Copy a column from one DataFrame to another in Pandas
Last updated: Apr 11, 2024
Reading time·6 min

# Table of Contents
- Copy a column from one DataFrame to another in Pandas
- Copying columns from one DataFrame to another with the
copy()method - Copy columns from one DataFrame to another without NaN values
If you get NaN values when copying columns from one DataFrame to another, check out the third subheading.
# Copy a column from one DataFrame to another in Pandas
You can use bracket notation to copy a column from one DataFrame to
another.
The specified column will get copied to the new DataFrame.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }) df2['year'] = df1['year'] df2['profit'] = df1['profit'] # employees year profit # 0 10 2020 1500 # 1 15 2021 2500 # 2 20 2022 3500 # 3 25 2023 4500 print(df2)
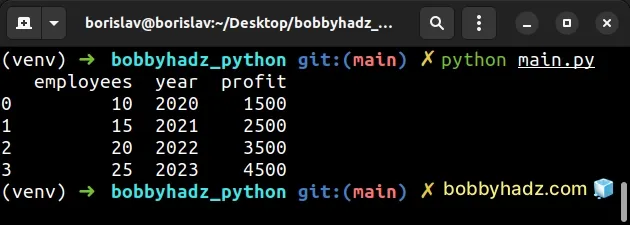
You can also copy multiple columns from one DataFrame to another in a single
statement.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }) # ✅ Copy 2 columns from one DataFrame to another df2[['year', 'profit']] = df1[['year', 'profit']] # employees year profit # 0 10 2020 1500 # 1 15 2021 2500 # 2 20 2022 3500 # 3 25 2023 4500 print(df2)
Notice that we have 2 sets of curly braces in the assignment.
The code samples use bracket notation to copy the year and profit columns
from the first DataFrame to the second.
Make sure you don't try to use dot notation, otherwise, you'll get a warning:
- "Warning: Pandas doesn't allow columns to be created via a new attribute name"
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }) # ⛔️ Warning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access df2.year = df1.year
The warning simply means that you should use bracket notation [] when copying
a column and not dot notation.
The following is incorrect:
# ⛔️ Incorrect df2.year = df1.year
The following is correct:
# ✅ Correct df2['year'] = df1['year']
# Copying columns from one DataFrame to another with the copy() method
You can also use the copy() method to copy columns from one DataFrame to
another.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], 'employees': [10, 15, 20, 25], }) columns_to_copy = df1[['year', 'profit']] df2 = columns_to_copy.copy() # year profit # 0 2020 1500 # 1 2021 2500 # 2 2022 3500 # 3 2023 4500 print(df2)

