate column names before
calling groupby().
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'first': [10, 15, 20], 'second': [10, 15, 20], }) df.rename(columns={'first': 'second'}, inplace=True) print(df) # ⛔️ ValueError: Grouper for 'salary' not 1-dimensional print(df.groupby('second'))
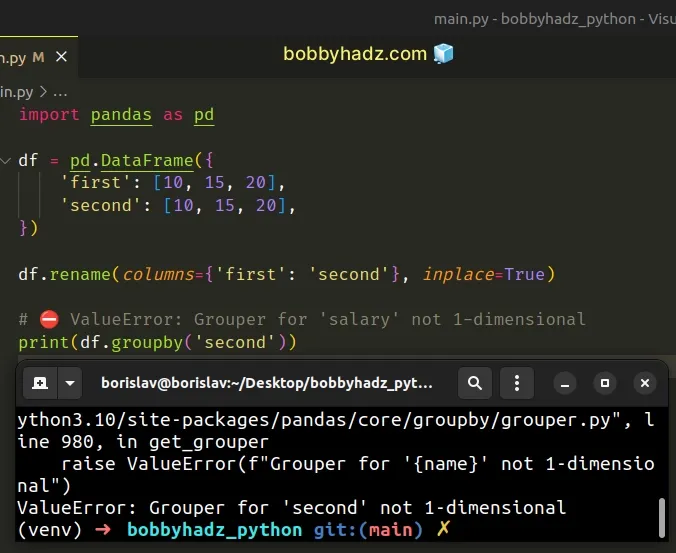
The error message "ValueError: Grouper for 'X' not 1-dimensional" basically
means that your DataFrame has more than 1 column named "X".
We renamed the first column to second, so the DataFrame has 2 columns with
the same name (second).
import pandas as pd df = pd.DataFrame({ 'first': [10, 15, 20], 'second': [10, 15, 20], }) df.rename(columns={'first': 'second'}, inplace=True) # second second # 0 10 10 # 1 15 15 # 2 20 20 print(df) # ⛔️ ValueError: Grouper for 'salary' not 1-dimensional print(df.groupby('second'))
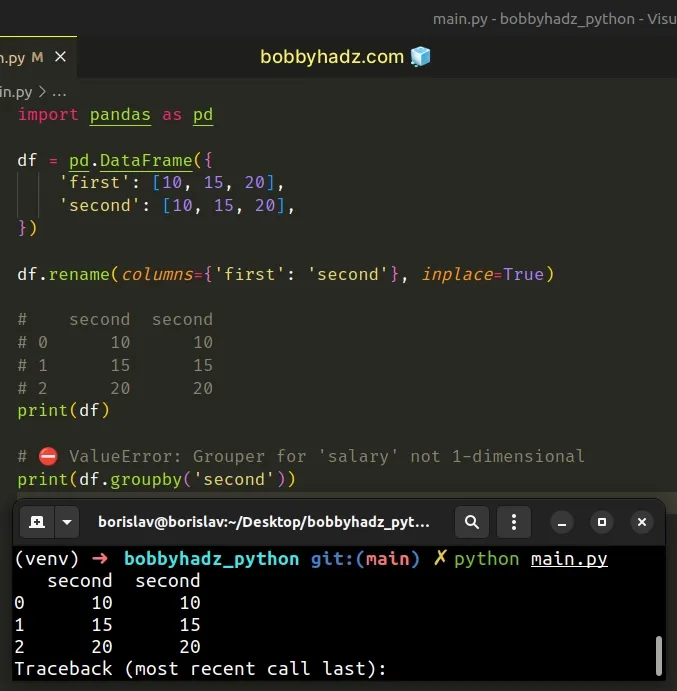
Calling the
DataFrame.groupby
method when your DataFrame has duplicate column names causes the error.
