Pandas: Strip whitespace from Column Headers in DataFrame
Last updated: Apr 12, 2024
Reading time·6 min

# Table of Contents
- Pandas: Strip whitespace from Column Headers in DataFrame
- Checking if each column name is a string before calling
str.strip() - Pandas: Strip whitespace from Column Headers using
df.columns - Stripping whitespace from specific columns in a DataFrame
- Stripping initial spaces when using pandas.read_csv
- Stripping whitespace from specific columns in a DataFrame using str.replace
- Stripping whitespace from a Pandas DataFrame with converters
# Pandas: Strip whitespace from Column Headers in DataFrame
To strip the whitespace from the column headers in a Pandas DataFrame:
- Use the
DataFrame.rename()method to rename the columns of theDataFrame. - Set the
columnsargument to a lambda function that calls thestr.strip()method on each column.
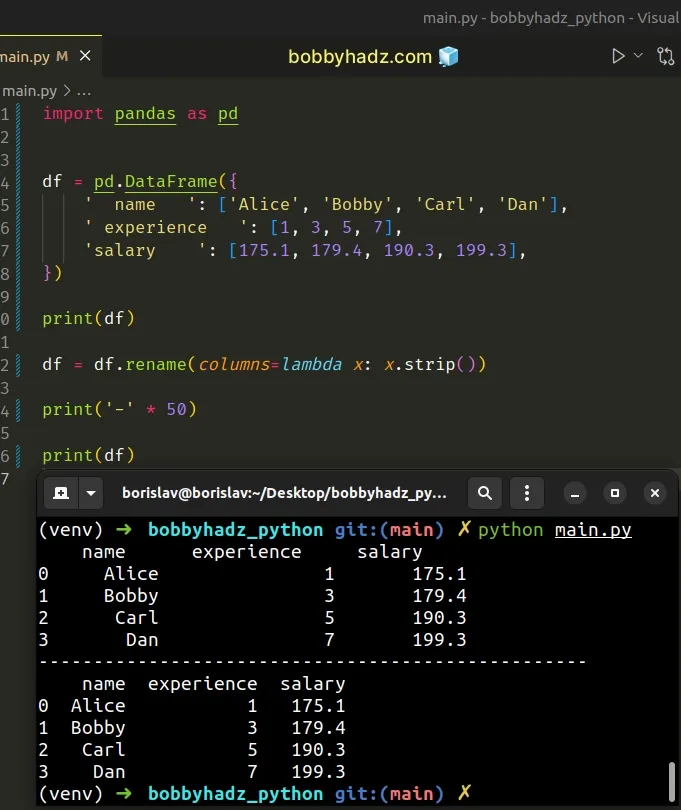
import pandas as pd df = pd.DataFrame({ ' name ': ['Alice', 'Bobby', 'Carl', 'Dan'], ' experience ': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], }) print(df) df = df.rename(columns=lambda x: x.strip()) print('-' * 50) print(df)
Running the code sample with python main.py produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 179.4 2 Carl 5 190.3 3 Dan 7 199.3 -------------------------------------------------- name experience salary 0 Alice 1 175.1 1 Bobby 3 179.4 2 Carl 5 190.3 3 Dan 7 199.3
The
DataFrame.rename()
method is used to rename the columns or index labels of a DataFrame.
The columns parameter of the method can be set to a function.
df = df.rename(columns=lambda x: x.strip())
The supplied lambda gets called with each column name and uses the str.strip() method to remove the leading and trailing whitespace.
# 👇️ 'name' print(repr(' name '.strip()))
The str.strip method returns a copy of the string with the leading and
trailing whitespace removed.
# Checking if each column name is a string before calling str.strip()
If your DataFrame column names might be of different types, you should check
if each column name is of type str before calling str.strip().
import pandas as pd df = pd.DataFrame({ ' name ': ['Alice', 'Bobby', 'Carl', 'Dan'], ' experience ': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], }) # [' name ', ' experience ', 'salary '] print(list(df.columns)) df = df.rename(columns=lambda x: x.strip() if isinstance(x, str) else x) print('-' * 50) # ['name', 'experience', 'salary'] print(list(df.columns))
We used the isinstance()
function to check if each column name is of type str.
