Pandas: Drop columns if Name contains a given String
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Pandas: Drop columns if Name contains a given String
- Pandas: Drop columns if Name contains one of multiple Strings
- Drop columns if Name contains a given string using str.contains()
- Drop columns if Name contains a given string in a case-insensitive manner
- Keeping only the columns whose name contains a given string
# Pandas: Drop columns if Name contains a given String
To drop the columns in a DataFrame whose name contains a given string:
- Call the
drop()method on theDataFrame. - Filter the columns by name using the
regexparameter. - Drop the columns in place.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'last_name': ['Smith', 'Hadz', 'Lemon'], 'salary': [175.1, 180.2, 190.3], 'experience': [5, 10, 15] }) print(df) print('-' * 50) df.drop(list(df.filter(regex='name')), axis=1, inplace=True) print(df)
Running the code sample produces the following output.
first_name last_name salary experience 0 Alice Smith 175.1 5 1 Bobby Hadz 180.2 10 2 Carl Lemon 190.3 15 -------------------------------------------------- salary experience 0 175.1 5 1 180.2 10 2 190.3 15
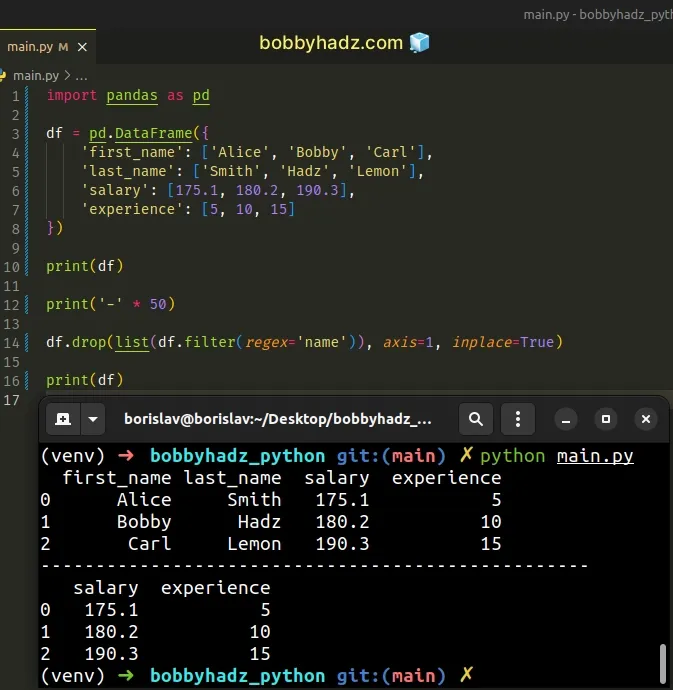
We used the
DataFrame.filter
method to select all DataFrame columns that contain the string "name".
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'last_name': ['Smith', 'Hadz', 'Lemon'], 'salary': [175.1, 180.2, 190.3], 'experience': [5, 10, 15] }) # first_name last_name # 0 Alice Smith # 1 Bobby Hadz # 2 Carl Lemon print(df.filter(regex='name')) # ['first_name', 'last_name'] print(list(df.filter(regex='name')))
Once you select the matching DataFrame columns, you can get their names by
using the list class.
The DataFrame.drop() method is then used to drop the columns based on their labels.
df.drop(list(df.filter(regex='name')), axis=1, inplace=True)
axis argument is set to 1 so that the drop() method drops labels from the columns.When the inplace argument is set to True, the columns are dropped from the
original DataFrame in place and None is returned.
# Pandas: Drop columns if Name contains one of multiple Strings
The same approach can be used to drop the columns of a DataFrame whose name
contains at least one of multiple strings.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'last_name': ['Smith', 'Hadz', 'Lemon'], 'salary': [175.1, 180.2, 190.3], 'experience': [5, 10, 15] }) print(df) print('-' * 50) df.drop(list(df.filter(regex='name|salary')), axis=1, inplace=True) print(df)
Running the code sample produces the following output.
