Pandas ValueError: ('Lengths must match to compare') [Fix]
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- Pandas ValueError: ('Lengths must match to compare')
- Selecting a specific value before the comparison
- Checking if a DataFrame column contains a specific value
- Comparing each row in the DataFrame column with a specific value
# Pandas ValueError: ('Lengths must match to compare')
The Pandas "ValueError: ('Lengths must match to compare')" occurs when you try to compare values of a different length.
To solve the error, iterate over the DataFrame column and compare the value to each row or select a specific row before the comparison.
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) arr = ['2023-01-05'] # ⛔️ ValueError: ('Lengths must match to compare', (3,), (1,)) if df['date'] == arr: print('success')
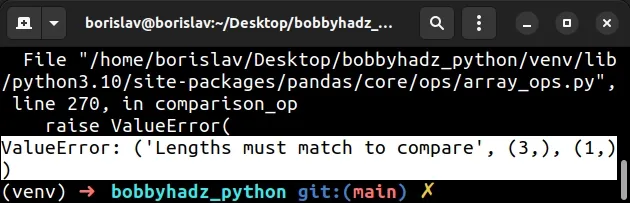
We selected the date column and tried to compare it to a list containing a
single date string.
We are trying to compare a Series that contains 3 elements to a list that
contains 1 element.
# Selecting a specific value before the comparison
If you need to select a specific value before the comparison, use the DataFrame.iloc indexer.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) arr = ['2023-01-05'] print(df.iloc[0]['date']) # 👉️ "2023-01-05" if df.iloc[0]['date'] == arr[0]: # 👇️ this runs print('success') else: print('failure')
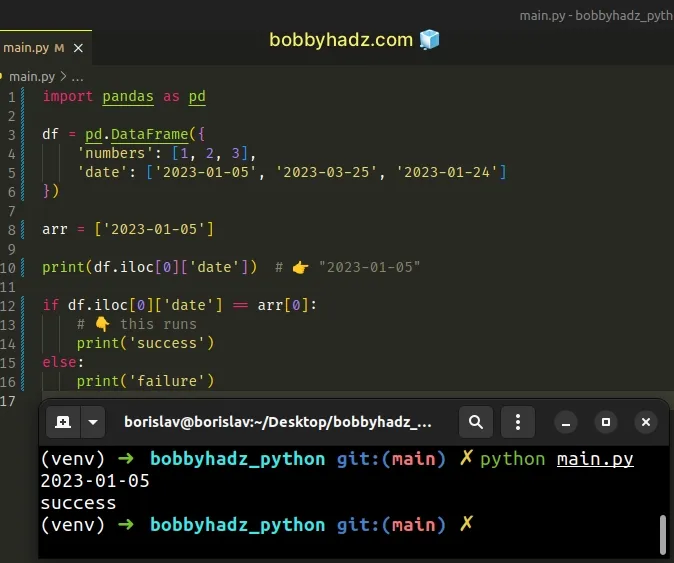
The DataFrame.iloc attribute is used for integer location-based indexing for selection by position.
The attribute takes an integer position from 0 to length - 1 because
Python indices are zero-based.
We end up comparing two strings in the example, so everything works as expected.
We compared the first row of the date column to the first element of the arr
list.
# Checking if a DataFrame column contains a specific value
If you need to check if a DataFrame column contains a specific value, use the
in operator.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' if date in df['date'].values: # 👇️ this runs print('success') else: print('failure')
The
Series.values
attribute returns an ndarray containing the values of the Series.
We used the in operator to check if the given string is contained in the
Series.
If you forget to access the values attribute on the Series, you would be
checking if the value is in the index.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' # 0 2023-01-05 # 1 2023-03-25 # 2 2023-01-24 # Name: date, dtype: object print(df['date']) print('-' * 50) print(date in df['date']) # 👉️ False print('-' * 50) print(0 in df['date']) # 👉️ True
Running the code sample returns the following output.
0 2023-01-05 1 2023-03-25 2 2023-01-24 Name: date, dtype: object -------------------------------------------------- False -------------------------------------------------- True
You can also use the tolist() method to convert the Series to a list
before the comparison.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' if date in df['date'].tolist(): # 👇️ this runs print('success') else: print('failure')
You can also use the
Series.any()
method to check if the Series contains a specific value.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' if (df['date'] == date).any(): # 👇️ this runs print('success') else: print('failure')
The any() method returns False unless there is at least one element in the
Series (or along a DataFrame axis) that is True or equivalent.
You can also use the
Series.isin()
method along with any().
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' if df['date'].isin([date]).any(): # 👇️ this runs print('success') else: print('failure')
The isin() method takes a list-like object of values and checks if the
elements in the Series are contained in the supplied list.
The method returns a boolean Series that shows whether each element in the
original Series matches an element in the supplied sequence.
# Comparing each row in the DataFrame column with a specific value
If you need to compare each row in the DataFrame column with a specific value,
use the Series.apply() method.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' # 0 True # 1 False # 2 False # Name: date, dtype: bool print(df['date'].apply(lambda x: x == date))
The function we passed to the apply() method gets called with each row and
compares the value to the given date string.
If you need to get the matching row, use the str.contains() method.
import pandas as pd df = pd.DataFrame({ 'numbers': [1, 2, 3], 'date': ['2023-01-05', '2023-03-25', '2023-01-24'] }) date = '2023-01-05' match = df[df['date'].str.contains(date)] # numbers date # 0 1 2023-01-05 print(match) print('-' * 50) # numbers 1 # date 1 # dtype: int64 print(match.count())
The count()
method returns a Series that counts the non-NA cells for each column or row.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Pandas: Make new Column from string Slice of another Column
- Interpolating NaN values in a NumPy Array in Python
- How to check if a NumPy Array is multidimensional or 1D
- Numpy: How to extract a Submatrix from an array
- Reading specific columns from an Excel File in Pandas
- Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of X
- Calculate the Average for each Row in a Pandas DataFrame
- How to drop all Rows in a Pandas DataFrame in Python
- Pandas: Drop columns if Name contains a given String
- Pandas: Convert GroupBy results to Dictionary of Lists
- Reduction operation 'argmax' not allowed for this dtype
- Pandas SpecificationError: nested renamer is not supported
- Cannot perform 'rand_' with a dtyped [int64] array and scalar of type [bool]