If the condition is met, we return the result of calling str.strip() on the
column name, otherwise, we return the column name as is.
# Pandas: Strip whitespace from Column Headers using df.columns
You can also use the DataFrame.columns attribute to strip the whitespace from
the column headers in a DataFrame.
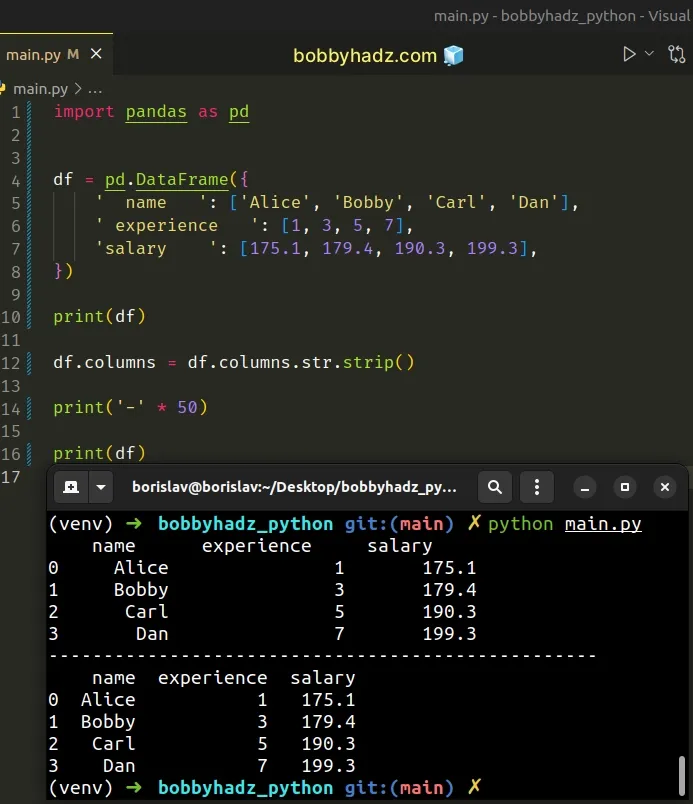
import pandas as pd df = pd.DataFrame({ ' name ': ['Alice', 'Bobby', 'Carl', 'Dan'], ' experience ': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], }) print(df) df.columns = df.columns.str.strip() print('-' * 50) print(df)
Running the code sample produces the following output.
name experience salary 0 Alice 1 175.1 1 Bobby 3 179.4 2 Carl 5 190.3 3 Dan 7 199.3 -------------------------------------------------- name experience salary 0 Alice 1 175.1 1 Bobby 3 179.4 2 Carl 5 190.3 3 Dan 7 199.3
The DataFrame.columns attribute returns the column labels of the DataFrame.
import pandas as pd df = pd.DataFrame({ ' name ': ['Alice', 'Bobby', 'Carl', 'Dan'], ' experience ': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], }) # Index([' name ', ' experience ', 'salary '], dtype='object') print(df.columns)
We called the str.strip() method on the Index object to strip the leading
and trailing whitespace from each column name.
df.columns = df.columns.str.strip()
You can use the DataFrame.columns attribute to print the columns before and
after removing the leading and trailing whitespace.
import pandas as pd df = pd.DataFrame({ ' name ': ['Alice', 'Bobby', 'Carl', 'Dan'], ' experience ': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], }) # [' name ', ' experience ', 'salary '] print(list(df.columns)) df.columns = df.columns.str.strip() print('-' * 50) # ['name', 'experience', 'salary'] print(list(df.columns))
Using this approach should be a bit faster than using the lambda function from the previous subheading, in case you need to optimize for performance.
# Stripping whitespace from specific columns in a DataFrame
You can also call the str.strip() method on a specific column to strip the
leading and trailing whitespace from the column's values.