first_name last_name salary experience 0 Alice Smith 175.1 5 1 Bobby Hadz 180.2 10 2 Carl Lemon 190.3 15 -------------------------------------------------- experience 0 5 1 10 2 15
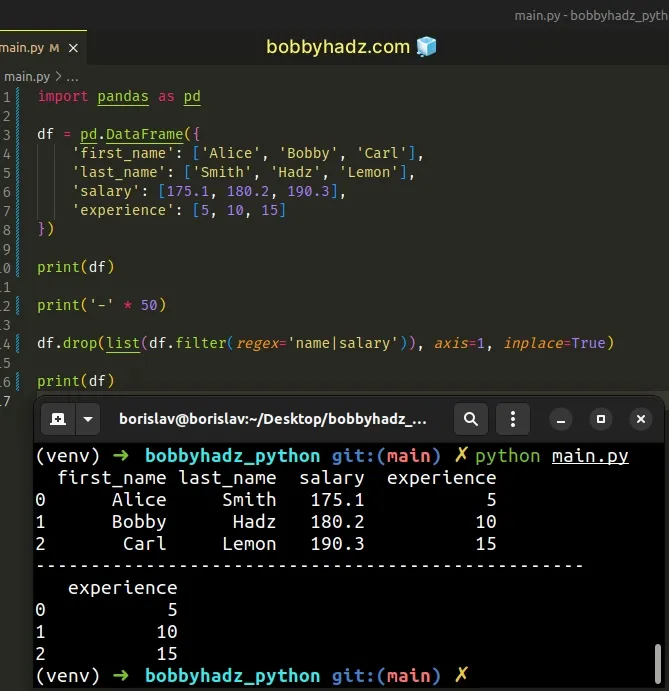
Notice that we used the pipe | character in the regular expression.
The example drops the DataFrame columns whose name contains the strings
"name" or "salary".
df.drop(list(df.filter(regex='name|salary')), axis=1, inplace=True)
The format for the regular expression is "A|B|C" where A or B or C is
matched.
In other words, the column is removed if it contains "A" or "B" or "C".
You can use the pipe | character to separate as many strings as necessary.
# Drop columns if Name contains a given string using str.contains()
You can also use the str.contains method to drop the columns whose name contains a given string.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'last_name': ['Smith', 'Hadz', 'Lemon'], 'salary': [175.1, 180.2, 190.3], 'experience': [5, 10, 15] }) print(df) bool_list = df.columns.str.contains('name') print('-' * 50) print(bool_list) df = df.loc[:, ~df.columns.str.contains('name')] print('-' * 50) print(df)
Running the code sample produces the following output.
first_name last_name salary experience 0 Alice Smith 175.1 5 1 Bobby Hadz 180.2 10 2 Carl Lemon 190.3 15 -------------------------------------------------- [ True True False False] -------------------------------------------------- salary experience 0 175.1 5 1 180.2 10 2 190.3 15
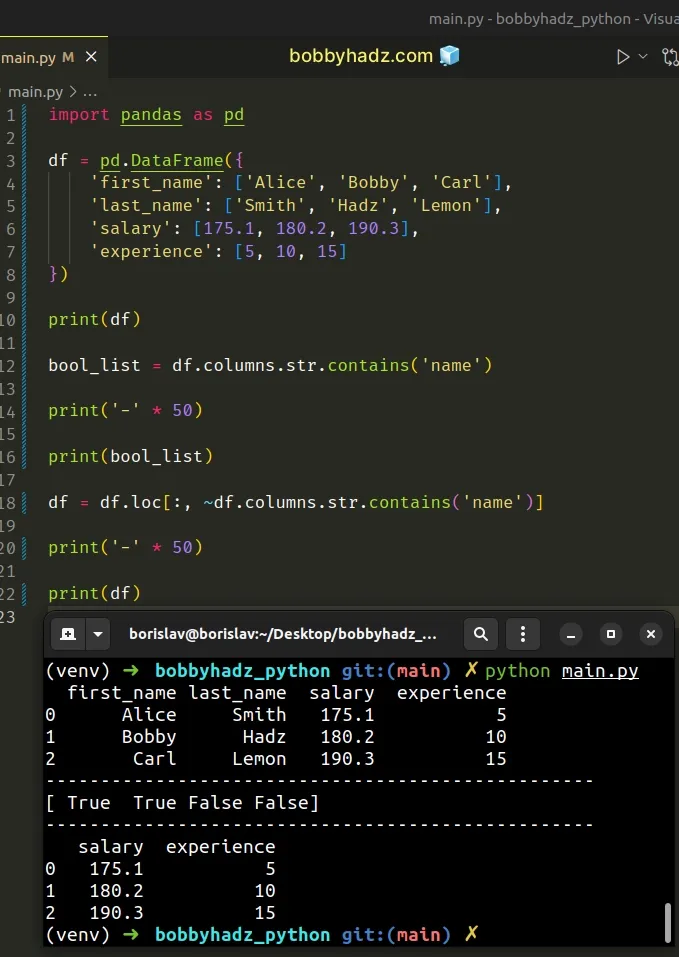
We used the df.loc indexer to access the group of columns by a boolean list.
