Reindexing only valid with uniquely valued Index objects
Last updated: Apr 12, 2024
Reading time·5 min

# Table of Contents
- Reindexing only valid with uniquely valued Index objects
- Using the
reset_index()method to reset the index of eachDataFrame - Removing the rows with duplicate indices
- The error also occurs when you have duplicate column names
- Removing the duplicate columns before calling pd.concat()
# Reindexing only valid with uniquely valued Index objects
The "pandas.errors.InvalidIndexError: Reindexing only valid with uniquely valued Index objects" occurs for 2 main reasons:
- When your index contains duplicate values before calling
pandas.concat().
In this case, you have to use the DataFrame.reset_index() method to resolve
it.
- When you have duplicate column names before calling
pandas.concat().
Here is an example of how the error occurs.
import pandas as pd df1 = pd.DataFrame(index=[1, 0, 1], columns=['A'], data=[1, 2, 3]) df2 = pd.DataFrame(index=[0, 1, 1], columns=['B'], data=[4, 5, 6]) df1 = df1.reset_index() df2 = df2.reset_index() # ⛔️ pandas.errors.InvalidIndexError: Reindexing only valid with uniquely valued Index objects df3 = pd.concat([df1, df2], axis=1) print(df3)
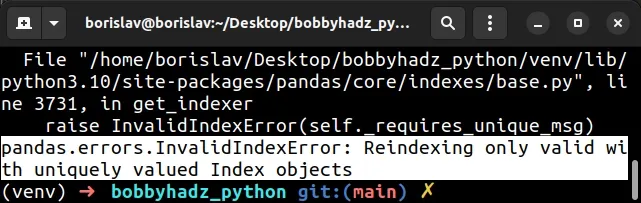
Notice that the index lists of the DataFrames contain duplicates.
You can also verify that this is the case by accessing the index.is_unique attribute.
import pandas as pd df1 = pd.DataFrame(index=[1, 0, 1], columns=['A'], data=[1, 2, 3]) print(df1.index.is_unique) # 👉️ False df2 = pd.DataFrame(index=[0, 1, 1], columns=['B'], data=[4, 5, 6]) print(df2.index.is_unique) # 👉️ False
The index.is_unique attribute returns True if the index has unique values
and False otherwise.
# Using the reset_index() method to reset the index of each DataFrame
One way to solve the error is to use the DataFrame.reset_index() method.
import pandas as pd df1 = pd.DataFrame(index=[1, 0, 1], columns=['A'], data=[1, 2, 3]) df2 = pd.DataFrame(index=[0, 1, 1], columns=['B'], data=[4, 5, 6]) df1 = df1.reset_index() df2 = df2.reset_index() df3 = pd.concat([df1, df2], axis=1) # index A index B # 0 1 1 0 4 # 1 0 2 1 5 # 2 1 3 1 6 print(df3)
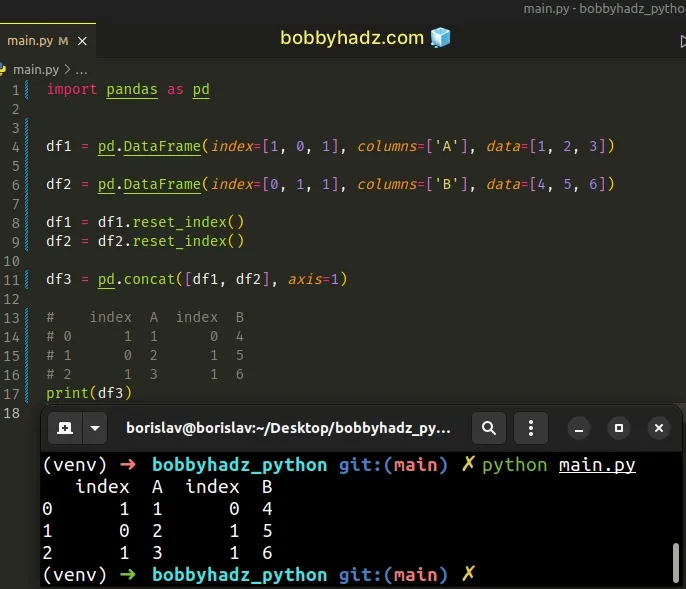
By default, the method keeps the old index as a column in the new DataFrame.
