ValueError: Columns must be same length as key [Solved]
Last updated: Apr 11, 2024
Reading time·4 min

# ValueError: Columns must be same length as key [Solved]
The Pandas "ValueError: Columns must be same length as key" occurs when the
columns you are trying to assign to the DataFrame are not equal to the number
of keys you've specified.
To solve the error, make sure the number of keys you've specified is equal to the number of values (columns).
Here is an example of how the error occurs.
import pandas as pd df1 = pd.DataFrame({ 'column1': ['Alice', 'Bobby', 'Carl', 'Dan'], 'column2': [29, 30, 31, 32] }) df2 = pd.DataFrame({ 'column1': [100, 200, 300] }) # ⛔️ ValueError: Columns must be same length as key df1[['column3', 'column4']] = df2['column1']
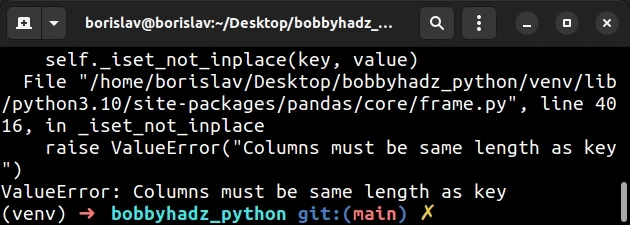
The error occurred when trying to add 2 keys to the first DataFrame object.
Notice that there are 2 keys (column3 and column4) between the square
brackets, however, column1 in df2 contains 3 items.
The mismatch between the number of keys (column3 and column4) and the number
of values (100, 200 and 300) caused the error.
To solve the error, you have to make sure the number of keys on the left matches the number of values on the right.
import pandas as pd df1 = pd.DataFrame({ 'column1': ['Alice', 'Bobby', 'Carl', 'Dan'], 'column2': [29, 30, 31, 32] }) df2 = pd.DataFrame({ 'column1': [100, 200, 300] }) df1[['column3', 'column4', 'column5']] = df2['column1'] print(df1)
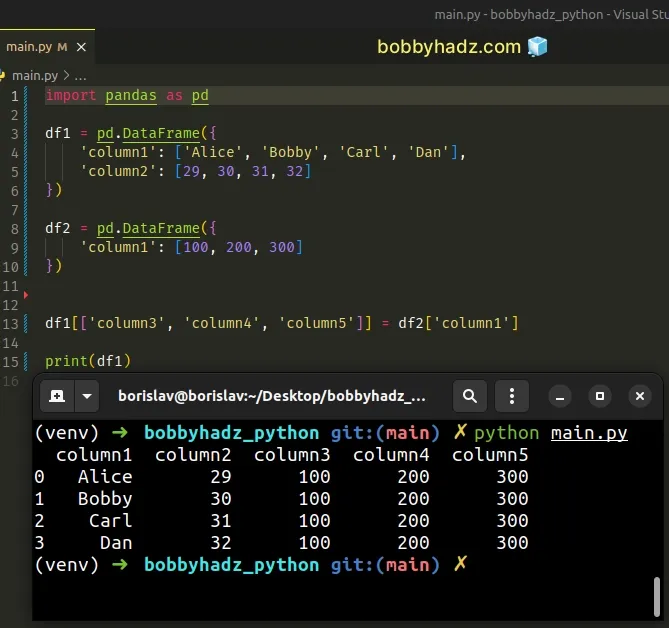
Running the code sample produces a DataFrame with the following output.
column1 column2 column3 column4 column5 0 Alice 29 100 200 300 1 Bobby 30 100 200 300 2 Carl 31 100 200 300 3 Dan 32 100 200 300
Notice that we passed 3 keys (column3, column4 and column5) because
column1 in df contains 3 values.
We added a third key to resolve the issue, however, you could've also removed one of the values on the right-hand side.
import pandas as pd df1 = pd.DataFrame({ 'column1': ['Alice', 'Bobby', 'Carl', 'Dan'], 'column2': [29, 30, 31, 32] }) df2 = pd.DataFrame({ 'column1': [100, 200] }) df1[['column3', 'column4']] = df2['column1'] print(df1)
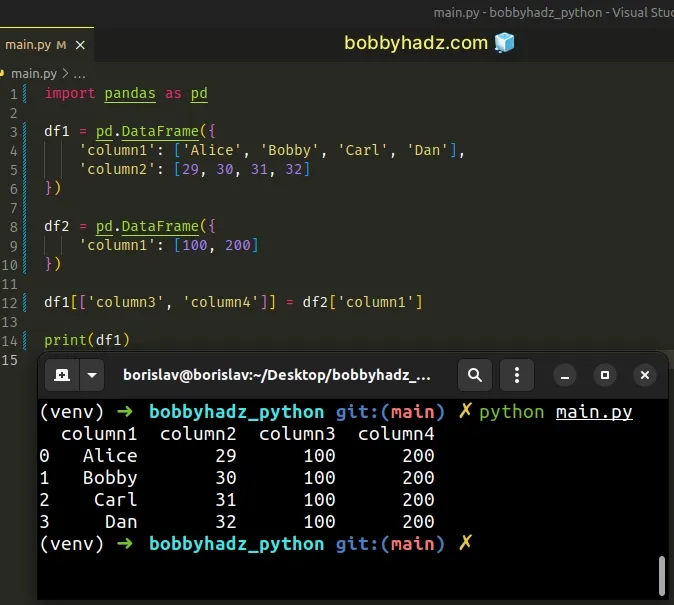
Running the code sample above produces the following DataFrame.