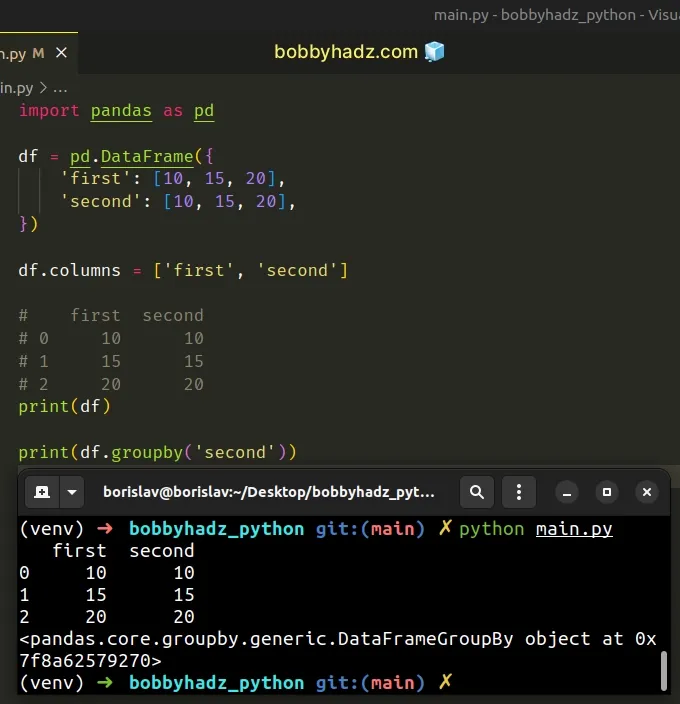
You can solve the error by renaming the columns in your DataFrame, so that
there are no duplicate names.
import pandas as pd df = pd.DataFrame({ 'first': [10, 15, 20], 'second': [10, 15, 20], }) df.columns = ['first', 'second'] # first second # 0 10 10 # 1 15 15 # 2 20 20 print(df) # <pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f8a62579270> print(df.groupby('second'))
Make sure to specify exactly as many columns between the square brackets as
there are in the DataFrame, otherwise, you'd get the
Length mismatch: Expected axis has X elements, new values have Y elements
error.
# Creating MultiIndex columns by mistake
The error also occurs when you create MultiIndex columns by mistake.
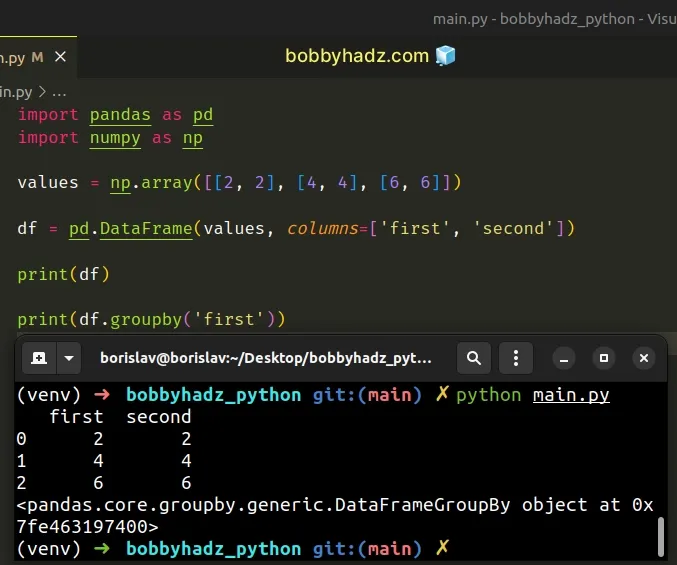
import pandas as pd import numpy as np values = np.array([[2, 2], [4, 4], [6, 6]]) df = pd.DataFrame(values, columns=[['first', 'second']]) print(df) # ⛔️ ValueError: Grouper for 'first' not 1-dimensional print(df.groupby('first'))
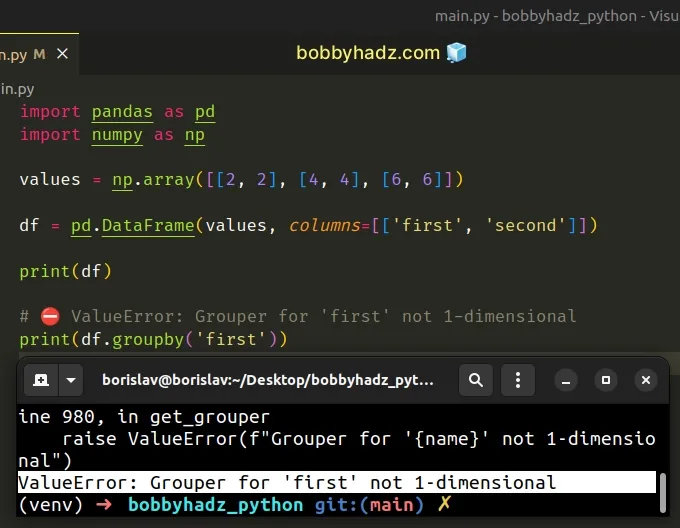
Notice that we used 2 sets of square brackets for the
columns argument when
instantiating the pandas.DataFrame() class.