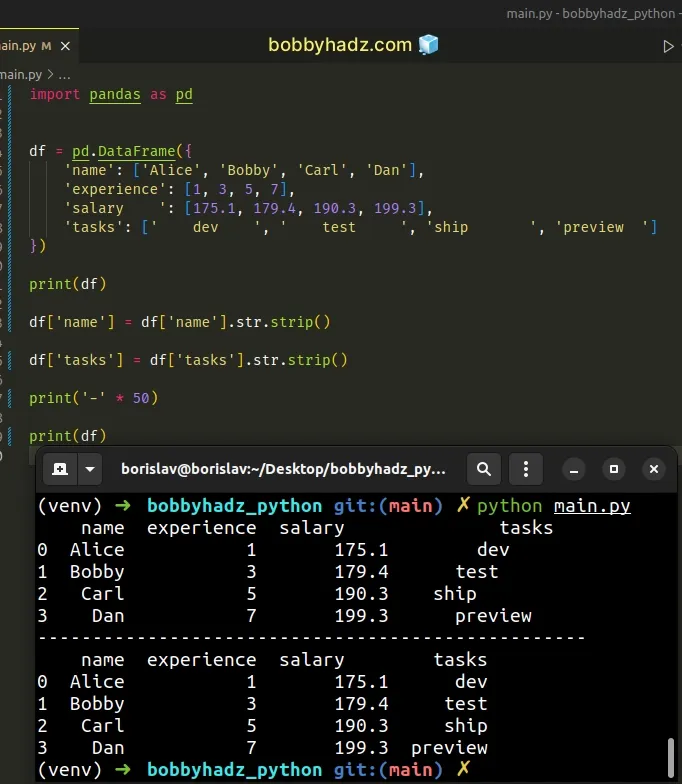
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], 'tasks': [' dev ', ' test ', 'ship ', 'preview '] }) print(df) df['name'] = df['name'].str.strip() df['tasks'] = df['tasks'].str.strip() print('-' * 50) print(df)
Running the code sample produces the following output.
name experience salary tasks 0 Alice 1 175.1 dev 1 Bobby 3 179.4 test 2 Carl 5 190.3 ship 3 Dan 7 199.3 preview -------------------------------------------------- name experience salary tasks 0 Alice 1 175.1 dev 1 Bobby 3 179.4 test 2 Carl 5 190.3 ship 3 Dan 7 199.3 preview
We used square brackets to access specific columns that contain string values
and then called the str.strip() method to strip the leading and trailing
whitespace.
Make sure the column's values are of type str, otherwise, you'd get the error:
# Stripping initial spaces when using pandas.read_csv
If you need to strip the initial spaces when using
pandas.read_csv, set the
skipinitialspace argument to True.
Suppose we have the following employees.csv file.
first_name,last_name,date Alice,Smith,2023-01-05 Bobby, Hadz,2023-03-25 Carl,Lemon, 2021-01-24
Here is how you can skip the initial spaces by setting skipinitialspace to
True.
import pandas as pd df = pd.read_csv('employees.csv', skipinitialspace=True) # first_name last_name date # 0 Alice Smith 2023-01-05 # 1 Bobby Hadz 2023-03-25 # 2 Carl Lemon 2021-01-24 print(df)
The argument makes it so the spaces after the delimiter are skipped.
# Stripping whitespace from specific columns in a DataFrame using str.replace
If you need to strip all whitespace from specific columns in a DataFrame, use
the str.replace() method.