column1 column2 column3 column4 0 Alice 29 100 200 1 Bobby 30 100 200 2 Carl 31 100 200 3 Dan 32 100 200
If you meant to copy a column from one DataFrame to another, use the following code sample instead.
import pandas as pd df1 = pd.DataFrame({ 'column1': ['Alice', 'Bobby', 'Carl', 'Dan'], 'column2': [29, 30, 31, 32] }) df2 = pd.DataFrame({ 'column1': [100, 200, 300] }) df1['column3'] = df2['column1'] # column1 column2 column3 # 0 Alice 29 100.0 # 1 Bobby 30 200.0 # 2 Carl 31 300.0 # 3 Dan 32 NaN print(df1)
The column in the second DataFrame only has 3 values, so the fourth row gets
set to a value of NaN.
# Solving the error when using pandas.Series.str.split()
Here is an example that solves the error when using pandas.Series.str.split.
import pandas as pd df1 = pd.DataFrame({ 'column1': ['Alice', 'Bobby', 'Carl', 'Dan'], 'column2': [29, 30, 31, 32] }) df2 = pd.DataFrame({ 'column1': ['1. AB', '2. CD', '3. EF'] }) df1[['column3', 'column4']] = df2['column1'].str.split( '.', n=1, expand=True, regex=False) print(df1)
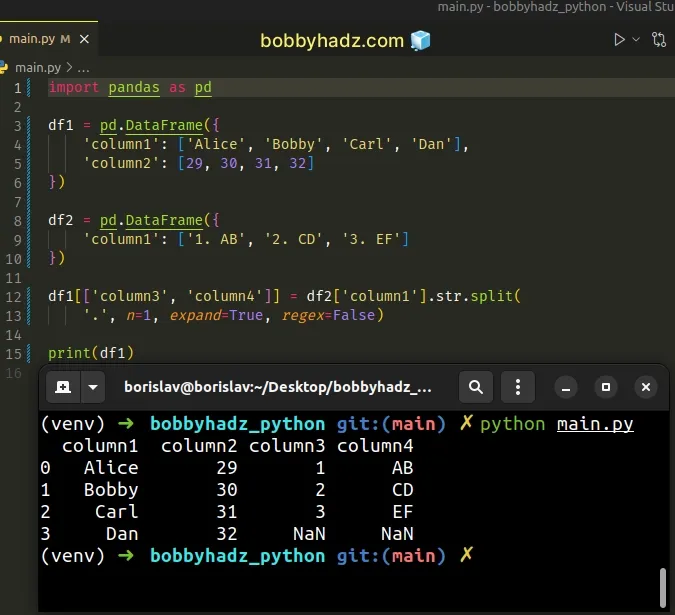
Running the code sample produces the following output.
column1 column2 column3 column4 0 Alice 29 1 AB 1 Bobby 30 2 CD 2 Carl 31 3 EF 3 Dan 32 NaN NaN
The pandas.Series.str.split() method splits strings around a given separator.
import pandas as pd df2 = pd.DataFrame({ 'column1': ['1. AB', '2. CD', '3. EF'] }) # 0 1 # 0 1 AB # 1 2 CD # 2 3 EF print(df2['column1'].str.split('.', n=1, expand=True, regex=False))
The first argument we passed to the method is the separator to split on.
If not specified, the method splits on whitespace.
The n argument is the number of splits.
If you set the argument to None, 0 or -1, all splits are returned.
The expand argument is used to expand the split strings into separate columns.
The regex argument determines if the supplied pattern is a regular expression
or a string literal.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Copy a column from one DataFrame to another in Pandas
- ValueError: cannot reindex on an axis with duplicate labels
- AttributeError module 'pandas' has no attribute 'DataFrame'
- ModuleNotFoundError: No module named 'pandas' in Python
- FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version
- TypeError Invalid comparison between datetime64[ns] and date
- How to change the Port and Host in a Flask application
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- Object arrays cannot be loaded when allow_pickle=False
- How to clear the Terminal and Console in PyCharm
- ufunc 'add' did not contain loop with signature matching types
- TypeError: Field elements must be 2- or 3-tuples, got 1
- ValueError: Expected 2D array, got 1D array instead [Fixed]
- Input contains infinity or value too large for dtype(float64)
- Drop Unnamed: 0 columns from a Pandas DataFrame in Python
- Get the first Row of each Group in a Pandas DataFrame
- ValueError: Expected object or value with
pd.read_json()

