Skip the header of a file with CSV Reader in Python
Last updated: Apr 11, 2024
Reading time·4 min

# Table of Contents
- Skip the header of a file with CSV Reader in Python
- Skip the header of a file with CSV Reader when using open() directly
- Skip the header of a file with CSV Reader using
islice() - Skip the header of a file with CSV Reader using
DictReader
# Skip the header of a file with CSV Reader in Python
To skip the header of a file with CSV reader in Python:
- Open the
csvfile inr(reading) mode. - Use the
csv.reader()method to get an iterator of the file's contents. - Use the
next(csv_reader)method to skip the header of the file.
Here is the employees.csv file for the examples.
first_name,last_name,date Alice,Smith,01/21/1995 14:32:44.042010 Bobby,Hadz,04/14/1998 12:51:42.014000 Carl,Lemon,06/11/1994 15:52:43.016000
And here is the code for the main.py file.
import csv with open('employees.csv', 'r', encoding='utf-8') as csv_file: csv_reader = csv.reader(csv_file, delimiter=',') next(csv_reader) for row in csv_reader: print(row)
Running the code produces the following output.
['Alice', 'Smith', '01/21/1995 14:32:44.042010'] ['Bobby', 'Hadz', '04/14/1998 12:51:42.014000'] ['Carl', 'Lemon', '06/11/1994 15:52:43.016000']
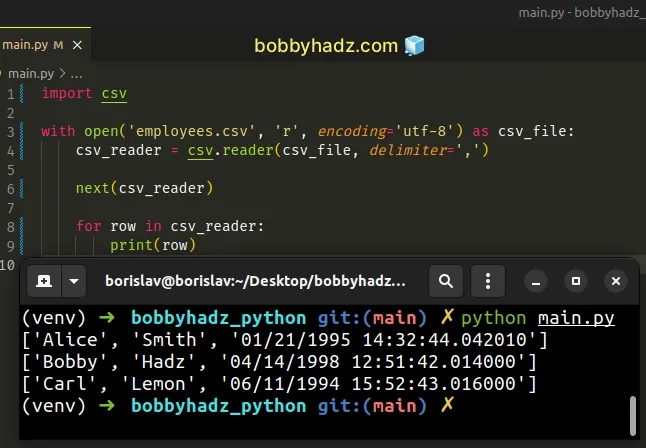
We opened the csv file in r (reading) mode.
The csv.reader() method returns a reader object that iterates over the lines in the CSV file.
To be more precise, the method returns an iterator of lists where each list contains the fields of the given row.
The first item in the list is the header.
You can use the next() function to skip the headers.
next(csv_reader)
The next() function returns the next item from the provided iterator.
The function can be passed a default value as the second argument.
If the iterator is exhausted or empty, the default value is returned.
StopIteration exception is raised.You can set the default value to None if you want to avoid getting an error if
the CSV file is empty.
import csv with open('employees.csv', 'r', encoding='utf-8') as csv_file: csv_reader = csv.reader(csv_file, delimiter=',') next(csv_reader, None) # ['Alice', 'Smith', '01/21/1995 14:32:44.042010'] # ['Bobby', 'Hadz', '04/14/1998 12:51:42.014000'] # ['Carl', 'Lemon', '06/11/1994 15:52:43.016000'] for row in csv_reader: print(row)
You can then use a for loop to iterate over the iterator.
# ['Alice', 'Smith', '01/21/1995 14:32:44.042010'] # ['Bobby', 'Hadz', '04/14/1998 12:51:42.014000'] # ['Carl', 'Lemon', '06/11/1994 15:52:43.016000'] for row in csv_reader: print(row)
# Skip the header of a file with CSV Reader when using open() directly
The example from the previous subheading uses the with open statement to automatically close the CSV file once we're done.
However, you can also use the open() function directly.
import csv csv_file = open('employees.csv', 'r', encoding='utf-8') csv_reader = csv.reader(csv_file, delimiter=',') next(csv_reader, None) # ['Alice', 'Smith', '01/21/1995 14:32:44.042010'] # ['Bobby', 'Hadz', '04/14/1998 12:51:42.014000'] # ['Carl', 'Lemon', '06/11/1994 15:52:43.016000'] for row in csv_reader: print(row) csv_file.close()
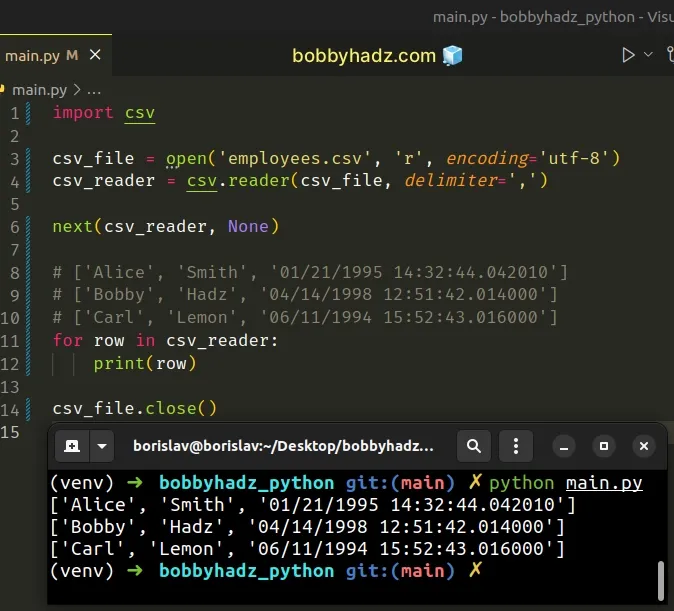
It is recommended to use the with open() statement because it takes care of
automatically closing the file even if an error occurs.