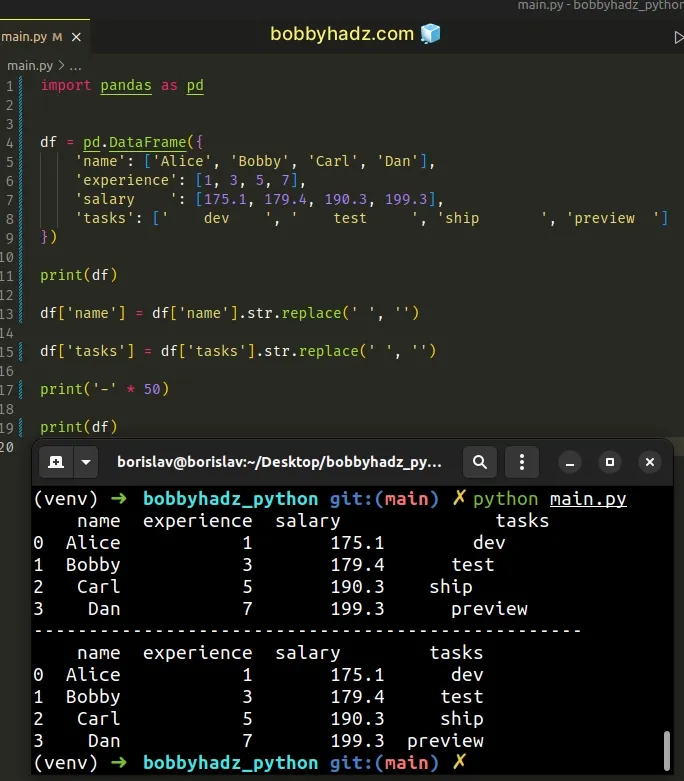
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary ': [175.1, 179.4, 190.3, 199.3], 'tasks': [' dev ', ' test ', 'ship ', 'preview '] }) print(df) df['name'] = df['name'].str.replace(' ', '') df['tasks'] = df['tasks'].str.replace(' ', '') print('-' * 50) print(df)
Running the code sample produces the following output.
name experience salary tasks 0 Alice 1 175.1 dev 1 Bobby 3 179.4 test 2 Carl 5 190.3 ship 3 Dan 7 199.3 preview -------------------------------------------------- name experience salary tasks 0 Alice 1 175.1 dev 1 Bobby 3 179.4 test 2 Carl 5 190.3 ship 3 Dan 7 199.3 preview
Note that the str.replace method
removes all spaces from the string values in the DataFrame, not just the
leading and trailing ones (as str.strip() does).
# Stripping whitespace from a Pandas DataFrame with converters
You can also use converters to strip the whitespace from the column values in a
Pandas DataFrame.
Suppose we have the following employees.csv file.
first_name,last_name,date Alice,Smith,2023-01-05 Bobby, Hadz,2023-03-25 Carl,Lemon, 2021-01-24
And here is the related main.py file.
import pandas as pd df = pd.read_csv('employees.csv', converters={ 'first_name': str.strip, 'last_name': str.strip, 'date': str.strip }) # first_name last_name date # 0 Alice Smith 2023-01-05 # 1 Bobby Hadz 2023-03-25 # 2 Carl Lemon 2021-01-24 print(df)
The converters argument can be set to a dictionary of column names pointing to
functions.
Each column name points to the str.strip() function which will remove the
leading and trailing whitespace when parsing the CSV file.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Convert a NumPy array to 0 or 1 based on threshold in Python
- How to get the length of a 2D Array in Python
- TypeError: 'numpy.ndarray' object is not callable in Python
- TypeError: Object of type ndarray is not JSON serializable
- IndexError: too many indices for array in Python [Solved]
- How to filter a JSON array in Python
- ValueError: object too deep for desired array [Solved]
- Only one element tensors can be converted to Python scalars
- Replace negative Numbers in a Pandas DataFrame with Zero
- Pandas: Sum the values in a Column that match a Condition
- Pandas: Make new Column from string Slice of another Column
- Pandas: Calculate mean (average) across multiple DataFrames
- NumPy or Pandas: How to check a Value or an Array for NaT
- Interpolating NaN values in a NumPy Array in Python
- Pandas ValueError: ('Lengths must match to compare')
- How to repeat Rows N times in a Pandas DataFrame
- How to convert a Pandas DataFrame to a Markdown Table

