How to add a Filter to Pivot Table in Pandas
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- How to add a Filter to Pivot Table in Pandas
- Adding multiple filters with the logical AND & operator
- Adding multiple filters with the logical OR | operator
- Pass the filtered DataFrame in the call to pandas.pivot_table
# How to add a Filter to Pivot Table in Pandas
To add a filter to a pivot table in Pandas:
- Use bracket notation to filter the
DataFramebased on a condition. - Call the
pivot_table()method on the filteredDataFrame.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bobby', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 2, 2, 3, 3, 8], }) table = df[df['id'] > 1].pivot_table( index='id', columns=['name'], values='experience', aggfunc='mean' ) # name Bobby Carl Dan # id # 2 2.5 NaN NaN # 3 NaN 3.0 8.0 print(table)
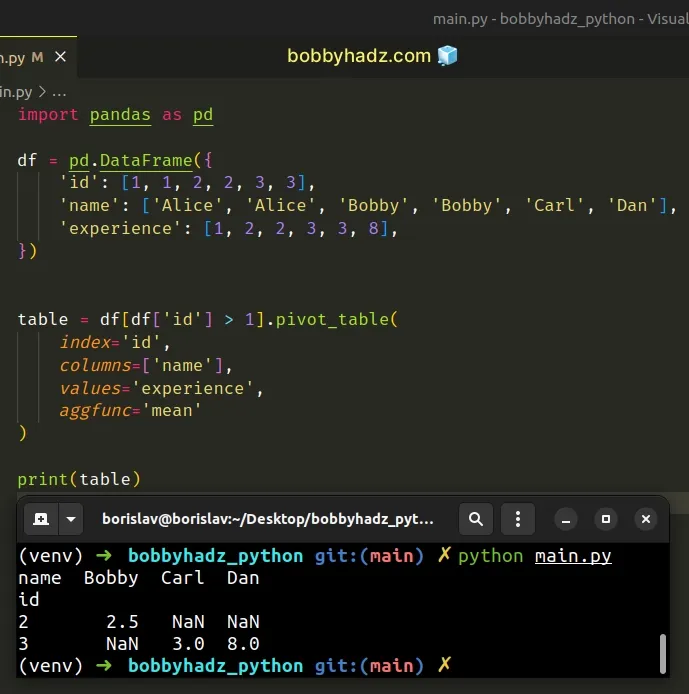
The first step is to use bracket notation to filter the DataFrame based on a
condition.
For example, the following condition only selects rows that have an id value
that is greater than 1.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bobby', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 2, 2, 3, 3, 8], }) # id name experience # 2 2 Bobby 2 # 3 2 Bobby 3 # 4 3 Carl 3 # 5 3 Dan 8 print(df[df['id'] > 1])
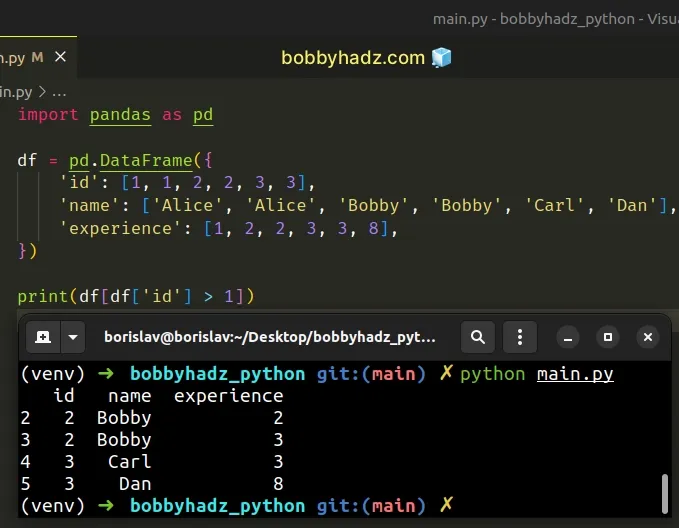
You can then call the
DataFrame.pivot_table()
method on the filtered DataFrame.
table = df[df['id'] > 1].pivot_table( index='id', columns=['name'], values='experience', aggfunc='mean' )
# Adding multiple filters with the logical AND & operator
If you need to check for multiple conditions before calling
DataFrame.pivot_table(), use the logical AND & operator.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bobby', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 2, 2, 3, 3, 8], }) table = df[(df['id'] > 1) & (df['name'] != 'Carl')].pivot_table( index='id', columns=['name'], values='experience', aggfunc='mean' ) # name Bobby Dan # id # 2 2.5 NaN # 3 NaN 8.0 print(table)
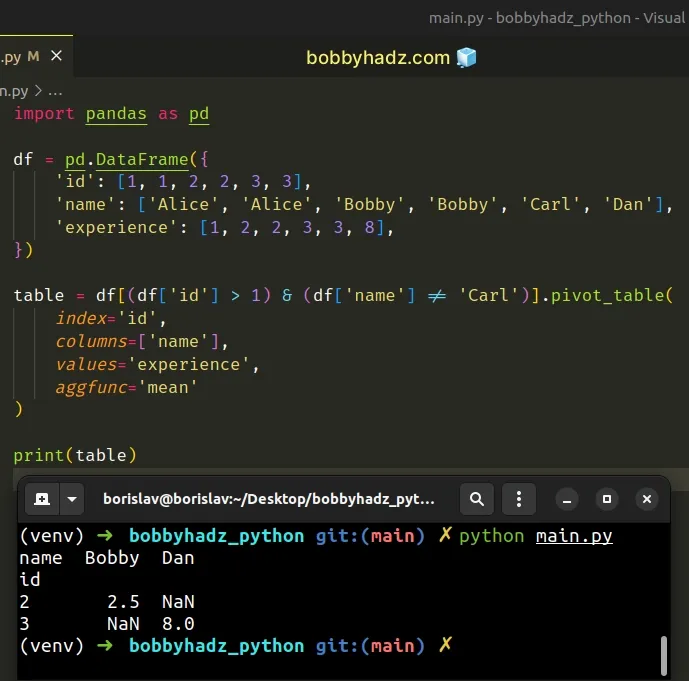
The code sample returns the rows that have:
- an
idthat is greater than1 - a
namevalue that is not equal to the string"Carl"
Both conditions have to be met for the row to be included in the resulting
DataFrame.
