Pandas: Setting column names when reading a CSV file
Last updated: Apr 12, 2024
Reading time·3 min

# Table of Contents
- Pandas: Setting column names when reading a CSV file
- If your .csv file contains column names, set the header argument to 0
- If you have a large .csv file, set the nrows argument
# Pandas: Setting column names when reading a CSV file
Use the names parameter of the pandas.read_csv() method to set the column
names when reading a CSV file into a Pandas DataFrame.
The names parameter is used to specify the column names that should be used
in the DataFrame.
For example, suppose that we have the following employees.csv file.
Alice,Smith,500 Bob,Smith,600 Carl,Smith,400
Here is how we can set the column names when reading the employees.csv file.
import pandas as pd column_names = ['first_name', 'last_name', 'salary'] df = pd.read_csv( 'employees.csv', names=column_names, header=None ) # first_name last_name salary # 0 Alice Smith 500 # 1 Bob Smith 600 # 2 Carl Smith 400 print(df)
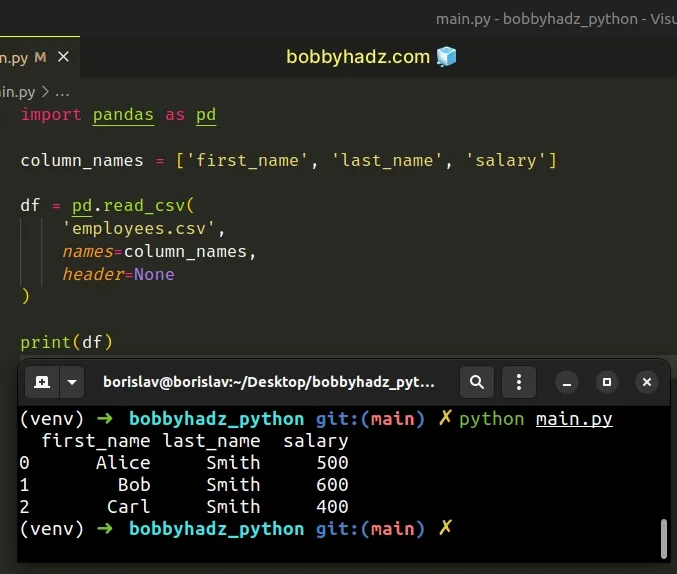
The pandas.read_csv()
method reads a comma-separated values (CSV) file into a DataFrame.
We passed the following arguments to the method:
filepath- The path to the.csvfile that we want to read into aDataFrame.names- A list containing the names of the columns that should be used when constructing theDataFrame.header- set toNoneto use the specified column names.
When the names argument is set to a list of columns, the header parameter
defaults to None.
Therefore the following code sample is equivalent.
import pandas as pd column_names = ['first_name', 'last_name', 'salary'] df = pd.read_csv( 'employees.csv', names=column_names, ) # first_name last_name salary # 0 Alice Smith 500 # 1 Bob Smith 600 # 2 Carl Smith 400 print(df)
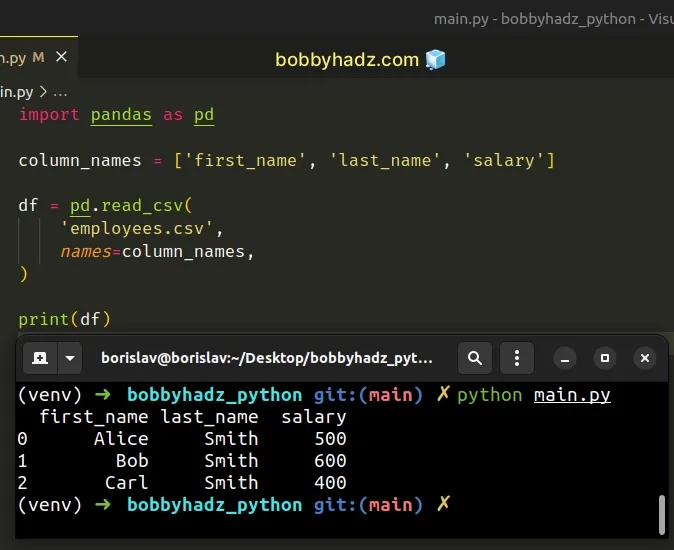
As shown in the code sample, the header parameter defaults to None when the
names argument is set to a list of column names.