Instead, only use one set of square brackets to not create MultiIndex columns.
import pandas as pd import numpy as np values = np.array([[2, 2], [4, 4], [6, 6]]) # 👇️ not creating MultiIndex columns df = pd.DataFrame(values, columns=['first', 'second']) print(df) print(df.groupby('first'))
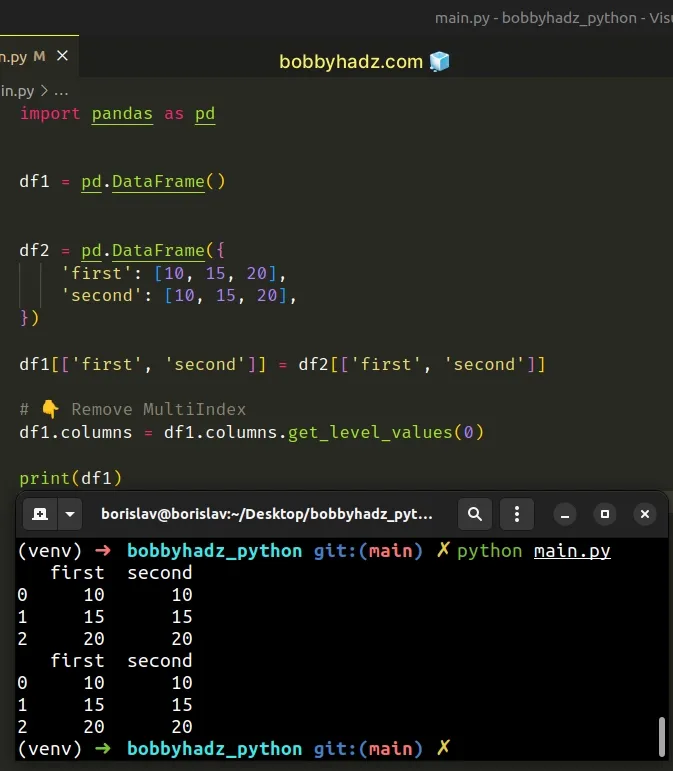
You can also use the DataFrame.columns.get_level_values() method to remove the
MultiIndex.
import pandas as pd df1 = pd.DataFrame() df2 = pd.DataFrame({ 'first': [10, 15, 20], 'second': [10, 15, 20], }) df1[['first', 'second']] = df2[['first', 'second']] # 👇️ Remove MultiIndex df1.columns = df1.columns.get_level_values(0) print(df1)
# Calling pandas.pivot_table() incorrectly
The error also occurs when you call the pandas.pivot_table method incorrectly.
Here is an example.