However, if you decide to use the open() function directly, make sure to
close the CSV file.
csv_file.close()
If you don't close the CSV file when using open() directly, you'll get a
memory leak.
# Skip the header of a file with CSV Reader using islice()
You can also use the itertools.islice() method to skip the header of a file with CSV reader.
The example uses the same employees.csv file.
first_name,last_name,date Alice,Smith,01/21/1995 14:32:44.042010 Bobby,Hadz,04/14/1998 12:51:42.014000 Carl,Lemon,06/11/1994 15:52:43.016000
Here is the related Python code.
import csv from itertools import islice with open('employees.csv', 'r', encoding='utf-8') as csv_file: csv_reader = csv.reader(csv_file, delimiter=',') for row in islice(csv_reader, 1, None): # ['Alice', 'Smith', '01/21/1995 14:32:44.042010'] # ['Bobby', 'Hadz', '04/14/1998 12:51:42.014000'] # ['Carl', 'Lemon', '06/11/1994 15:52:43.016000'] print(row)
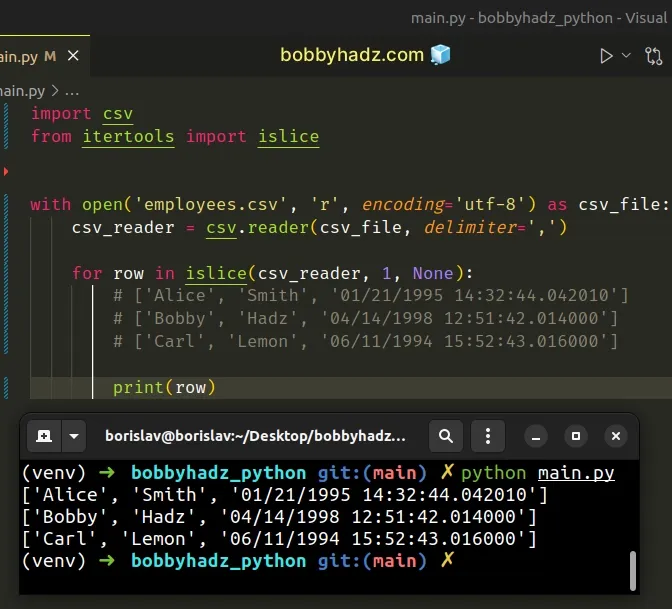
We used the itertools.islice() method instead of using next().
The itertools.islice class
takes an iterator and optional start, stop and step values.
The second argument we passed to the islice() class is the index of the first
element to be included in the slice.
The third argument is the index of the first element to be excluded from the slice.
We used a value of None because we didn't want to exclude any elements from
the slice.
# Skip the header of a file with CSV Reader using DictReader
You can also use the csv.DictReader class to skip the header of a file.
import csv with open('employees.csv', 'r', encoding='utf-8') as csv_file: dict_reader = csv.DictReader(csv_file, delimiter=',') for row in dict_reader: print(row['first_name'], row['last_name'], row['date'])
Running the script with python main.py produces the following output.
Alice Smith 01/21/1995 14:32:44.042010 Bobby Hadz 04/14/1998 12:51:42.014000 Carl Lemon 06/11/1994 15:52:43.016000
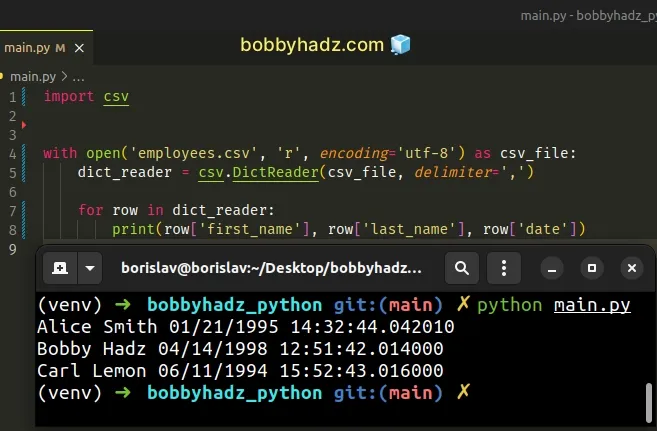
The csv.DictReader class creates an object that operates like a regular reader but it maps the contents of each row in a dictionary.
Note that you have to omit the fieldnames parameter when instantiating
DictReader.
If the fieldnames parameter is omitted, the values in the first row are used
as the field names.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- _csv.Error: iterator should return strings, not bytes [Fix]
- csv.Error: line contains NULL byte Python error [Solved]
- Module 'csv' has no attribute 'reader' or 'writer' in Python
- How to escape commas in a CSV File [with Examples]
- Module 'lib' has no attribute 'X509_V_FLAG_CB_ISSUER_CHECK'
- How to open an HTML file in the Browser using Python
- Python: Get the Type, File and Line Number of Exception
- Python: Check if a File path is symlink (symbolic link)
- Pandas: Setting column names when reading a CSV file
- Export a Pandas DataFrame to Excel without the Index
- Pandas: Set number of max Rows and Cols shown in DataFrame
- Remove __pycache__ folders and .pyc files in Python Project
- SyntaxError: future feature annotations is not defined
- How to Copy Files and Rename them in Python [4 Ways]
- Python: Not all parameters were used in the SQL statement
- Run multiple Python files concurrently / one after the other

