_csv.Error: iterator should return strings, not bytes [Fix]
Last updated: Apr 11, 2024
Reading time·3 min

# _csv.Error: iterator should return strings, not bytes [Fix]
The Python error "_csv.Error: iterator should return strings, not bytes (the file should be opened in text mode)" occurs when you try to open a CSV file in binary mode.
To solve the error, open the file in text mode by setting the mode to rt
instead.
Here is an example of how the error occurs.
import csv # ⛔️ _csv.Error: iterator should return strings, not bytes (the file should be opened in text mode) with open('employees.csv', 'rb') as csvfile: csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row)
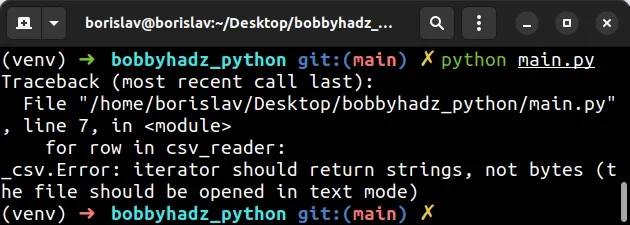
Notice that we've set the mode parameter to rb (read binary).
This caused the error because the file should be opened in text mode.
You can set the second parameter (the mode) to rt to solve the error.
import csv with open('employees.csv', 'rt', encoding='utf-8') as csvfile: csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row)
The code sample assumes that you have an employees.csv file in the same
directory as your main.py file.
first_name,last_name,date Alice,Smith,01/21/1995 14:32:44.042010 Bobby,Hadz,04/14/1998 12:51:42.014000
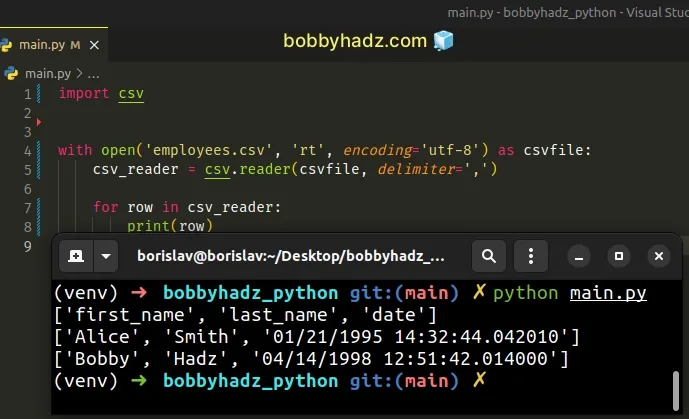
Notice that the second parameter we passed to the open() function is rt
(read text) instead of rb (read bytes).
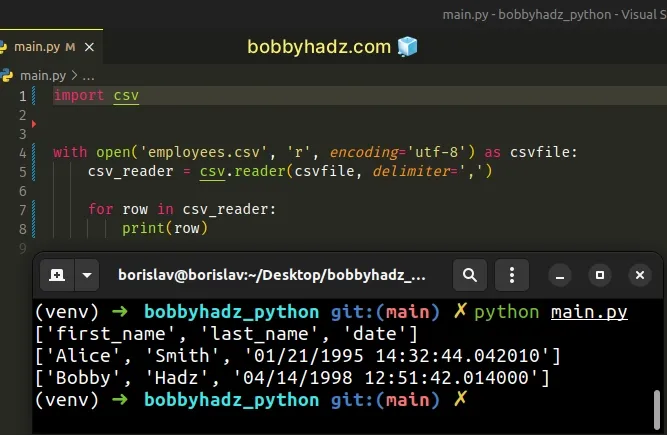
You can also set the mode parameter to r and it will default to rt (read
text).
import csv # 👇️ setting mode parameter to `r` with open('employees.csv', 'r', encoding='utf-8') as csvfile: csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row)
If you omit the mode parameter, it will also default to r.
import csv with open('employees.csv', encoding='utf-8') as csvfile: csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row)
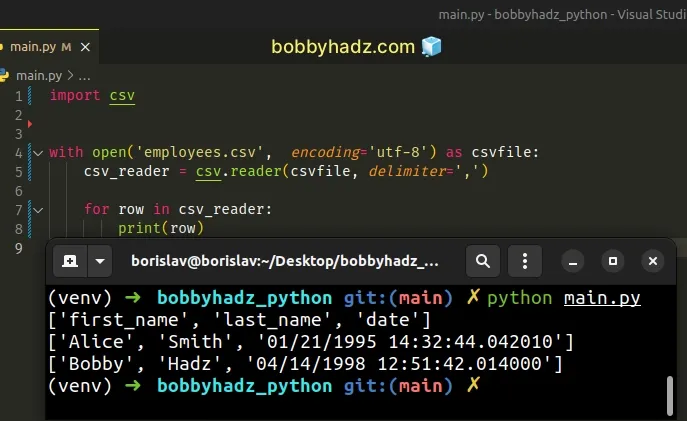
The code sample above achieves the same result as the previous two.