However, you can change this behavior by setting the drop argument to True
when calling reset_index().
import pandas as pd df1 = pd.DataFrame(index=[1, 0, 1], columns=['A'], data=[1, 2, 3]) df2 = pd.DataFrame(index=[0, 1, 1], columns=['B'], data=[4, 5, 6]) df1 = df1.reset_index(drop=True) df2 = df2.reset_index(drop=True) df3 = pd.concat([df1, df2], axis=1) # A B # 0 1 4 # 1 2 5 # 2 3 6 print(df3)
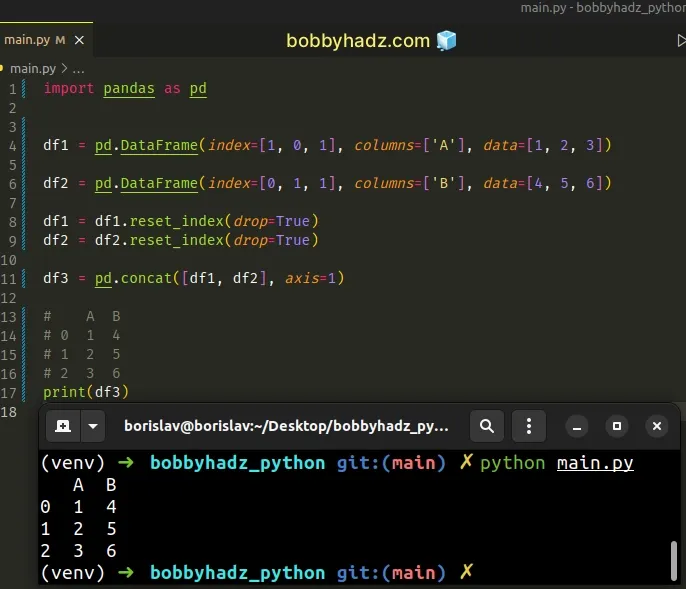
When the drop argument is set to True, the index is reset to the default
integer index.
The argument defaults to False.
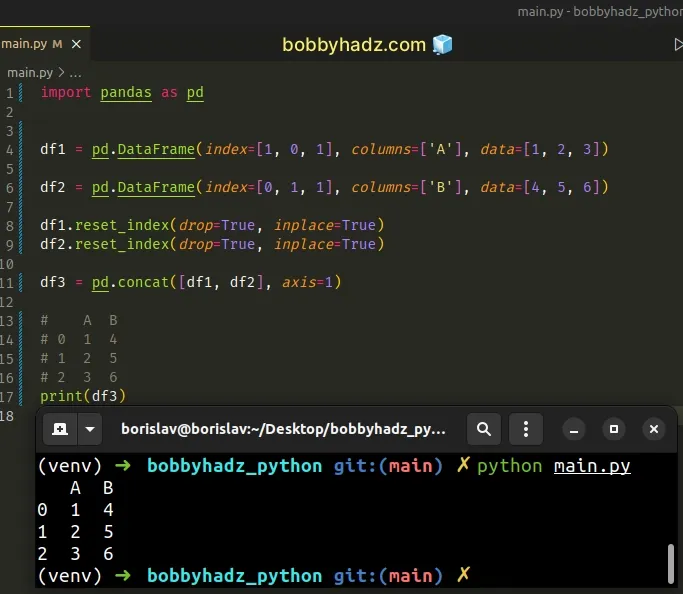
If you want to avoid reassigning the variables, set the inplace argument to
True.
import pandas as pd df1 = pd.DataFrame(index=[1, 0, 1], columns=['A'], data=[1, 2, 3]) df2 = pd.DataFrame(index=[0, 1, 1], columns=['B'], data=[4, 5, 6]) df1.reset_index(drop=True, inplace=True) df2.reset_index(drop=True, inplace=True) df3 = pd.concat([df1, df2], axis=1) # A B # 0 1 4 # 1 2 5 # 2 3 6 print(df3)
The pandas.concat() method requires that the indices and column names be
unique.
# Removing the rows with duplicate indices
If you'd rather just
remove the rows with duplicate indices,
use the df.loc label-based indexer with df.index.duplicated().
import pandas as pd df1 = pd.DataFrame(index=[1, 0, 1], columns=['A'], data=[1, 2, 3]) df2 = pd.DataFrame(index=[0, 1, 1], columns=['B'], data=[4, 5, 6]) df1 = df1.loc[~df1.index.duplicated(keep='first')] df2 = df2.loc[~df2.index.duplicated(keep='first')] df3 = pd.concat([df1, df2], axis=1) # A B # 0 1 4 # 1 2 5 # 2 3 6 print(df3)
We used the index.duplicated() method to get an array containing the duplicate index values.
The expression then removes the rows with duplicate indices.
# The error also occurs when you have duplicate column names
The error also occurs if you have duplicate column names.
Here is an example.
import pandas as pd df1 = pd.DataFrame([[1, 2, 3]], columns=['A', 'A', 'C']) df2 = pd.DataFrame([[4, 5, 6]], columns=['A', 'B', 'C']) # # ⛔️ pandas.errors.InvalidIndexError: Reindexing only valid with uniquely valued Index objects df3 = pd.concat([df1, df2])
Notice that the first DataFrame has duplicate column names (A * 2).