# If your .csv file contains column names, set the header argument to 0
If your .csv file contains column names that you don't want to use, set the
header argument to 0.
For example, suppose that we have the following employees.csv file.
first,last,salary Alice,Smith,500 Bob,Smith,600 Carl,Smith,400
Here is how we can replace the original column names with our own.
import pandas as pd column_names = ['first_name', 'last_name', 'salary'] df = pd.read_csv( 'employees.csv', names=column_names, header=0, ) # first_name last_name salary # 0 Alice Smith 500 # 1 Bob Smith 600 # 2 Carl Smith 400 print(df)
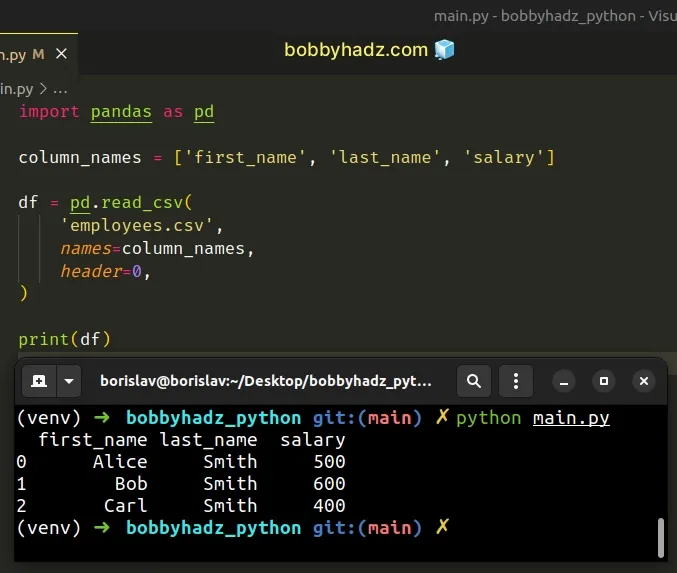
Explicitly setting the header argument to 0 enables us to replace the
existing column names.
Setting the header parameter to 0 should only be done when the first row in
your csv file contains column names that you want to replace.
Otherwise, you'd skip the first row of values.
# If you have a large .csv file, set the nrows argument
If you're working with a large .csv file, set the nrows argument to avoid
loading the entire file in memory.
Suppose we have the following employees.csv file.
Alice,Smith,500 Bob,Smith,600 Carl,Smith,400
And here is an example that loads only the first 2 rows of the .csv file.
import pandas as pd column_names = ['first_name', 'last_name', 'salary'] df = pd.read_csv( 'employees.csv', names=column_names, nrows=2 ) # first_name last_name salary # 0 Alice Smith 500 # 1 Bob Smith 600 print(df)
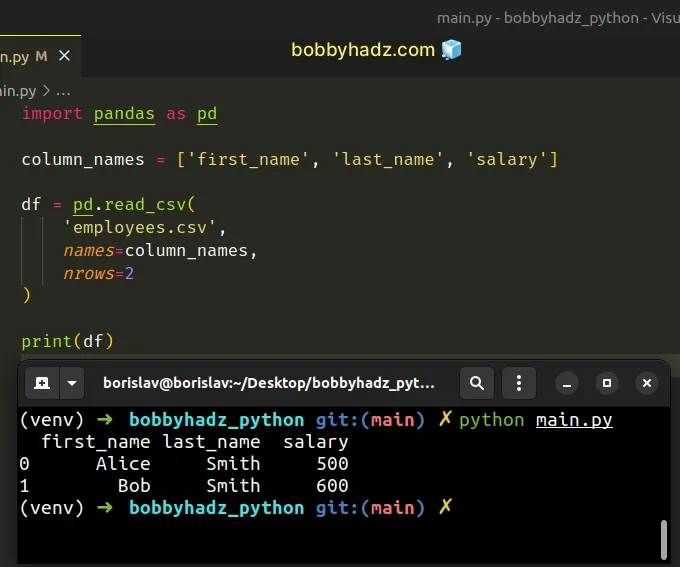
The nrows argument is an integer that represents the number of rows of the
file to read.
Setting the argument is useful when reading pieces of large .csv files.
I've also written an article on how to skip the header of a file with CSV reader in Python.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

