Export a Pandas DataFrame to Excel without the Index
Last updated: Apr 12, 2024
Reading time·3 min

# Table of Contents
- Export a Pandas DataFrame to Excel without the Index
- Exporting the DataFrame to Excel without the index using pd.ExcelWriter
# Export a Pandas DataFrame to Excel without the Index
To export a Pandas DataFrame to Excel without the index:
- Use the
DataFrame.to_excel()method to write theDataFrameobject to an Excel sheet. - Set the
indexargument toFalsewhen callingto_excel(). - When the
indexargument isFalse, the row names (index) won't be written to the file.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)
Running the code sample produces the following output.xlsx file in the same
directory.
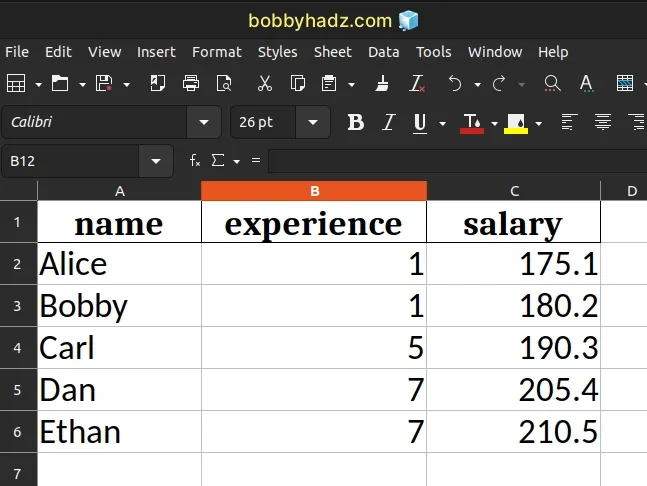
Notice that the file doesn't have a column with the indices of the DataFrame.
If you remove the index argument from the call to
DataFrame.to_excel(),
it defaults to True, which means that a column containing the indices is
produced.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) df.to_excel('output.xlsx', sheet_name='Sheet1')
And here is the output.xlsx file.
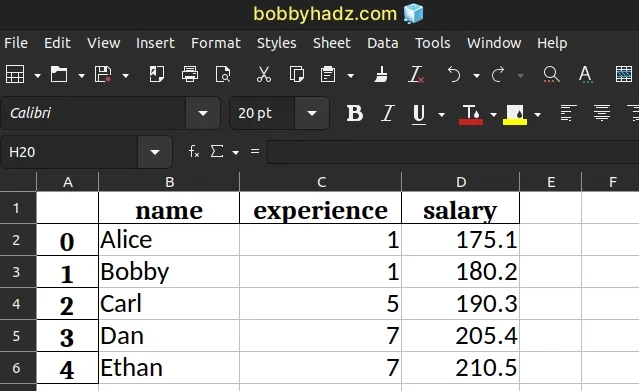
The index argument defaults to True.
The argument determines whether the row names (indices) are written to a column in the Excel file.
# Exporting the DataFrame to Excel without the index using pd.ExcelWriter
The same can be achieved if you use the pandas.ExcelWriter class.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) with pd.ExcelWriter('output.xlsx') as writer: df.to_excel(writer, sheet_name='Sheet1', index=False)
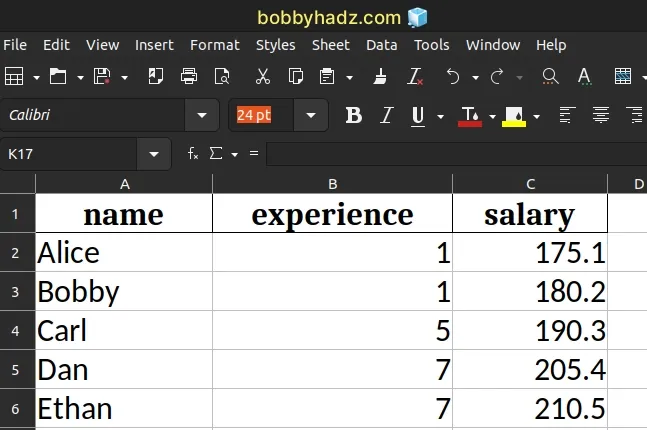
And here is the output.xlsx file.
The pandas.ExcelWriter class can be used as a context manager.
The class enables us to write DataFrame objects into Excel sheets.
xls, xlsx or ods file.Make sure your call to df.to_excel() is
indented correctly.
When using the pandas.ExcelWriter() class as a context manager, it
automatically takes care of closing the Excel file after you are done writing.
However, you don't necessarily have to use the pandas.ExcelWriter class as a
context manager.
Here is an example.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) writer = pd.ExcelWriter('output.xlsx') df.to_excel(writer, sheet_name='Sheet1', index=False) writer.save()
The writer.save() method closes the file object so you don't have any memory
leaks.
The method should only be used after you are done writing to the file.
There is also an ExcelWriter.close method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan', 'Ethan'], 'experience': [1, 1, 5, 7, 7], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) writer = pd.ExcelWriter('output.xlsx') df.to_excel(writer, sheet_name='Sheet1', index=False) writer.close()
The close method is a synonym for save.
When manually opening the Excel file for writing, make sure to close it, otherwise, you'd get a memory leak.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: GroupBy columns with NaN (missing) values
- Pandas: Split a Column of Lists into Multiple Columns
- Matplotlib: No artists with labels found to put in legend
- All the input arrays must have same number of dimensions
- ValueError: Index contains duplicate entries, cannot reshape
- Pandas: Set number of max Rows and Cols shown in DataFrame

