Input contains infinity or value too large for dtype(float64)
Last updated: Apr 11, 2024
Reading time·4 min

# Input contains infinity or value too large for dtype(float64)
The article addresses the following 2 related errors:
- ValueError: Input X contains infinity or a value too large for dtype('float64').
- ValueError: Input X contains NaN.
The Python "ValueError: Input X contains infinity or a value too large for dtype('float64')" occurs when your matrix contains infinite or NaN values.
To solve the error, remove the infinite and NaN values from your matrix before the computation.
Here is an example of how the error occurs.
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression # Contains inf and nan data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) X = df[['A', 'B']] y = df['C'] model = LinearRegression() # ⛔️ ValueError: Input X contains infinity or a value too large for dtype('float64'). model.fit(X, y)
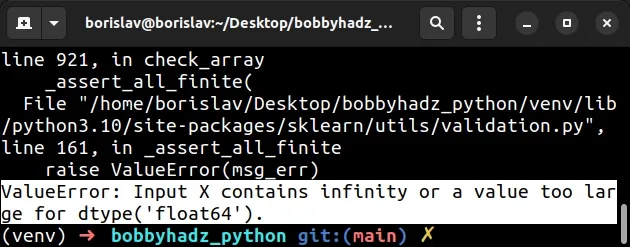
Notice that the DataFrame contains inf (infinite) and NaN (not a number)
values.
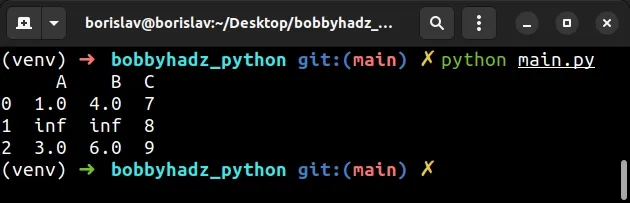
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression # Contains inf and nan data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) # A B C # 0 1.0 4.0 7 # 1 inf NaN 8 # 2 3.0 6.0 9 print(df)
We have to remove the infinite and NaN values from the DataFrame before
calling the fit() method.
You can check if your DataFrame contains NaN or inf values by using 2
methods:
- numpy.isnan -
test for
NaNelement-wise. - numpy.isfinite - test for finiteness.
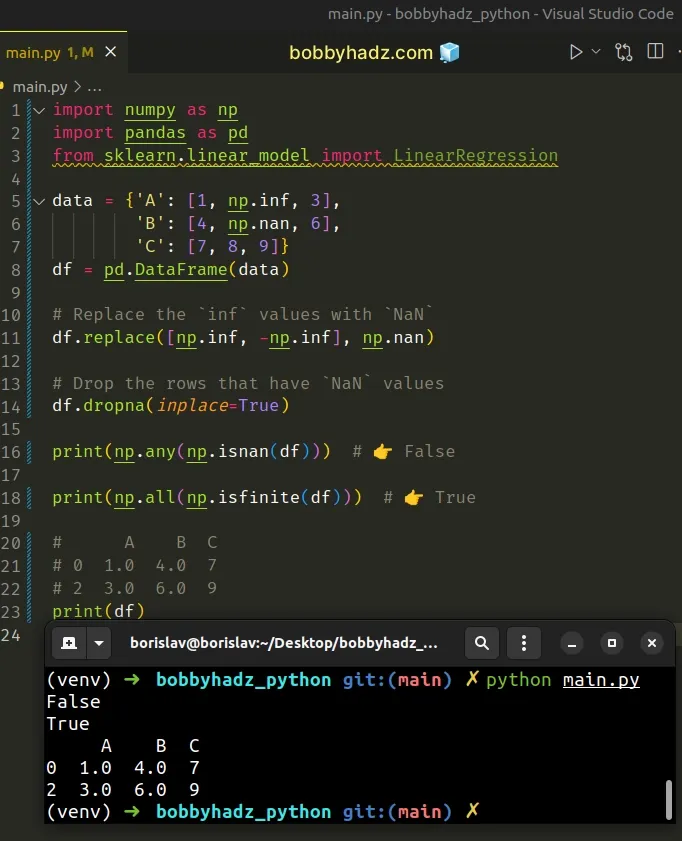
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression # Contains inf and nan data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) print(np.any(np.isnan(df))) # 👉️ True print(np.all(np.isfinite(df))) # 👉️ False
The np.any(np.isnan(df)) method call will return True if the DataFrame
contains at least one NaN value.
The np.all(np.isfinite(df)) method call will return False if the DataFrame
contains at least one inf value.
# Remove the NaN and inf values from the DataFrame to solve the error
You can solve the error by removing the NaN and inf values from the
DataFrame.
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) # Replace the `inf` values with `NaN` df.replace([np.inf, -np.inf], np.nan) # Drop the rows that have `NaN` values df.dropna(inplace=True) print(np.any(np.isnan(df))) # 👉️ False print(np.all(np.isfinite(df))) # 👉️ True # A B C # 0 1.0 4.0 7 # 2 3.0 6.0 9 print(df)
I used the following 2 lines to remove the inf and NaN values from the
DataFrame.
# Replace the `inf` values with `NaN` df.replace([np.inf, -np.inf], np.nan) # Drop the rows that have `NaN` values df.dropna(inplace=True)
The call to the replace() method replaces inf values with NaN.
