PyTorch: Trying to backward through the graph a second time
Last updated: Apr 13, 2024
Reading time·3 min

# PyTorch: Trying to backward through the graph a second time
The PyTorch error "RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed)." occurs when you try to backward through a graph more than once.
To solve the error, pass retain_graph=True when calling backward().
All calls to the backward() method but the last need to have
retain_graph=True passed as a parameter.
Here is an example of how the error occurs.
import torch in_dim, out_dim = (5, 2) inputs = torch.randn(in_dim) target = torch.tensor([1, 2], dtype=torch.float32) model = torch.nn.Linear(in_dim, out_dim, bias=True) out = model(inputs) loss = torch.nn.CrossEntropyLoss() computed_loss = loss(out, target) computed_loss.backward() # ⛔️ RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward. computed_loss.backward() for p in model.parameters(): print(p.grad)
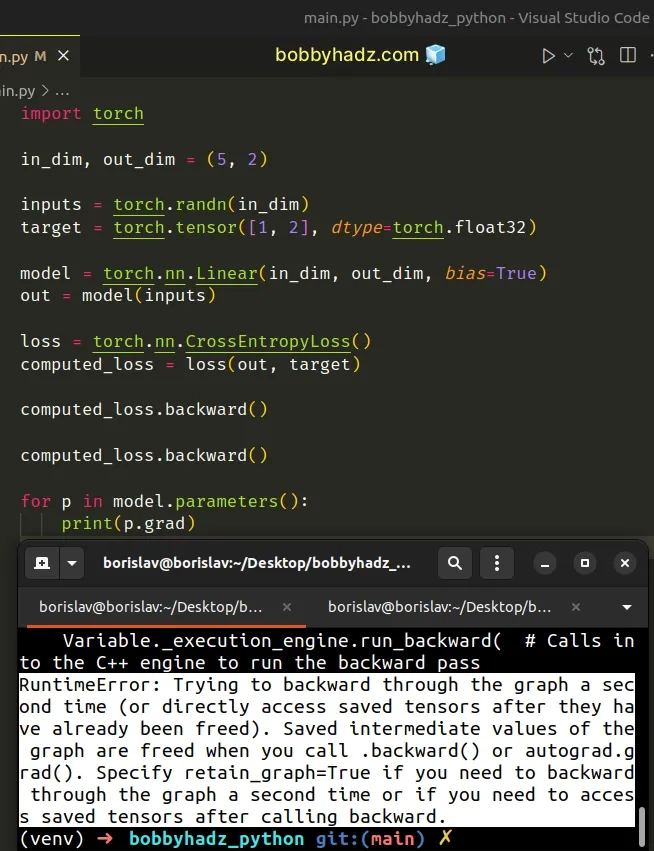
The cause of the error is that I called backward() a second time.
As stated in the error message, the saved intermediate values of the graph are
deleted when you call .backward() or autograd.grad().
When you call backward() a second time, the intermediary results don't exist
and the backward pass fails.
Intermediate values are those from the forward pass that are needed to compute the backward pass.
They are created when you perform operations that require some of the forward tensors to compute their backward pass.
# Pass retain_graph=True when calling backward
One way to solve the error is to pass retain_graph=True to the backward()
method.
All calls to the backward() method but the last need to have
retain_graph=True passed as a parameter.
import torch in_dim, out_dim = (5, 2) inputs = torch.randn(in_dim) target = torch.tensor([1, 2], dtype=torch.float32) model = torch.nn.Linear(in_dim, out_dim, bias=True) out = model(inputs) loss = torch.nn.CrossEntropyLoss() computed_loss = loss(out, target) # ✅ Pass `retain_graph=True` to the method computed_loss.backward(retain_graph=True) computed_loss.backward() for p in model.parameters(): print(p.grad)
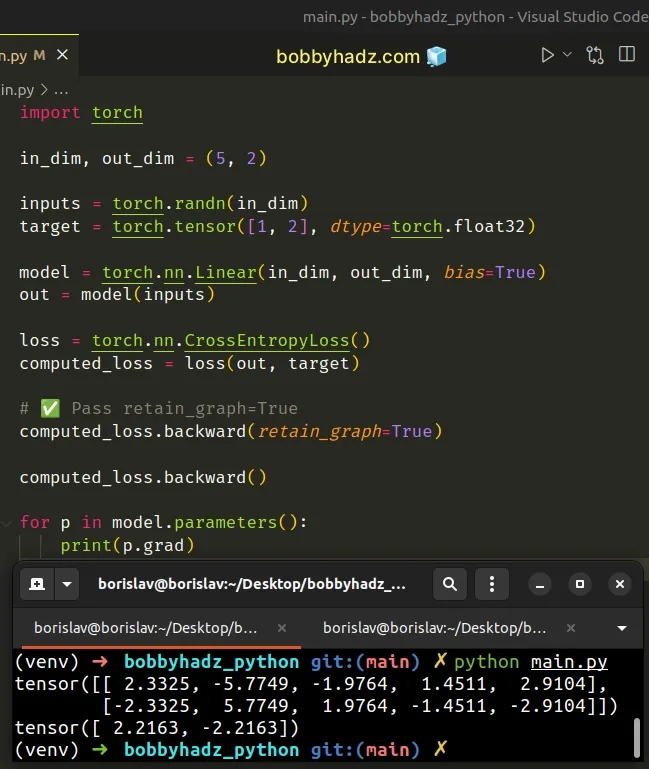
I only changed the following line.