# Solving the error when using the open() function directly
The code sample above uses the with open() statement.
This should be your preferred approach as the with statement automatically
closes the file even if an error occurs.
However, the same approach can be used if you call the open() function
directly.
import csv csvfile = open('employees.csv', 'rt', encoding='utf-8') csv_reader = csv.reader(csvfile, delimiter=',') for row in csv_reader: print(row) csvfile.close()
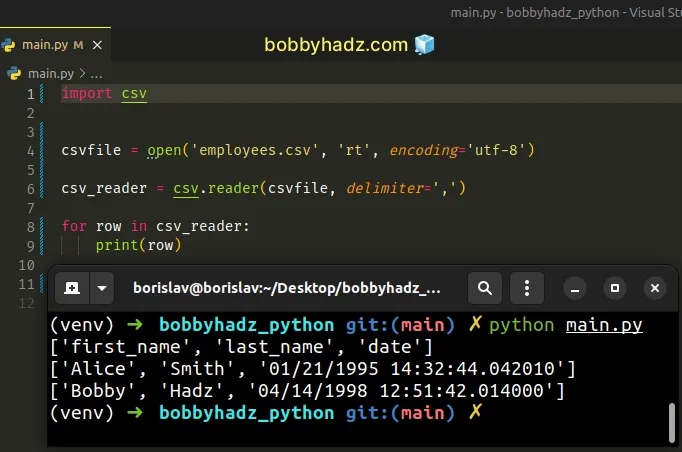
The code sample is very similar to the previous one.
However, this time we used the open() function directly.
Notice that we have to call the file.close() method after we're done.
Don't forget to call the close() method, otherwise, you'd get a memory leak.
# Solving the error by using the codecs module
You can also use the codecs module to solve the error.
Suppose that you have the following employees.csv file.
first_name,last_name,date Alice,Smith,01/21/1995 14:32:44.042010 Bobby,Hadz,04/14/1998 12:51:42.014000
Here is how you can get around the error by using codecs.iterdecode().
import csv import codecs with open('employees.csv', 'rb') as csvfile: csv_reader = csv.reader( codecs.iterdecode( csvfile, encoding='utf-8' ), delimiter=',' ) for row in csv_reader: print(row)
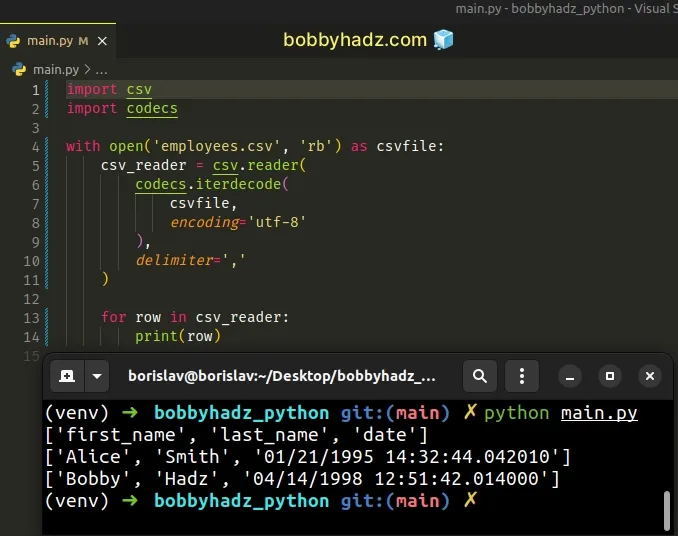
The codecs.iterdecode() method uses an incremental decoder to iteratively decode the supplied iterator.
The second argument the method takes is the encoding (utf-8 in the example).
Notice that we opened the csv file in rb (read binary) mode.
We then decode the file using codecs.iterdecode() and read it row by row.
If you get the error "ValueError: binary mode doesn't take an encoding
argument", remove the encoding argument when calling open.
The encoding argument should not be set when the file is opened in binary
mode.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Write a List of Tuples to a File in Python
- Write a String to a File on a New Line every time in Python
- How to save user input to a File in Python
- Remove the Extension from a Filename in Python
- Taking a file path from user input in Python
- How to Read a file character by character in Python
- Read a file until a specific Character in Python
- ValueError: I/O operation on closed file in Python [Solved]
- Create a file name using Variables in Python
- csv.Error: line contains NULL byte Python error [Solved]
- Module 'csv' has no attribute 'reader' or 'writer' in Python
- How to escape commas in a CSV File [with Examples]
- Skip the header of a file with CSV Reader in Python
- Python: Compare two CSV files and print the differences
- Pandas: Set number of max Rows and Cols shown in DataFrame

