Sklearn ValueError: Unknown label type: 'continuous' [Fixed]
Last updated: Apr 12, 2024
Reading time·3 min

# Table of Contents
- Sklearn ValueError: Unknown label type: 'continuous'
- Use the LabelEncoder() class to solve the error
- Solving the error by converting the Y values to integers
- Use a regression model instead of a classification model
# Sklearn ValueError: Unknown label type: 'continuous' [Fixed]
The Sklearn "ValueError: Unknown label type: 'continuous'" occurs when you
pass floating-point numbers to a classifier that expects categorical values
(e.g. 0 or 1).
Use the LabelEncoder class to encode the target labels with a value between
0 and n_classes-1 to solve the error.
Here is an example of how the error occurs.
import numpy as np from sklearn.linear_model import LogisticRegression train_X = np.array([ [100, 1.2, 3.5], [120, 1.3, 2.4], [150, 1.4, 6.8], [200, 1.1, 4.0], ]) train_Y = np.array([1.0, 2.3, 5.4, 4.8]) clf = LogisticRegression() # ⛔️ ValueError: Unknown label type: 'continuous' clf.fit(train_X, train_Y)
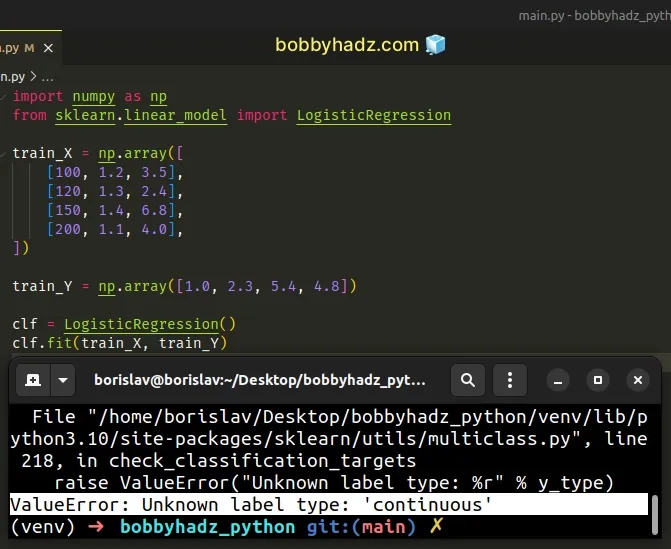
The LogisticRegression class should be used for classification and not for regression.
The train_Y variable should be a classification class containing categorical
values (e.g. 0 or 1), and not a continuous variable (one which can take on
an uncountable set of values).
# Use the LabelEncoder() class to solve the error
Use the
sklearn.preprocessing.LabelEncoder
class to encode the target labels with a value between 0 and n_classes-1 to
solve the error.
import numpy as np from sklearn import preprocessing from sklearn.linear_model import LogisticRegression train_X = np.array([ [100, 1.2, 3.5], [120, 1.3, 2.4], [150, 1.4, 6.8], [200, 1.1, 4.0], ]) train_Y = np.array([1.0, 2.3, 5.4, 4.8]) lab_enc = preprocessing.LabelEncoder() encoded_train_Y = lab_enc.fit_transform(train_Y) clf = LogisticRegression(max_iter=1000) clf.fit(train_X, encoded_train_Y)
We instantiated the LabelEncoder() class and used the fit-transform() method
to fit the label encoder and get the encoded labels.
We then passed the encoded train Y data when calling fit() on the
classifier.
# Solving the error by converting the Y values to integers
Alternatively, you can solve the error by converting the values to integers (instead of floating-point numbers).