# ✅ Pass retain_graph=True computed_loss.backward(retain_graph=True)
The retain_graph argument needs to be set to True if you need to:
- Backward through the graph a second time.
- Access saved tensors after calling backward.
Make sure to specify the argument in all calls to backward but the last.
For example, if I have 3 .backward() calls, I'd supply the argument in the
first 2.
import torch in_dim, out_dim = (5, 2) inputs = torch.randn(in_dim) target = torch.tensor([1, 2], dtype=torch.float32) model = torch.nn.Linear(in_dim, out_dim, bias=True) out = model(inputs) loss = torch.nn.CrossEntropyLoss() computed_loss = loss(out, target) # ✅ Pass retain_graph=True computed_loss.backward(retain_graph=True) # ✅ Pass retain_graph=True computed_loss.backward(retain_graph=True) computed_loss.backward() for p in model.parameters(): print(p.grad)
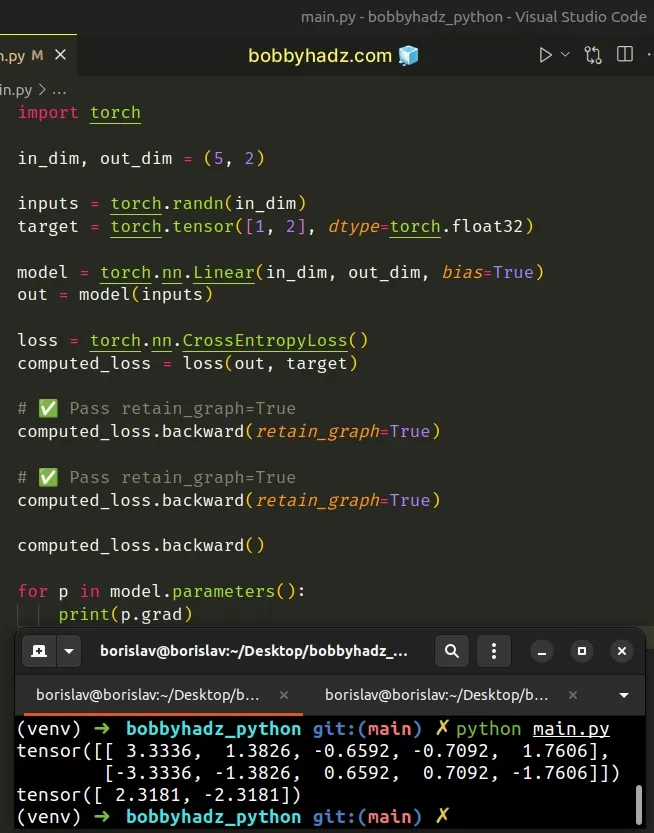
# The addition operation doesn't need a buffer
Note that the addition operator doesn't need a buffer, so setting
retain_graph=True is not necessary when calling backward() multiple times.
import torch x = torch.ones(1, 1, requires_grad=True) y = x + 1 y.backward(torch.ones(1, 1)) y.backward(torch.ones(1, 1)) print(x) print(y)
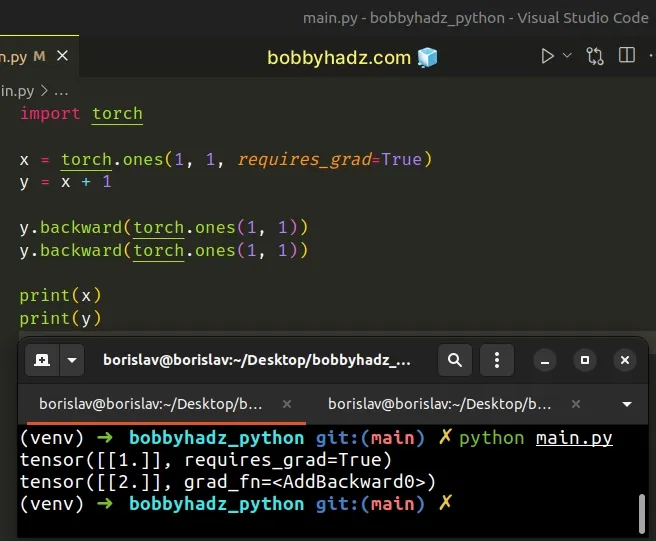
Since no buffer is required for the addition operation, no buffer is missing
when you call backward() the second time and no errors are raised.
# Solving the error when working with optimizers
If you use an optimizer, try to call optimizer.zero_grad() after
optimizer.step().
optimizer = optim.Adam(model.parameters()) loss.backward(retain_graph=True) optimizer.step() optimizer.zero_grad()
When you call the loss.backward() method, the gradients are computed and the
.grad property of the parameters gets updated.
When you call optimizer.step(), the parameters are updated using the .grad()
property.
You need to clear the gradients with optimizer.zero_grad() to call
backward() a second time.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- Pandas: Create a Tuple from two DataFrame Columns
- RuntimeError: Expected scalar type Float but found Double
- Pandas: Convert timezone-aware DateTimeIndex to naive timestamp
- RuntimeError: CUDA out of memory. Tried to allocate X MiB
- OSError: [E050] Can't find model 'en_core_web_sm'