The call to the dropna() method drops the rows that have NaN values.
As the following code sample shows, the DataFrame no longer contains any inf
or NaN values.
print(np.any(np.isnan(df))) # 👉️ False print(np.all(np.isfinite(df))) # 👉️ True # A B C # 0 1.0 4.0 7 # 2 3.0 6.0 9 print(df)
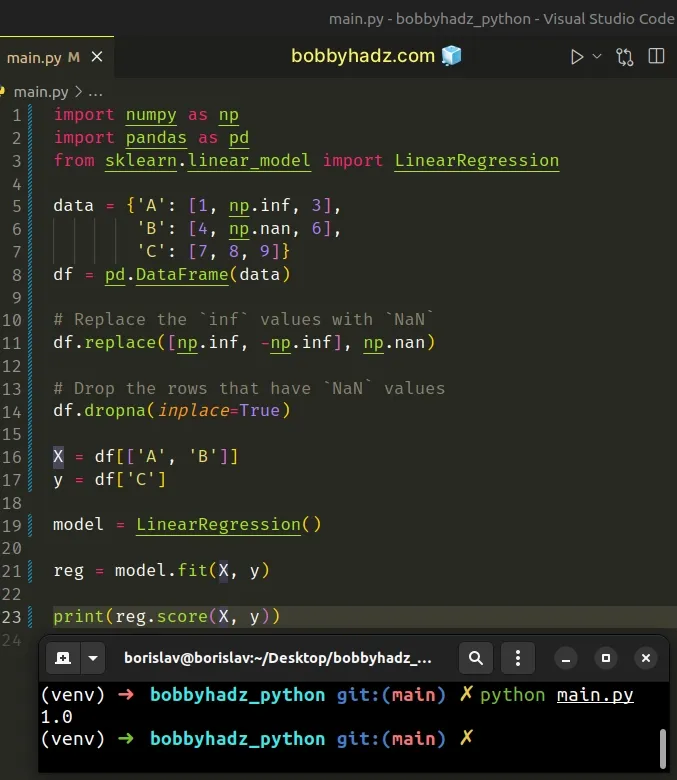
Here is a complete example that demonstrates that the error has been resolved.
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) # Replace the `inf` values with `NaN` df.replace([np.inf, -np.inf], np.nan) # Drop the rows that have `NaN` values df.dropna(inplace=True) X = df[['A', 'B']] y = df['C'] model = LinearRegression() reg = model.fit(X, y) print(reg.score(X, y)) # 👉️ 1.0
You can also define a reusable function that removes the inf and NaN values
from a DataFrame.
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) def remove_inf_nan(df): # Replace the `inf` values with `NaN` df.replace([np.inf, -np.inf], np.nan) # Drop the rows that have `NaN` values df.dropna(inplace=True) return df df = remove_inf_nan(df) print(np.any(np.isnan(df))) # 👉️ False print(np.all(np.isfinite(df))) # 👉️ True # A B C # 0 1.0 4.0 7 # 2 3.0 6.0 9 print(df)
The remove_inf_nan function takes a DataFrame as a parameter, removes the
inf and NaN values and returns the result.
# Replacing the inf and NaN values
If you instead want to replace the inf and NaN values, use the
DataFrame.fillna()
method.
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression data = {'A': [1, np.inf, 3], 'B': [4, np.nan, 6], 'C': [7, 8, 9]} df = pd.DataFrame(data) # Replace the `inf` values with `NaN` df.replace([np.inf, -np.inf], np.nan, inplace=True) # 👇️ Replace `NaN` values with 555 df.fillna(555, inplace=True) print(np.any(np.isnan(df))) # 👉️ False print(np.all(np.isfinite(df))) # 👉️ True # A B C # 0 1.0 4.0 7 # 1 555.0 555.0 8 # 2 3.0 6.0 9 print(df)
We used the DataFrame.replace() method to replace the inf values with NaN.
We then used the DataFrame.fillna() method to replace the NaN values with
the number 555.
The fillna() method fills NA/NaN values.
# Try to reset the index of your DataFrame
If the error persists, try to reset the index of your DataFrame before the
computation.
df = df.reset_index()
The DataFrame.reset_index
method resets the index of the given DataFrame or a level of it.
This often resolves the error if it was caused by removing entries from your
DataFrame.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Could not broadcast input array from shape into shape [Fix]
- ValueError: object too deep for desired array [Solved]
- Only one element tensors can be converted to Python scalars
- Copy a column from one DataFrame to another in Pandas
- How to use numpy.argsort in Descending order in Python
- Object arrays cannot be loaded when allow_pickle=False
- TypeError: cannot pickle '_thread.lock' object [Solved]
- ufunc 'add' did not contain loop with signature matching types
- ValueError: Found array with dim 3. Estimator expected 2
- ValueError: columns overlap but no suffix specified [Solved]
- Usecols do not match columns, columns expected but not found
- Converting a Nested Dictionary to a Pandas DataFrame
- Convert column Values to Columns in a Pandas DataFrame
- How to Multiply two or more Columns in Pandas
- Add columns of a different Length to a DataFrame in Pandas
- Mixing dicts with non-Series may lead to ambiguous ordering

