AttributeError: Can only use .str accessor with string values
Last updated: Apr 11, 2024
Reading time·5 min

# AttributeError: Can only use .str accessor with string values
The NumPy "AttributeError: Can only use .str accessor with string values"
occurs when you try to use the .str accessor on values that are not of type
string.
To solve the error, use the astype() method to convert the values to strings
before using the .str accessor.
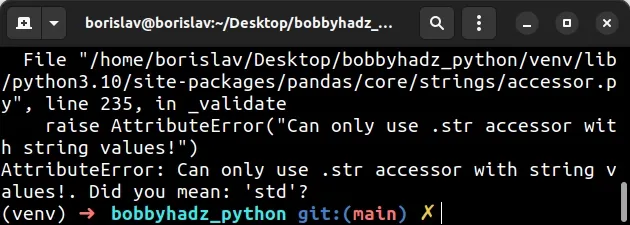
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df['salary'].str.replace('.', ',') # ⛔️ AttributeError: Can only use .str accessor with string values!. Did you mean: 'std'? print(df)
We accessed the salary column in the DataFrame and then tried to access the
.str
accessor.
As the error message suggests, the .str attribute can only be accessed with
string values.
The salary column contains floating-point values which caused the error.
# Make sure that you are accessing the correct column
The first thing you should do is to ensure you are accessing the correct column.
For example, if I try to access the .str attribute on the name column, it is
allowed because the values in the column are strings.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) # 0 Alice # 1 Tom # 2 Carl # 3 Dan # Name: name, dtype: object print(df['name'].str.replace('Bobby', 'Tom'))
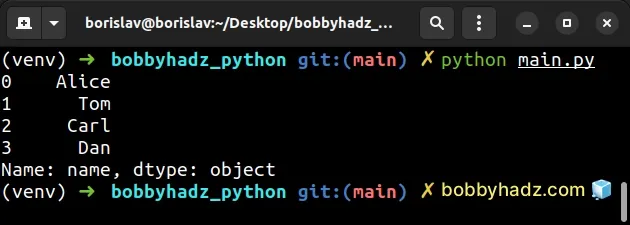
We accessed the str attribute on the values in the name column and used the
DataFrame.replace
method to replace the string Bobby with the string Tom.
You can also assign the result to the name column.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df['name'] = df['name'].str.replace('Bobby', 'Tom') # name experience salary # 0 Alice 1 175.1 # 1 Tom 3 180.2 # 2 Carl 5 190.3 # 3 Dan 7 205.4 print(df)
The code sample updates the values in the name column with the result of
calling replace().
# Convert the values in the column to strings before accessing .str
If you meant to access the .str attribute on a column that contains non-string
values:
- Use the DataFrame.astype method to convert the values to strings.
- Access the
.strattribute on the string values.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) # 0 175,1 # 1 180,2 # 2 190,3 # 3 205,4 # Name: salary, dtype: object print(df['salary'].astype(str).str.replace('.', ','))
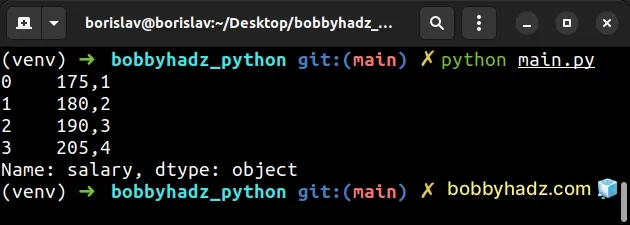
We used the DataFrame.astype method to cast the values in the salary column
to strings.
The only argument we passed to the astype() method is the
dtype.
We can safely access the .str attribute after the values have been converted
to strings.
You can also update the values in the column with the result of calling
replace().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df['salary'] = df['salary'].astype(str).str.replace('.', ',') # name experience salary # 0 Alice 1 175,1 # 1 Bobby 3 180,2 # 2 Carl 5 190,3 # 3 Dan 7 205,4 print(df)
We updated the values in the salary column with the result of calling
DataFrame.replace().
We passed the following 2 arguments to the DataFrame.replace() method:
to_replace- the values we want to replace.value- the replacement value.
# Using the apply() method to resolve the error
You can also resolve the error by calling the DataFrame.apply() method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df['salary'] = df['salary'].apply(str).str.replace('.', ',') # name experience salary # 0 Alice 1 175,1 # 1 Bobby 3 180,2 # 2 Carl 5 190,3 # 3 Dan 7 205,4 print(df)
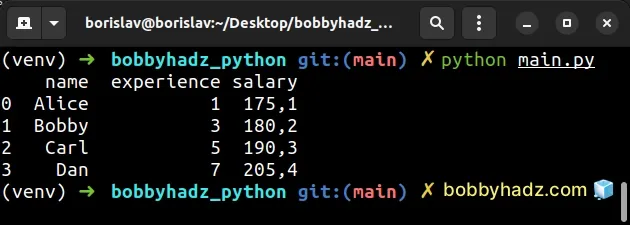
The
DataFrame.apply()
method applies a function along an axis of the DataFrame.
We passed the str class to the
apply() method to convert each value in the salary column to a string.
After converting all values in the column to strings, we can safely access the
.str attribute.
You can also pass a lambda function to the apply() method.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, 180.2, 190.3, 205.4], }) df['salary'] = df['salary'].apply(lambda x: str(x).replace('.', ',')) # name experience salary # 0 Alice 1 175,1 # 1 Bobby 3 180,2 # 2 Carl 5 190,3 # 3 Dan 7 205,4 print(df)
The lambda function gets called with each floating-point number from the
salary column.
We used the str() class to convert each floating-point number to a string and
called the replace() method on each string.
# Only calling replace() if the value is a string
You can also solve the error by checking if the value is a string before calling
replace().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, '179,4', 190.3, '199,3'], }) def replace_values(value): if isinstance(value, str): return value.replace(',', '.') return value df['salary'] = df['salary'].apply(replace_values) # name experience salary # 0 Alice 1 175.1 # 1 Bobby 3 179.4 # 2 Carl 5 190.3 # 3 Dan 7 199.3 print(df)
- The
replace_valuesfunction gets called with each value from thesalarycolumn. - The function uses the isinstance method to check if the given value is a string.
- If the condition is met, we use the
replace()method to replace each comma with a period. - Otherwise, the value is returned as is.
The same can be achieved using an inline lambda function.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': [1, 3, 5, 7], 'salary': [175.1, '179,4', 190.3, '199,3'], }) df['salary'] = df['salary'].apply( lambda x: x.replace(',', '.') if isinstance(x, str) else x ) # name experience salary # 0 Alice 1 175.1 # 1 Bobby 3 179.4 # 2 Carl 5 190.3 # 3 Dan 7 199.3 print(df)
The lambda function in the example does the same.
It only calls the replace() method if the supplied value is a string.
Otherwise, the value is returned as is.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Convert a NumPy array to 0 or 1 based on threshold in Python
- How to get the length of a 2D Array in Python
- TypeError: 'numpy.ndarray' object is not callable in Python
- TypeError: Object of type ndarray is not JSON serializable
- IndexError: too many indices for array in Python [Solved]
- How to filter a JSON array in Python
- ValueError: object too deep for desired array [Solved]
- Only one element tensors can be converted to Python scalars
- Copy a column from one DataFrame to another in Pandas
- ValueError: cannot reindex on an axis with duplicate labels
- ValueError: Length mismatch: Expected axis has X elements, new values have Y elements
- Pandas: Strip whitespace from Column Headers in DataFrame