import numpy as np import pandas as pd df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"], "B": ["one", "one", "one", "two", "two", "one", "one", "two", "two"], "C": ["small", "large", "large", "small", "small", "large", "small", "small", "large"], "D": [1, 2, 2, 3, 3, 4, 5, 6, 7], "E": [2, 4, 5, 5, 6, 6, 8, 9, 9]}) table = pd.pivot_table(df, values='C', index=['A', 'B'], columns=['C'], aggfunc=np.sum) # ⛔️ ValueError: Grouper for 'C' not 1-dimensional print(table)
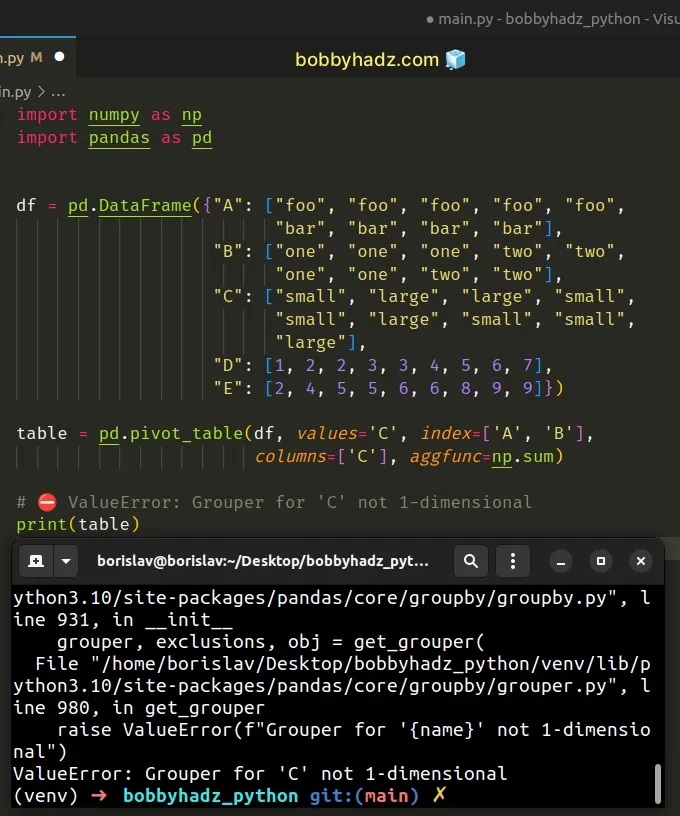
Notice that we have the C column in values and columns which caused the
error.
The column cannot be in both values and columns.
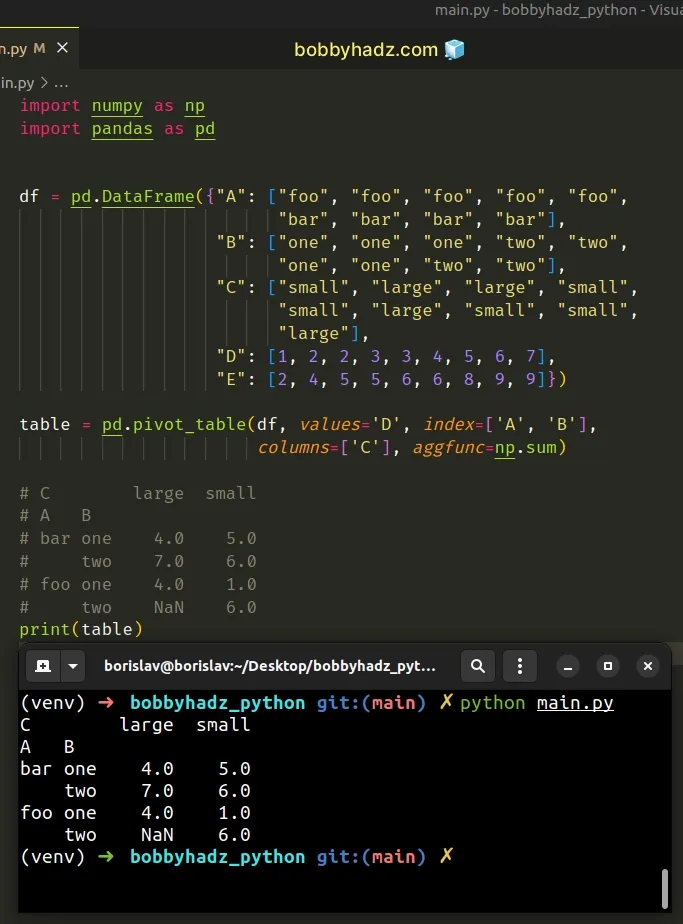
import numpy as np import pandas as pd df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"], "B": ["one", "one", "one", "two", "two", "one", "one", "two", "two"], "C": ["small", "large", "large", "small", "small", "large", "small", "small", "large"], "D": [1, 2, 2, 3, 3, 4, 5, 6, 7], "E": [2, 4, 5, 5, 6, 6, 8, 9, 9]}) table = pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) # C large small # A B # bar one 4.0 5.0 # two 7.0 6.0 # foo one 4.0 1.0 # two NaN 6.0 print(table)
Also, make sure to call the pivot_table method on the pandas module and not
the DataFrame object.
The following is correct.
# ✅ Correct import pandas as pd import numpy as np table = pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum)
And the following is incorrect.
# ⛔️ Incorrect. Calling pivot_table on `df` table = df.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum)
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