The last step is to call the pivot_table on the filtered DataFrame.
# Adding multiple filters with the logical OR | operator
If you need to check if at least one of multiple conditions is met before
calling pivot_table(), use the
logical OR operator.
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bobby', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 2, 2, 3, 3, 8], }) table = df[(df['id'] > 1) | (df['experience'] == 2)].pivot_table( index='id', columns=['name'], values='experience', aggfunc='mean' ) # name Alice Bobby Carl Dan # id # 1 2.0 NaN NaN NaN # 2 NaN 2.5 NaN NaN # 3 NaN NaN 3.0 8.0 print(table)
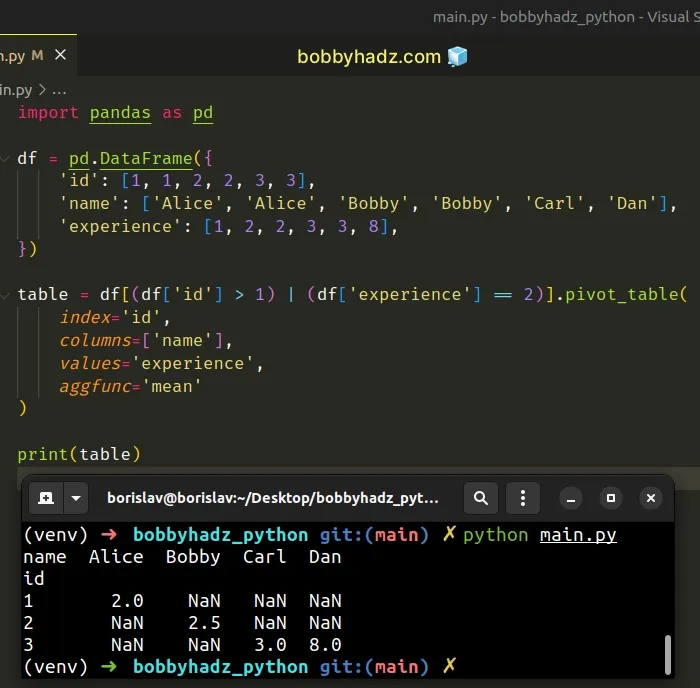
The code sample uses the logical OR | operator before calling pivot_table().
The example checks that either of these 2 conditions is met:
- The
idvalue of the row is greater than1. - The
experiencevalue of the row is equal to2.
If either condition is met, the row gets added to the resulting DataFrame on
which we call pivot_table().
# Pass the filtered DataFrame in the call to pandas.pivot_table
You can also pass the filtered DataFrame in the call to
pandas.pivot_table().
import pandas as pd df = pd.DataFrame({ 'id': [1, 1, 2, 2, 3, 3], 'name': ['Alice', 'Alice', 'Bobby', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 2, 2, 3, 3, 8], }) table = pd.pivot_table( df[df['id'] > 1], index='id', columns=['name'], values='experience', aggfunc='mean' ) # name Bobby Carl Dan # id # 2 2.5 NaN NaN # 3 NaN 3.0 8.0 print(table)
The first argument the pandas.pivot_table() method takes is the DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: Select Rows between two values in DataFrame
- Update a Pandas DataFrame while iterating over its rows
- Pandas: Convert a DataFrame to a List of Dictionaries
- Pandas: GroupBy columns with NaN (missing) values
- Panda: Using fillna() with specific columns in a DataFrame
- Pandas: Split a Column of Lists into Multiple Columns
- Pandas: How to Convert a Pivot Table to a DataFrame
- How to Split a Pandas DataFrame into Chunks
- Pandas: Get the Business Days between two Dates
- Pandas: How to Query a Column name with Spaces
- Pandas: Create Scatter plot from multiple DataFrame columns
- Annotate Bars in Barplot with Pandas and Matplotlib
- Cannot mask with non-boolean array containing NA / NaN values
- Disable the TOKENIZERS_PARALLELISM=(true | false) warning
- RuntimeError: Expected scalar type Float but found Double
- Pandas: Convert timezone-aware DateTimeIndex to naive timestamp
- RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type float)
- Cannot convert non-finite values (NA or inf) to integer
- Pandas: How to efficiently Read a Large CSV File