# 👇️ [ True True False False] bool_list = df.columns.str.contains('name') df = df.loc[:, ~df.columns.str.contains('name')]
The boolean list stores a True value for each column whose name contains the
given string.
The str.contains() method tests if a pattern or a regular expression is
contained within a string.
# Drop columns if Name contains a given string in a case-insensitive manner
If you need to drop the columns whose name contains a given string in a
case-insensitive manner, set the case argument to False.
import pandas as pd df = pd.DataFrame({ 'FIRST_NAME': ['Alice', 'Bobby', 'Carl'], 'last_name': ['Smith', 'Hadz', 'Lemon'], 'salary': [175.1, 180.2, 190.3], 'experience': [5, 10, 15] }) print(df) bool_list = df.columns.str.contains('name', case=False) print('-' * 50) print(bool_list) df = df.loc[:, ~df.columns.str.contains('name', case=False)] print('-' * 50) print(df)
Running the code sample produces the following output.
FIRST_NAME last_name salary experience 0 Alice Smith 175.1 5 1 Bobby Hadz 180.2 10 2 Carl Lemon 190.3 15 -------------------------------------------------- [ True True False False] -------------------------------------------------- salary experience 0 175.1 5 1 180.2 10 2 190.3 15
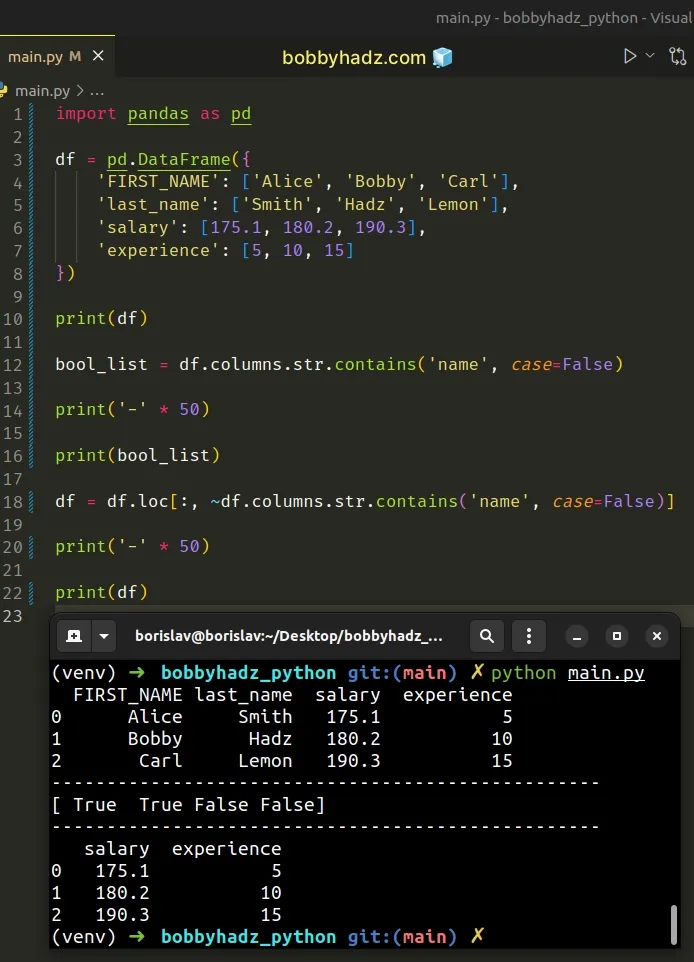
Notice that we set the case argument to False when calling str.contains().
bool_list = df.columns.str.contains('name', case=False) df = df.loc[:, ~df.columns.str.contains('name', case=False)]
When the case argument is set to False, the method checks if the pattern is
contained within the string in a case-insensitive manner.