The columns_to_copy variable is a DataFrame that consists of the columns we
want to copy.
The DataFrame.copy() method makes a copy of the DataFrame's indices and data.
The method creates a deep copy of the DataFrame, so modifications to the data
or indices of the copy won't be reflected in the original DataFrame.
This is determined by the deep argument which is set to True by default.
df2 = columns_to_copy.copy(deep=True)
# Copy columns from one DataFrame to another without NaN values
When copying columns from one DataFrame to another, you might get NaN values
in the resulting DataFrame.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=[1, 2, 3, 4]) df2['year'] = df1['year'] df2['profit'] = df1['profit'] # employees year profit # 1 10 NaN NaN # 2 15 NaN NaN # 3 20 NaN NaN # 4 25 NaN NaN print(df2)
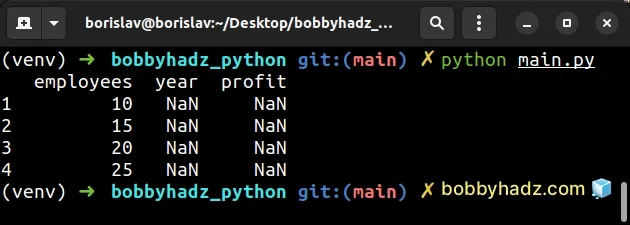
Notice that the year and profit columns contain NaN values after copying
them to the other DataFrame.
The issue is caused because the indexes of the DataFrames are different.
This causes the indexes for each column to be different.
When pandas tries to align the indexes when assigning columns to the second
DataFrame, it fails and inserts NaN values.
One way to resolve the issue is to homogenize the index values.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=[1, 2, 3, 4]) # ✅ Homogenize indexes before copying columns df2.index = df1.index df2['year'] = df1['year'] df2['profit'] = df1['profit'] # employees year profit # a 10 2020 1500 # b 15 2021 2500 # c 20 2022 3500 # d 25 2023 4500 print(df2)
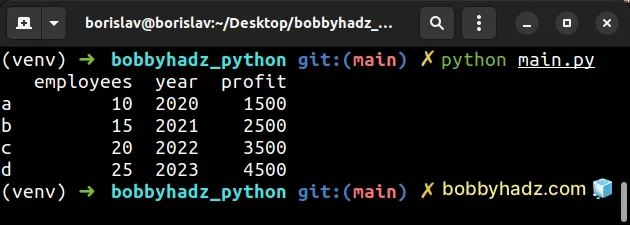
I only added the following line to the code snippet.
# ✅ Homogenize indexes before copying columns df2.index = df1.index
Once you homogenize the index values, you can copy the columns over and they
won't contain NaN values.
You can also resolve the issue by assigning NumPy arrays to the columns.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=[1, 2, 3, 4]) # ✅ call to_numpy() method df2['year'] = df1['year'].to_numpy() df2['profit'] = df1['profit'].to_numpy() # employees year profit # a 10 2020 1500 # b 15 2021 2500 # c 20 2022 3500 # d 25 2023 4500 print(df2)
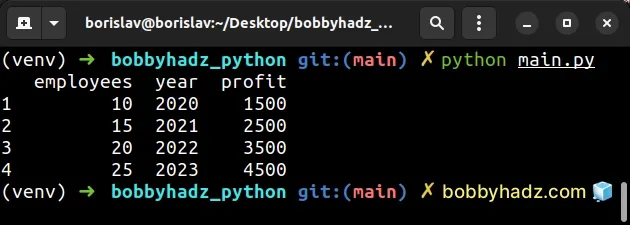
The DataFrame.to_numpy() method converts a DataFrame to a NumPy array.
Converting the columns to a NumPy array enables us to bypass the index alignment.
You can use two sets of square brackets if you need to copy multiple columns
from one DataFrame to another in a single statement.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=[1, 2, 3, 4]) df2[['year', 'profit']] = df1[['year', 'profit']].to_numpy() # employees year profit # a 10 2020 1500 # b 15 2021 2500 # c 20 2022 3500 # d 25 2023 4500 print(df2)

Notice that we used two sets of square brackets [] when specifying multiple
columns.
You can also use the values attribute when copying columns.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=[1, 2, 3, 4]) df2['year'] = df1['year'].values df2['profit'] = df1['profit'].values # employees year profit # a 10 2020 1500 # b 15 2021 2500 # c 20 2022 3500 # d 25 2023 4500 print(df2)
The
DataFrame.values
attribute returns a NumPy representation of the DataFrame.
When accessing the values attribute, only the values in the DataFrame are
returned (the axes labels are removed).
Homogenizing the indexes or converting the columns to a NumPy array to bypass index alignment is necessary because the indexes in the two DataFrames are different.
The comment in the following code sample demonstrates how there is no overlap between the indexes of the two DataFrames.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=[1, 2, 3, 4]) # df1.index df2.index # a # b # c # d # 1 # 2 # 3 # 4
The indexes of the two DataFrames are not alignable because there is no overlap.
Here is an example where the indexes partially overlap.
import pandas as pd df1 = pd.DataFrame({ 'year': [2020, 2021, 2022, 2023], 'profit': [1500, 2500, 3500, 4500], }, index=['a', 'b', 'c', 'd']) df2 = pd.DataFrame({ 'employees': [10, 15, 20, 25], }, index=['c', 'd', 'e', 'f']) df2['year'] = df1['year'] df2['profit'] = df1['profit'] # employees year profit # c 10 2022.0 3500.0 # d 15 2023.0 4500.0 # e 20 NaN NaN # f 25 NaN NaN print(df2)
There is a partial overlap between the indexes of the two DataFrames.
# df1.index df2.index # a # b # c c # d d # e # f
The c and d indexes overlap so their values in the copied columns are not
NaN.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- ValueError: cannot reindex on an axis with duplicate labels
- AttributeError module 'pandas' has no attribute 'DataFrame'
- ModuleNotFoundError: No module named 'pandas' in Python
- FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version
- TypeError Invalid comparison between datetime64[ns] and date
- How to change the Port and Host in a Flask application
- How to replace None with NaN in Pandas DataFrame
- You are trying to merge on int64 and object columns [Fixed]
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- Object arrays cannot be loaded when allow_pickle=False
- How to clear the Terminal and Console in PyCharm
- ValueError: Columns must be same length as key [Solved]
- Get the first Row of each Group in a Pandas DataFrame
- Concatenate strings from multiple rows with Pandas GroupBy
- Pandas: Find length of longest String in DataFrame column

