csv.Error: line contains NULL byte Python error [Solved]
Last updated: Apr 11, 2024
Reading time·3 min

# Table of Contents
- csv.Error: line contains NULL byte Python error
- Creating a new file that doesn't contain NULL bytes
- Try using the
utf-16encoding when opening the file - Skipping the rows with NULL Bytes
# csv.Error: line contains NULL byte Python error [Solved]
The Python "csv.Error: line contains NULL byte" occurs when your .csv file
contains a NULL byte which commonly occurs when the file is saved with an
incorrect encoding.
To solve the error, remove the NULL bytes from the .csv file.
You can use the following if statement to check if your file contains NULL
bytes.
if '\0' in open('employees.csv', newline='', encoding='utf-8').read(): print('Your input file contains NULL bytes') else: print('Your input file does NOT contain NULL bytes')
The code sample assumes that you have an employees.csv file in the same
directory as your main.py script.
first_name,last_name,date Alice,Smith,01/21/1995 14:32:44.042010 Bobby,Hadz,04/14/1998 12:51:42.014000
The if block will run if your file contains NULL bytes.
To solve the error, try to remove the NULL bytes from the file.
For example, the following code sample:
# 🔴 Before import csv with open('employees.csv', newline='', encoding='utf-8') as csvfile: csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row)
Becomes the following code sample:
# ✅ After import csv with open('employees.csv', newline='', encoding='utf-8') as csvfile: csv_reader = csv.reader( (row.replace('\0', '') for row in csvfile), delimiter=',' ) for row in csv_reader: print(row)
If the error persists, try to also remove the \x00 characters.
import csv with open('employees.csv', newline='', encoding='utf-8') as csvfile: csv_reader = csv.reader( (row.replace('\0', '').replace('\x00', '') for row in csvfile), delimiter=',' ) for row in csv_reader: print(row)
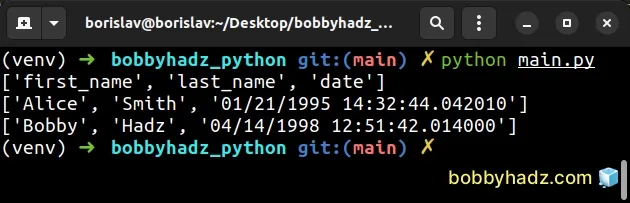
The str.replace() method returns a copy of the string with all occurrences of a substring replaced by the provided replacement.
The method takes the following parameters:
| Name | Description |
|---|---|
| old | The substring we want to replace in the string |
| new | The replacement for each occurrence of old |
| count | Only the first count occurrences are replaced (optional) |
We used the method to remove all \0 and \x00 characters from the file.
# Creating a new file that doesn't contain NULL bytes
Alternatively, you can create a new file that doesn't contain NULL bytes.
csv_file = open('employees.csv', 'rb') data = csv_file.read().decode(encoding='utf-8') csv_file.close() # ✅ Create a new file without NULL bytes output_csv_file = open('new-employees.csv', 'wb') output_csv_file.write( bytes(data.replace('\0', '').replace('\x00', ''), encoding='utf-8') ) output_csv_file.close()
We first open the file in rb (read binary) mode.
The next step is to read the file's contents and decode them to a Python string with the bytes.decode() method.
We then create a new .csv file and open it in wb (write binary) mode.
Once we remove all NULL bytes from the file, we write output to the file.
You would then use the new-employees.csv file and not the older
employees.csv file that contains NULL bytes.
# Try using the utf-16 encoding when opening the file
You have to make sure to open the file with the same encoding in which it was saved.
Some commonly used encodings are utf-8, utf-16, utf-16-le, utf-16-be.
Here is an example of opening a file with the utf-16 encoding.
import csv import codecs with codecs.open('employees.csv', 'rb', encoding='utf-16') as csvfile: csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row)
Notice that the encoding keyword argument is set to utf-16.
This will only work if the file is encoded using the utf-16 encoding.
If you get an error, try using the utf-16-le, utf-16-be and utf-8
encodings.
# Skipping the rows with NULL Bytes
Alternatively, you can skip the rows that contain NULL bytes.
import csv with open('employees.csv', newline='', encoding='utf-8') as csvfile: csv_reader = csv.reader( csvfile, delimiter=',' ) while True: try: row = next(csv_reader) print(row) except csv.Error: continue except StopIteration: break
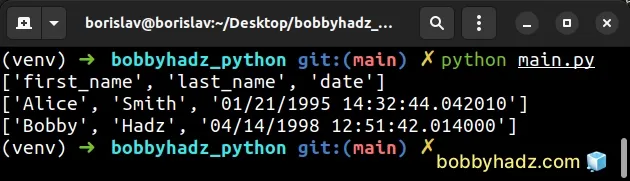
We used a while True loop to iterate over the rows in the CSV file.
On each iteration, we try to access the current row.
If a csv.Error exception is raised, we continue to the next iteration and skip
the current row.
After the last row, a StopIteration exception is raised and is then handled by
the except block.
Once a StopIteration is raised, we use the
break statement to exit the while True
loop.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Module 'csv' has no attribute 'reader' or 'writer' in Python
- How to escape commas in a CSV File [with Examples]
- Module 'lib' has no attribute 'X509_V_FLAG_CB_ISSUER_CHECK'
- _csv.Error: iterator should return strings, not bytes [Fix]
- Skip the header of a file with CSV Reader in Python
- How to read a CSV file from a URL using Python
- Python: Compare two CSV files and print the differences