The concat() method doesn't know which of the two columns with a value of
"A" from the first DataFrame should be aligned with the "A" column from
the second DataFrame.
One way to solve the error is to pass unique column names when instantiating the
DataFrame.
import pandas as pd df1 = pd.DataFrame([[1, 2, 3]], columns=['A', 'B', 'C']) df2 = pd.DataFrame([[4, 5, 6]], columns=['A', 'B', 'C']) df3 = pd.concat([df1, df2]) # A B C # 0 1 2 3 # 0 4 5 6 print(df3)
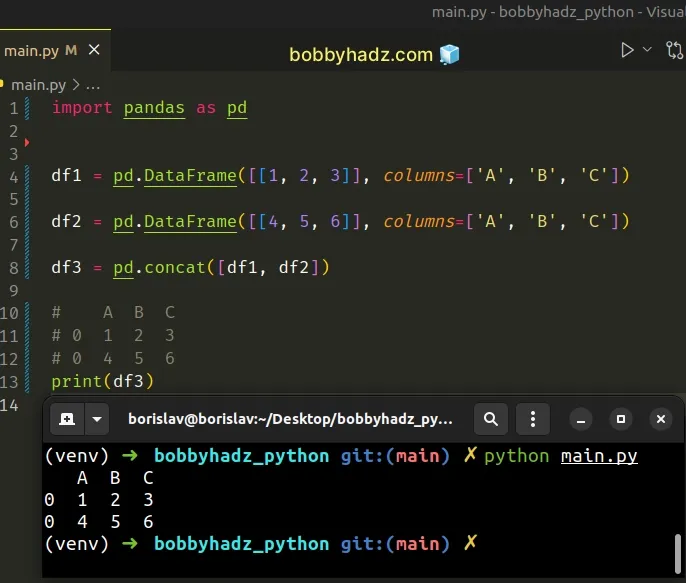
We passed unique column names to pd.DataFrame(), so everything works as
expected.
If you need to find the duplicate columns in your DataFrame, use the
columns.duplicated() method.
import pandas as pd df1 = pd.DataFrame([[1, 2, 3]], columns=['A', 'A', 'C']) # 👇️ Index(['A', 'A'], dtype='object') print(df1.columns[df1.columns.duplicated(keep=False)]) df2 = pd.DataFrame([[4, 5, 6]], columns=['A', 'B', 'C']) # 👇️ Index([], dtype='object') print(df2.columns[df2.columns.duplicated(keep=False)])
As shown in the code sample, the first DataFrame has a duplicate "A" column
name, whereas the second DataFrame doesn't have any duplicate column names.
# Removing the duplicate columns before calling pd.concat()
You can also solve the error by removing the duplicate columns before calling
pd.concat().
import pandas as pd df1 = pd.DataFrame([[1, 2, 3]], columns=['A', 'A', 'C']) print(df1) print('-' * 50) df1 = df1.loc[:, ~df1.columns.duplicated()].copy() print(df1) print('-' * 50) df2 = pd.DataFrame([[4, 5, 6]], columns=['A', 'B', 'C']) df3 = pd.concat([df1, df2]) # A C B # 0 1 3 NaN # 0 4 6 5.0 print(df3)
Running the code sample produces the following output.
A A C 0 1 2 3 -------------------------------------------------- A C 0 1 3 -------------------------------------------------- A C B 0 1 3 NaN 0 4 6 5.0
We used the following line to remove the duplicate columns from the DataFrame.
df1 = df1.loc[:, ~df1.columns.duplicated()].copy()
Repeat the process if both of your DataFrames contain duplicate columns.
df1 = df1.loc[:, ~df1.columns.duplicated()].copy() df2 = df2.loc[:, ~df2.columns.duplicated()].copy()
The pandas.concat() method requires that the indices and column names be
unique.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Copy a column from one DataFrame to another in Pandas
- ValueError: cannot reindex on an axis with duplicate labels
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- ValueError: cannot reshape array of size X into shape Y
- Object arrays cannot be loaded when allow_pickle=False
- ValueError: Columns must be same length as key [Solved]
- ValueError: DataFrame constructor not properly called [Fix]
- Convert a Row to a Column Header in a Pandas DataFrame
- Drop Unnamed: 0 columns from a Pandas DataFrame in Python
- IndexError: single positional indexer is out-of-bounds [Fix]
- Select all Columns starting with a given String in Pandas
- Pandas ValueError: ('Lengths must match to compare')
- How to drop all Rows in a Pandas DataFrame in Python