import numpy as np from sklearn.linear_model import LogisticRegression train_X = np.array([ [100, 1.2, 3.5], [120, 1.3, 2.4], [150, 1.4, 6.8], [200, 1.1, 4.0], ]) train_Y = np.array([1.0, 2.3, 5.4, 4.8]) # 👇️ convert the values to integers train_Y = train_Y.round(0) clf = LogisticRegression(max_iter=1000) clf.fit(train_X, train_Y)
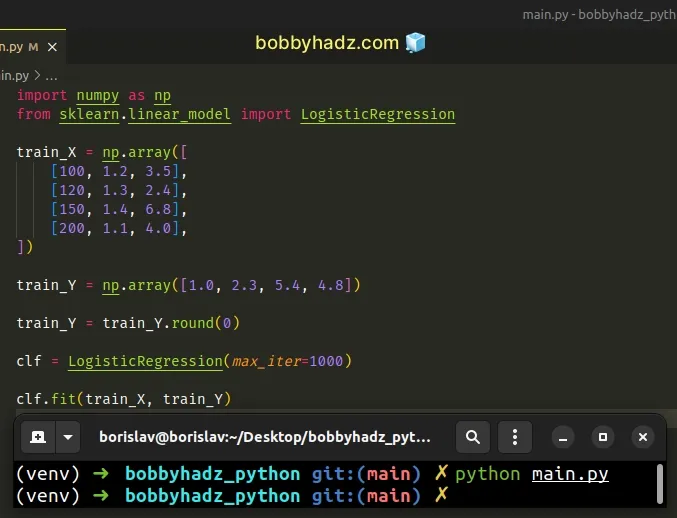
The code sample uses the
ndarray.round()
method to convert the values to integers by rounding to 0 decimal places.
The only argument we passed to the ndarray.round() method is the number of
decimal places we want to round to.
# Use a regression model instead of a classification model
You might also get the error when you use a classification model instead of a regression model by mistake.
Here is an example.
from sklearn.svm import SVC import numpy as np from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) y = np.array([1.0, 1.2, 2.3, 2.4]) clf = make_pipeline(StandardScaler(), SVC(gamma='auto')) # ⛔️ ValueError: Unknown label type: 'continuous' clf.fit(X, y)
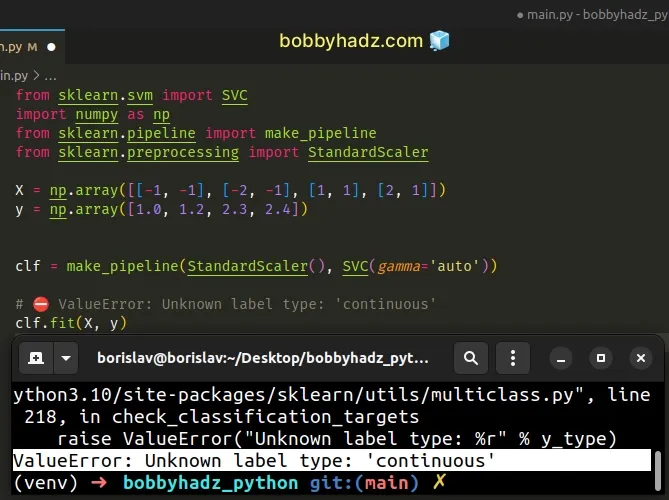
The code sample uses the sklearn.svm.SVC C-Support vector classification class.
However, classification models can only be used with categorical values (e.g.
0 and 1) and not floating-point values.
If you're working with continuous variables (ones that can take on an uncountable set of values), you should use a regression model instead.
In the example, you would use the sklearn.svm.SVR (Epsilon-Support Vector Regression) class.
from sklearn.svm import SVR import numpy as np from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) y = np.array([1.0, 1.2, 2.3, 2.4]) clf = make_pipeline(StandardScaler(), SVR(gamma='auto')) clf.fit(X, y)
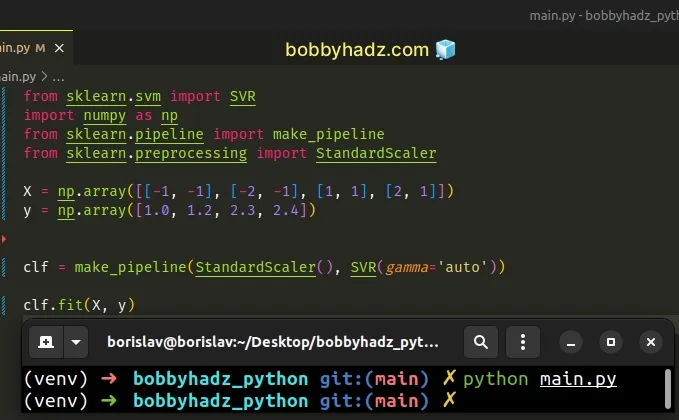
The code sample uses a regression model, so we are able to pass it continuous values without any issues.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- IndexError: too many indices for array in Python [Solved]
- How to filter a JSON array in Python
- AttributeError module 'numpy' has no attribute array or int
- NumPy RuntimeWarning: divide by zero encountered in log10
- ValueError: x and y must have same first dimension, but have shapes
- SystemError: initialization of _internal failed without raising an exception
- ModuleNotFoundError: No module named 'sklearn' in Python