By default, the case argument is set to True.
# Keeping only the columns whose name contains a given string
If you only want to keep the DataFrame columns whose name contains a given
string, use the DataFrame.filter() method.
import pandas as pd df = pd.DataFrame({ 'first_name': ['Alice', 'Bobby', 'Carl'], 'last_name': ['Smith', 'Hadz', 'Lemon'], 'salary': [175.1, 180.2, 190.3], 'experience': [5, 10, 15] }) print(df) df = df.filter(like='name', axis=1) print('-' * 50) print(df)
Running the code sample produces the following output.
first_name last_name salary experience 0 Alice Smith 175.1 5 1 Bobby Hadz 180.2 10 2 Carl Lemon 190.3 15 -------------------------------------------------- first_name last_name 0 Alice Smith 1 Bobby Hadz 2 Carl Lemon
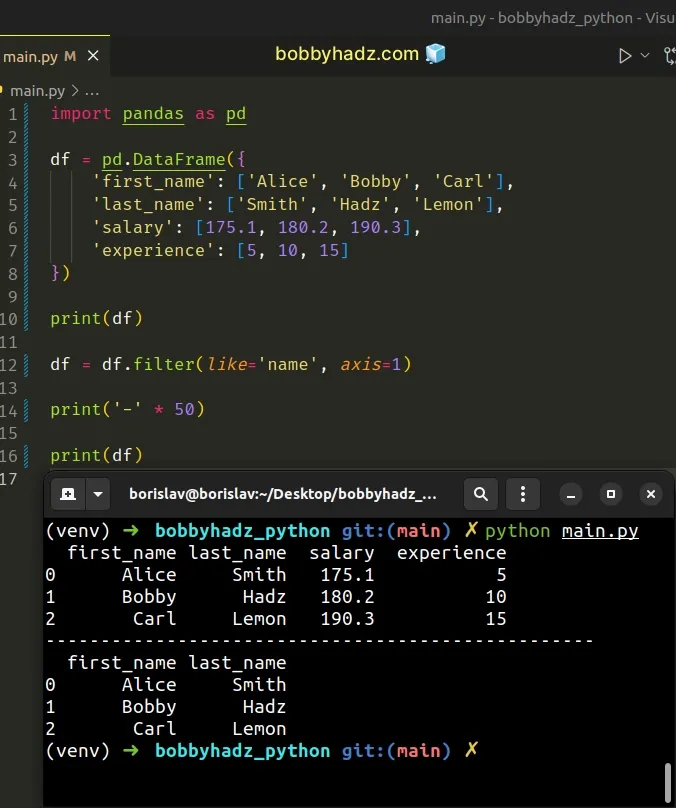
We set the like argument to a string that we want to check for.
df = df.filter(like='name', axis=1)
The method call keeps the labels from the column axis for which the column name
contains the given string (like in label == True).
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Boolean index did not match indexed array along dimension 0
- AttributeError: Can only use .dt accessor with datetimelike values
- Replace whole String if it contains Substring in Pandas
- Pandas: Create new row for each element in List in DataFrame
- ValueError: Length of values does not match length of index
- Get the first Row of each Group in a Pandas DataFrame
- Convert Epoch to Datetime in a Pandas DataFrame
- Calculate the Average for each Row in a Pandas DataFrame
- How to drop all Rows in a Pandas DataFrame in Python
- Pandas: Drop columns if Name contains a given String
- How to repeat Rows N times in a Pandas DataFrame
- How to convert a Pandas DataFrame to a Markdown Table
- How to convert a Pandas DataFrame to a Markdown Table
- Pandas: Convert GroupBy results to Dictionary of Lists
- Pandas: How to get the Max and Min Dates in a DataFrame
- Pandas: Select the Rows where two Columns are Equal
- First argument must be an iterable of pandas objects [Fix]
- ValueError: Index contains duplicate entries, cannot reshape
- Pandas: How to Convert a Pivot Table to a DataFrame
- Pandas: Count the unique combinations of two Columns
- Pandas: Find the closest value to a Number in a Column
- Pandas: Create a Tuple from two DataFrame Columns

